How to run SQL queries over Kafka in seconds? With PySpark, we get a system where we can run ad-hoc analysis locally and any SQL queries to explore our data quickly.

17 sept. 2023

PySpark is a Python interface to write Apache Spark applications to use it in command line. The Apache Spark platform is built to crunch big datasets in a distributed way.
Combining PySpark with Kafka, we get a system that can process real-time data from Kafka in seconds using PySpark commands. Running ad-hoc analysis locally and various SQL queries to explore our data quickly is particularly useful.
Let's see how to:
Get started with PySpark and Kafka
Do filtering and transformations using SQL in pyspark
Do filtering and SQL transformations with Conduktor
Finish with some madness using OpenAI/ChatGPT to generate random JSON into Kafka!
Fasten your seatbelt, we're going to explore a lot of things!
Install PySpark
If you're running on macOS, use Homebrew to install PySpark. Check Apache Spark website for other systems or installation methods.
This will install a ton of things! Spark is a big project, with many components and relies on the JVM and the Scala programming language at its core. We're only interested in the pyspark component here, which is the Python CLI for Spark.
pyspark should be available in your terminal (open a new one otherwise):
Wonderful, it works! We have a local Spark instance running, powered by Python, with a local Spark UI available at http://localhost:4040. We'll do some fancy things with this UI later in this article, feel free to explore.
Let's familiarize ourselves with the pyspark API first by doing some basic operations, like creating a dataset and printing its schema:
A DataFrame (
dffor short) is a Spark concept. It's like a table in a spreadsheet. It has rows and columns, and each column has a name. Each row is a record that contains data for each column. For example, in a table storing information about books, a row could contain data about a single book: its title, author, and price.
In our test above, we created a DataFrame with 3 rows and 2 unnamed columns.
Just like you can sort, filter, or perform calculations on a table in a spreadsheet program, you can do similar operations on a DataFrame in a programming environment. The main difference is that DataFrames are designed to handle large (millions, billions) volumes of data efficiently, even data that won't fit into your computer's memory.
That's exactly why Kafka and Spark are a great match! 🚀
Using Spark to read data from Kafka
We can connect our pyspark to Kafka to read data.
First, we need a Kafka! If we don't have one already running, we can use Upstash to have a free Kafka cluster in the cloud. Conduktor will be used to create topics and produce data, and pyspark to do some transformations.
Follow this guide to get your free Kafka cluster up and running in a few minutes: Getting Started with Conduktor and Upstash.
If you don't have installed Conduktor yet, install it and add the configuration of your Upstash cluster.
Then we create a topic "hello" and produce some data into it using our Kafka UI:
All good from a Kafka and Conduktor perspective. Let's go back to Spark.
We start pyspark with the Kafka dependency to be able to read from Kafka:
Then, we use pyspark to read from our topic "hello" for 10 seconds. In the code below, replace the XXX with our own credentials from Upstash for the kafka.sasl.jaas.config property. ⚠️
Notice the important
"startingOffsets": "earliest"option: it tells Spark to start from the beginning of the topic, and not from the end (which is the default behavior).
Copy this whole block into pyspark (don't forget to update with your own credentials):
We should see the following output in pyspark, while we produce data in the topic hello using Conduktor:
The connection works! Now, let's explore transformations (mappings, filters, etc.) using JSON (structured data, easier to work with) using pyspark and Kafka.
Tips: Spark UI to see active queries
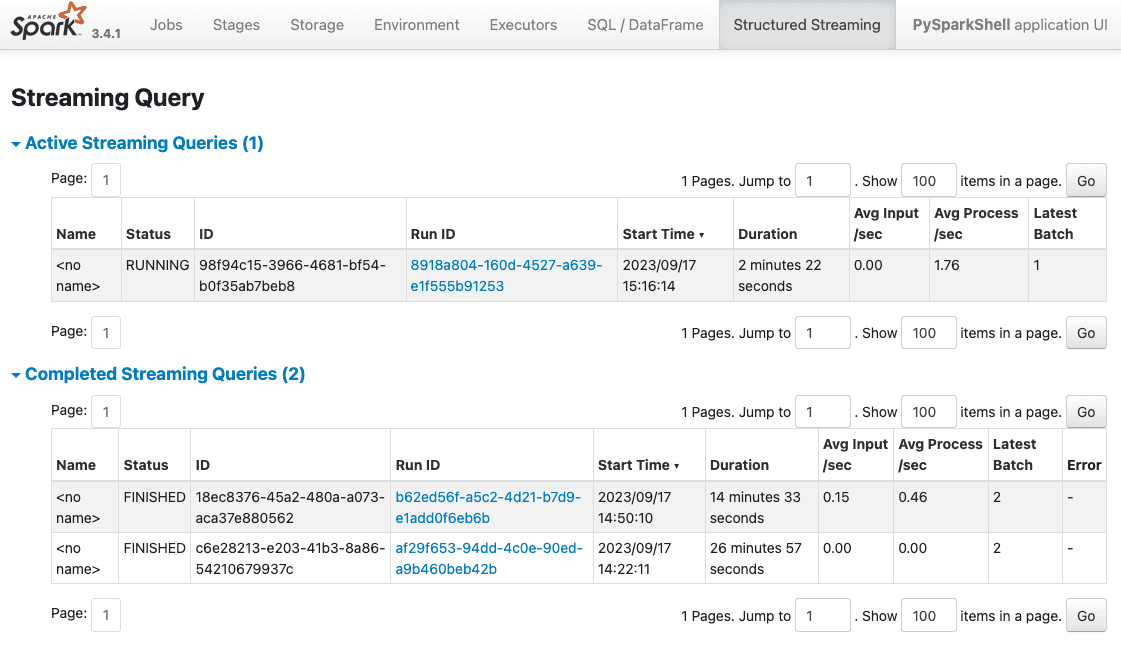
As working in a shell might be painful (we start streaming queries reading from Kafka and forget to .stop() them) to know what is running and what is not, we can use the Spark UI anytime to see the active queries and their status:
Example http://localhost:4040/StreamingQuery/:
Transforming JSON from Kafka with SQL
We're going the Netflix way and will work with JSON representing "view events", like:
We will produce JSON data (the view events) into Kafka using Conduktor, and read it using pyspark. At the same time, we'll transform the incoming data SQL as it's the ubiquitous language to work with structured data.
Produce the JSON above in our topic `hello' then execute the following code:
You should see the data from Kafka properly parsed into a struct:
Let's do some SQL on it now. We need to give a name to the temporary SQL view Spark is going to create from our DataFrame and use (we cannot use the name of the variable otherwise we'll run into a TABLE_OR_VIEW_NOT_FOUND error because it is not known from in the SQL context).
We execute this to create a temporary SQL view named netflix_view and display the average ratings by content:
Each time we're going to produce data into our topic, we'll see the average ratings by content updated in real-time:
Let's say we produce this into our Kafka topic:
Spark will display the update:
Thanks to pyspark and Kafka, we have the power to run any SQL query on our data, and see the results updated in real-time in our terminal. Glorious!
Let's take a detour and explore alternatives using Conduktor to do SQL without Spark or without any 3rd party stream processing platform actually.
Faster: Use Console Kafka UI to do filtering
If we want to filter only fields (no GROUP BY), there is no need for pyspark, as Console is a powerful Kafka UI that provides various filtering mechanisms to filter data from Kafka.
Example below: we filter only the messages where rating > 4. We can add as many filters as we want, pretty cool and faster than writing a program.
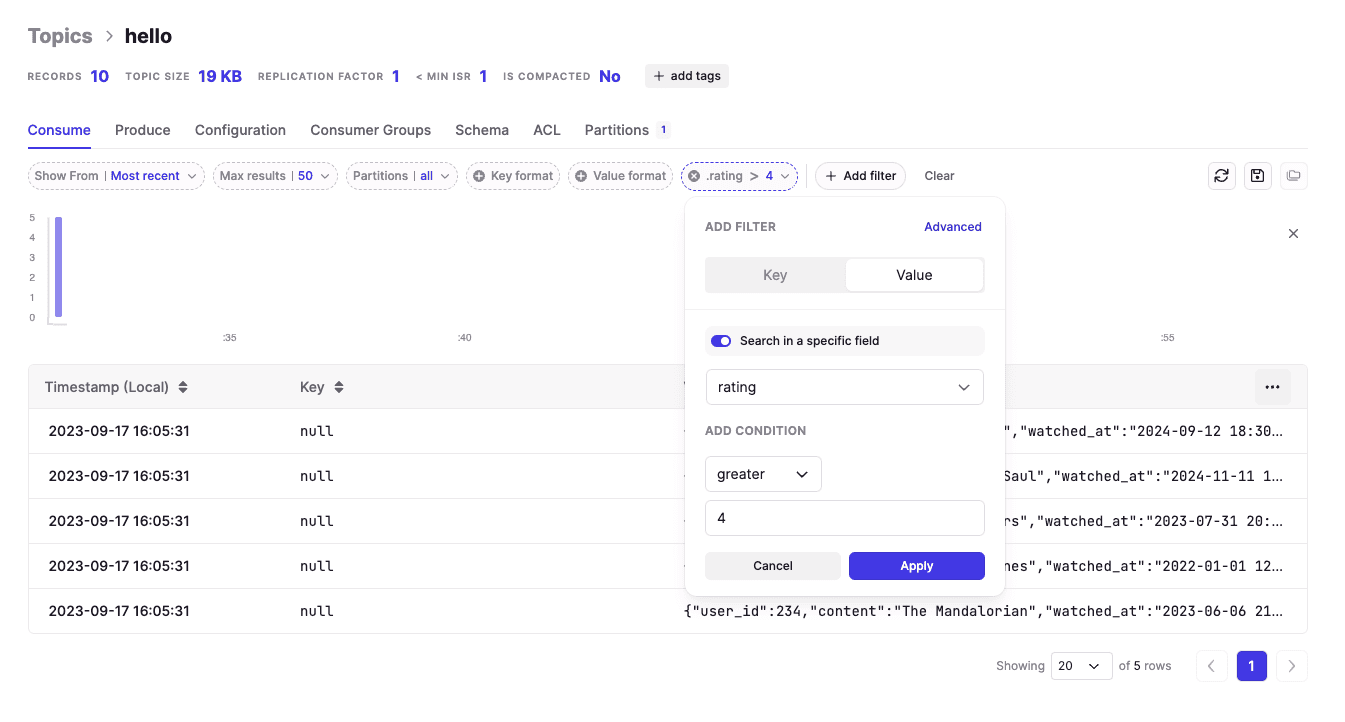
Smarter: create VIEW over a topic (advanced)
If you're familiar with Conduktor Gateway, we can create a Virtual SQL Topic, a persistent SQL view over a topic. This is an alternative to Spark and Flink. There is no code to write, no stream processing framework to manage. It's totally seamless and costs absolutely $0 as everything is in memory and processed at runtime!
If you have deployed Conduktor Gateway, you can connect to it on Console and add the SQL Topic interceptor with your SQL query:
Using this, all users now have access to a topic named good_ratings (built from your SQL query). It's totally seamless that it's a virtual topic for all your users: it's not materialized (no storage, no partitions), but it acts like a normal topic. You can use it with kafka-console-consumer, Spring, etc.
A classic use-case we see it to hide the original topic
my_netflix_topicto all users, and only expose a subset, likegood_ratingshere.It's a great way to hide sensitive data, or to expose only the data you want to expose. You can also change the SQL query on-the-fly, without any consumer to be aware of it (if you want to refine your WHERE condition for instance).
Generating JSON with AI (advanced)
Ready to go mad and explore more options? Let's use OpenAI (ChatGPT) and Google to do some crazy stuff! This is an optional part as it is more advanced. Feel free to skip it if you're not interested.
We need an OpenAI account and a Google Cloud account. Register to both if not done yet.
When it's done, we need to:
Create an API key on OpenAPI
create a Search Engine on Google Cloud to get a Search Engine ID (ChatGPT uses Google to search for answers)
Enable the Custom Search API on our Google Cloud project (to avoid errors "Custom Search API has not been used in project xxx before or it is disabled")
Then export the following environment variables to make them available to pyspark (you have to quit pyspark (Ctrl+C), add these exports to your shell, and restart pyspark):
We'll use pyspark-ai to work with OpenAI from pyspark.
If you have a paying OpenAPI subscription with access to ChatGPT-4, use this (default):
If you don't have access to GPT4 ("The model gpt-4 does not exist or you do not have access to it"), use ChatGPT3.5 instead. For this, we use langchain to provide a specific model to SparkAI:
The list of the available models are here: https://platform.openai.com/account/rate-limits, there are many models!
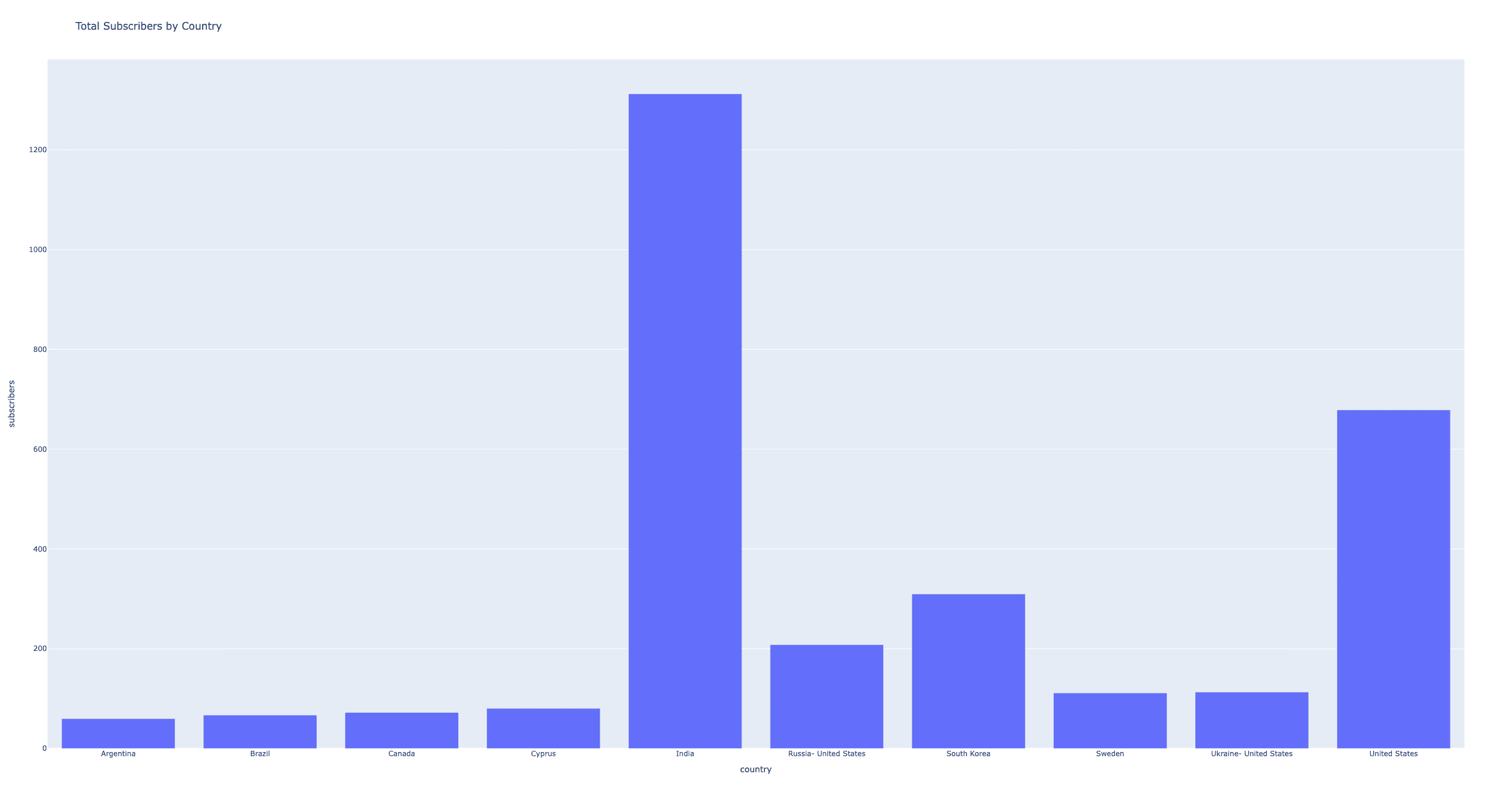
After the activation, we can use spark_ai to use the AI power. Let's start by creating a DataFrame from Wikipedia about the most subscribed Youtube channels:
This will output the data properly extracted from Wikipedia:
We are in 2023, right? Thanks to the advent of AI, we now have a user-friendly, natural language query system to manipulate data:
Behind the scene, it's building a pyspark program (typically with SQL) to answer our queries, this is impressive.
If you're not using GPT-4, you might run into this error, because the dataset of the query is too big to be handled by GPT-3.5:
openai.error.InvalidRequestError: This model's maximum context length is 4097 tokens. However, your messages resulted in 7337 tokens. Please reduce the length of the messages.
Another amazing thing is to ask a question to be plotted, and it will understand what we expect, build a pyspark program to make it happen, and open our browser for us:
Using AI to generate JSON into Kafka
Now that we understand how AI could help us, let's use it to generate random JSON based on our model.
We use directly ChatOpenAI to ask it to generate similar payloads from our model:
It takes a few seconds until ChatGPT understands and generates spot-on content:
We will use this to produce data into Kafka:
Each time we execute a new ChatGPT generation that we send into Kafka, we should see updated results in our pyspark terminal as our query averageRatings is still running (otherwise, rerun it):
The loop is closed! We produce random JSON data using AI into Kafka, and read it back in pyspark to do some SQL queries on it.
Conclusion
This is the end of this article as we have already covered a lot of things!
How to get started with PySpark and Kafka
How to do filtering and transformations using SQL
How to do the same simply with Conduktor
How to use OpenAI/ChatGPT to open up the potential of what we can do just by asking questions
pyspark is really useful when we need to run ad-hoc analysis locally, and explore our data using SQL. Combined to Conduktor with its powerful Kafka UI and Gateway to do SQL on Kafka, it's a powerful stack to explore real-time data and do some data exploration and data science for cheap.




