Conduktor’s SQL on Kafka makes real-time insights more accessible, increases operational visibility and optimizes resources—without duplicating data into data lakes or warehouses.

19 déc. 2024
Apache Kafka has become the backbone of event-driven architectures. Its role in capturing and streaming critical business events—like orders placed or products shipped—makes it invaluable for organizations managing real-time data.
The introduction of tiered storage in Kafka enhances its ability to retain data for extended periods, making long-term storage more cost-effective. This capability complements the idea of utilizing Kafka for analytics, allowing for queries that cover live analysis and larger periods of historical data.
Querying Kafka is Not That Simple
However, natively querying Kafka to do troubleshooting or extract actionable insights often poses significant challenges. It traditionally requires duplicating data into external systems, like data lakes or warehouses, which often requires coordination across multiple teams, aligning security policies across different systems, and the obvious operational overhead of managing new data pipelines.
In a blog post earlier this year, our CPTO Stephane Derosiaux, explained how using a familiar language like SQL to directly query Kafka could solve most of these issues. After all, SQL is the universal language of data, understood across engineering, analytics, and business teams. So, by enabling direct, on-demand SQL queries on Kafka, we could make real-time insights more accessible.
Bringing the Power of SQL Queries on Kafka
At Conduktor, we’ve been working hard in the last few months to make this happen, and I’m very happy to announce that our new SQL Query capabilities are already part of our core product: Conduktor Scale. Our approach simplifies SQL querying on your Kafka clusters—self-hosted or managed. Here’s how we make it possible:
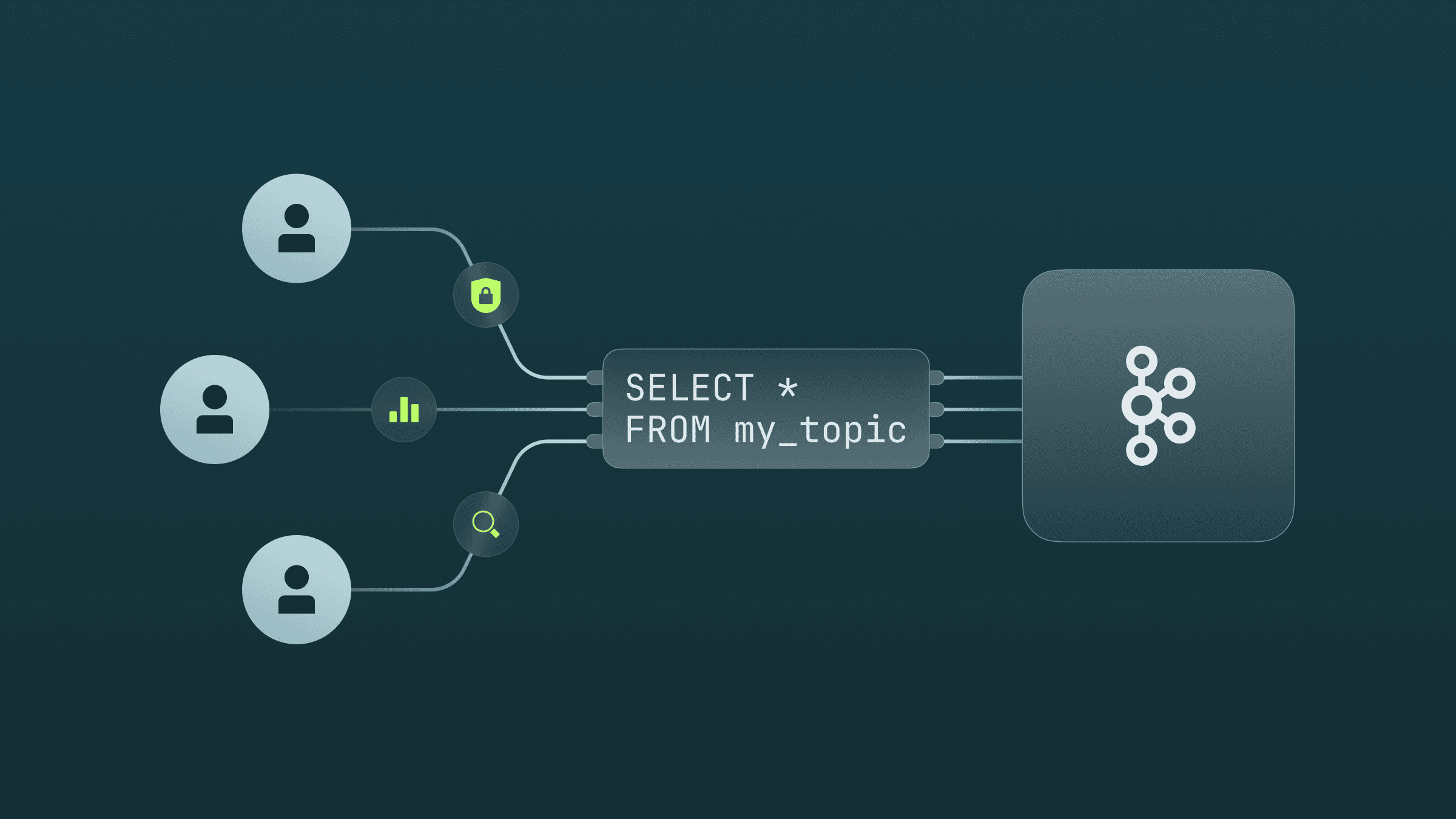
Granular Access Control: Integrated with Conduktor's robust RBAC model and data masking, we ensure secure, least-privilege access to data.
On-Demand Indexing: Users can selectively index specific topics for analysis. For example, while troubleshooting a recent issue in your order flow, you might index the purchases, and returns topics, focusing on the last 24 hours of data.
Streamlined Queries: Data is transformed into a familiar, columnar table format, enabling teams to easily query and analyze business data like purchase details and customer events using SQL.
Operational Visibility and Resource Optimization: Ops teams can query Kafka metadata like timestamps, offsets and compression type to optimize performance (e.g. compression ratio in a topic), monitor and audit Kafka resource usage, and troubleshoot issues like identifying duplicates.
Efficient Data Analysis: Once your analysis is complete, Conduktor allows you to quickly drop indexed data, eliminating the need to store data permanently in a warehouse or data lake.
It supports diverse use cases like filtering events, aggregating data, and correlating streams. But let’s see all this in practice with a quick video demo.
Conclusion
With SQL on Kafka, real-time data analysis becomes accessible to everyone in your organization, from data engineers to business analysts. Conduktor’s platform bridges the gap between Kafka’s powerful streaming capabilities and the universal accessibility of SQL, empowering teams to act faster and smarter.
If you already have Conduktor, learn how to configure it here.
And if you are new to Conduktor and are ready to transform your Kafka experience, book some time for a personalized demo!




