What Schema Registry is and why you should use it for your Apache Kafka. We demonstrate how to set up an Aiven Karapace registry with Conduktor

24 nov. 2022

In this article, we look into why Schema Registry is best practice if you are an Apache Kafka user.
First, we take a step back on Apache Kafka and how it transfers data using Zero Copy, serialization, and data formats.
Then we discover what a Schema Registry is and how it can secure your Kafka through schema validation.
Finally, we see an example of how to set up an Aiven Karaspace Registry on Conduktor Console to create, manage and update your schemas while keeping compatibility in check so nothing breaks upstream or downstream.
Part 1: What is Apache Kafka?
Apache Kafka is an open-source distributed event streaming platform that is composed of a network of machines called brokers. The brokers accept “events” from event producers and retain them based on time or message size, or both, allowing consumers to read and process them asynchronously.

Figure 1: Example Kafka cluster setup with a producer, a topic, and a consumer (1)
Zero Copy
It is important to understand that Kafka at its core operates on what is called “Zero Copy” or sometimes the “Zero Copy Principle”. This means that Kafka itself does not read the data that it is sending, it only transfers the data in byte format.
This ensures that Kafka has a significant performance improvement versus more traditional approaches for carrying out a great deal of copying between channels. Kafka also ensures no data verification is carried out at the Kafka cluster level. Kafka itself does not know what kind of data is sent or received.

Comparing Zero Copy (On the left) to more traditional approaches (On the right)
Figure 2: Comparing Zero Copy (On the left) to more traditional approaches (On the right) (3)
Serialization and Deserialization
As we have seen in figure 1, producers and consumers in Kafka do not communicate with each other directly; data is transferred between them via a topic. Before we can make use of “Zero Copy” we must utilize a process known as serialization and deserialization.
Serialization, carried out by the producer, converts an object into a stream of bytes used for transmission. Kafka then stores these bytes in the topic(s) the message has been sent to. Deserialization, carried out by the consumer, then converts the bytes of arrays into the desired data type, string, integer, Avro, etc. (4)

Kafka message serialization for a message with a Integer Key and a String Value
Figure 3: Kafka message serialization for a message with an Integer Key and a String Value (4)

Kafka message deserialization for a message with a Integer Key and a String Value
Figure 4: Kafka message deserialization for a message with an Integer Key and a String Value (5)
So what happens if a producer starts sending data to Kafka that your consumer doesn't know how to deserialize (sometimes known as a “poison pill”[6]) or if the data format is changed without changing the consumer? If this were to happen your consumer(s) downstream will start breaking as they can't properly read the messages, which could mean any applications involved will not work correctly. Depending on what the application is doing you could have a serious problem. The issue is more prominent in Kafka clusters which have many topics, i.e. the more topics you have the more potential cases where producers and consumers deviate due to serialization incompatibility.
Data formats and Schemas
In any process involving integration of data, the two main challenges to consider are the data format and the data schema.
The data format is how the data is parsed, i.e. binary, CSV, JSON, AVRO, Protobuf, etc; and the schema that you will use. There can be a multitude of reasons why you choose a certain data format: depending on legacy systems, choices on latency & throughput, and your company's own knowledge and experience.
A data schema is really the structure or shape of how your messages are sent. You could also consider it the “contract” between producers and consumers that the clients involved have agreed to send and receive messages.
Schema Example in JSON format
Figure 5: Example of a basic schema for an invoice in JSON format
Part 2: What is the Schema Registry?
The Schema Registry is an external process that runs on a server outside of your Kafka cluster. It is essentially a database for the schemas used in your Kafka environment and handles the distribution and synchronization of schemas to the producer and consumer by storing a copy of the schema in its local cache.
How does the Schema Registry operate?
A Schema Registry maintains a database of schemas that are stored within an internal Kafka topic known as “_schemas”. (This is a single partition topic that is log compacted).

Schema Registry in Apache Kafka
Figure 6: Schema Registry in Apache Kafka (1)
With the Schema Registry in place, the producer, before sending the data to Kafka, talks to the Schema Registry first and checks if the schema is available. If it doesn’t find the schema then it registers and caches it in the Schema Registry. Once the producer gets the schema, it will serialize the data with the schema and send it to Kafka in binary format prepended with a unique schema ID.
When the consumer processes this message, it will communicate with the Schema Registry using the schema ID it received from the producer and deserialize it using the same schema. If there is a schema mismatch, the Schema Registry will throw an error letting the producer know that it’s breaking the schema agreement.
Why use a Schema Registry?
Having a Schema Registry is really best practice when utilizing Kafka to ensure there is an automated way of ensuring data verification, schema evolution, and ability for new consumers to emerge without breaking downstream. Essentially these are the basics of good data governance when using Kafka.
As your use of Kafka develops and the people who use it change, having a Schema Registry ensures:
Data verification
Peace of mind
No breaking schemas even as your Kafka and team evolve.
What can happen if you don’t use a Schema Registry?
Let's say our team is working with Kafka, we are an online retail company and use a combination of JSON and Avro formats but mostly JSON. Our initial use of Kafka is as a small team of 5, however as Kafka grows to become business critical and spreads with other teams, we have users not familiar with the environment and at the same time we have had one or two employees move jobs and/or teams as sometimes happens, life and so on. In a few months time, someone who has never spoken to and probably never will speak to the original writer of one of the JSON schemas on our topic for Customer Orders makes a change to the input by adding or removing a field.
The topic then breaks, but we don't know what the problem is and it takes half a day to figure out why and where this schema was originally written, then we need to change the compatibility and also update the schema itself, all manually. A lot of hassle and unnecessary problems could have been avoided by using a Schema Registry.
In summary:
Kafka operates on the Zero Copy Principle and utilizes serialization and deserialization to achieve this.This ensures efficient data transfer versus other approaches, however Kafka doesn't know what data it is sending or receiving as it is just bytes.Using a Schema Registry ensures you have data verification and data versioning for your Kafka producers and consumers.This gives peace of mind that as your team and Kafka environment evolves no schema will break upstream or downstream and ruin your applications.
Part 3: Setting up a Schema Registry and checking compatibility
Tutorial
We have a better understanding of what a Schema Registry is and why we should use it as best practice in Apache Kafka, but how can you manage your schemas and Schema Registry in practice?
To do this we will set up a Kafka cluster on Aiven with a Schema Registry called Karaspace and then use Conduktor Platform to add a new schema, update this schema, and check its compatibility. This can be broken into the following four steps.
Step 1: Connecting your Aiven Cluster on Conduktor Platform
Step 2: Create a topic and a schema on that topic
Step 3: Send messages through the producer function with that schema.
Step 4: Make a change to the schema that might happen in real life and check compatibility again.
Prerequisites
Before we can carry out the above we need to have some prerequisites completed as shown below.
An Aiven account with 3 brokers Kafka cluster and Karaspace Schema Registry set up and running. See Aiven getting started and Karaspace docs for more information.
An account on Conduktor Platform and running. You can follow the instructions here to get started.
1) Configuring your Kafka Cluster
We have our Kafka running on Aiven, with the Karaspace Schema Registry and Conduktor Platform running. We now want to configure our Kafka cluster on Conduktor Platform. To do this we need the information from our Aiven Console (figure 7) and then go to the “Clusters” tab of the Admin section on Conduktor Platform to enter this information (figure 8). The cluster name is of your own choosing.

Aiven cluster configurations view
Figure 7: Aiven Cluster Configurations
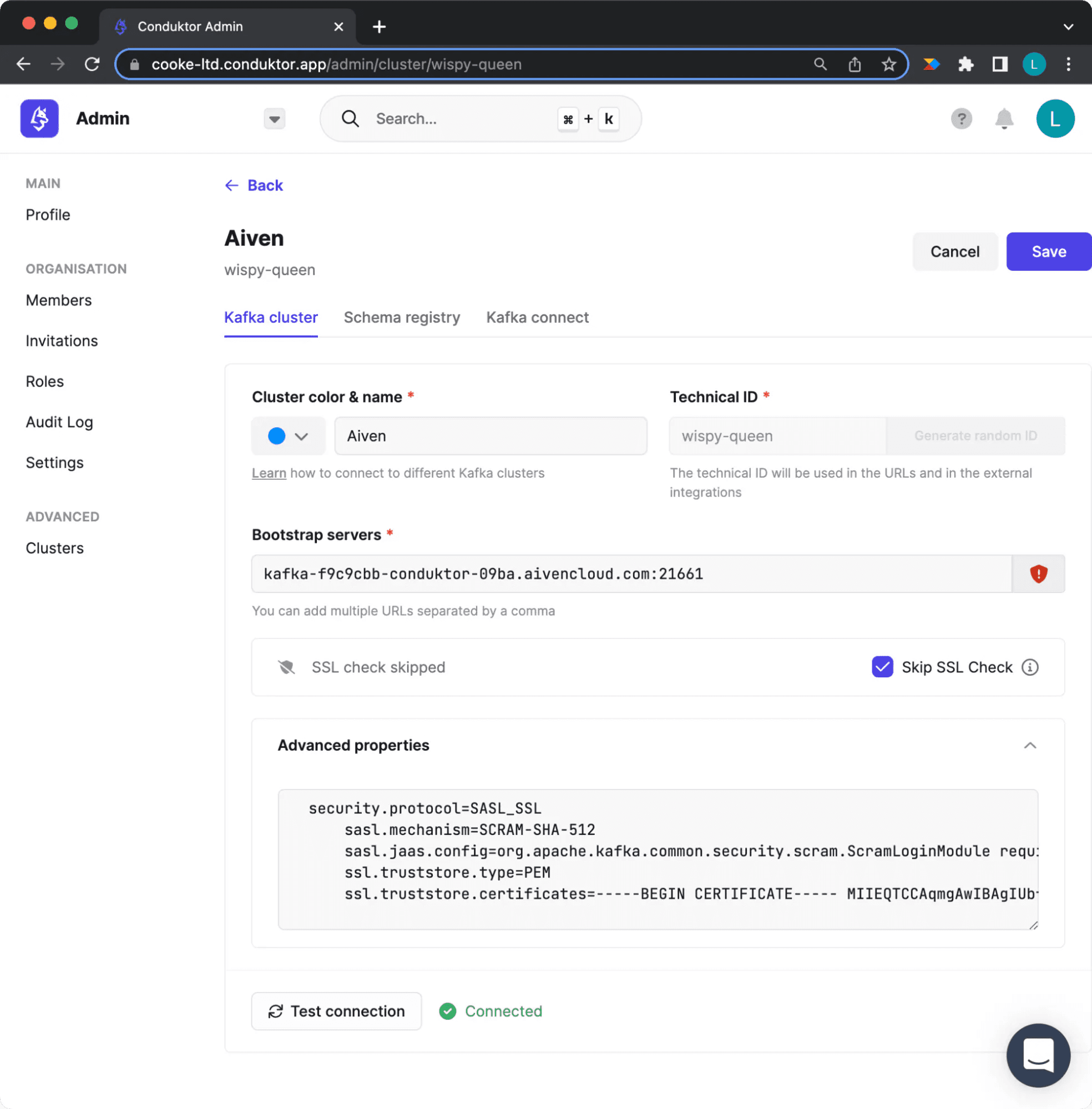
Configuring your aiven cluster in Conduktor Platform
Figure 8: Cluster Configuration on Conduktor
We then enter the bootstrap server for our Aiven Cluster and the advanced settings should be input in the format shown below, making sure the certificate is on one single line. We click save and make our way to Conduktor Console.
2) Creating a topic and adding a schema
Time to add a topic and create a schema on our Kafka cluster. On Conduktor Platform we go to Console and click “Create Topic” to generate a new topic called invoice-orders.

Creating a topic on Conduktor Platform
Figure 9: Creating a topic on Conduktor Platform
After this, we navigate to the “Schema Registry” tab and click “Create new schema” in the top right corner. We navigate to the “Schema Registry” tab and click “Create schema” in the top right corner. Copy the schema shown below and import it into our schema registry.
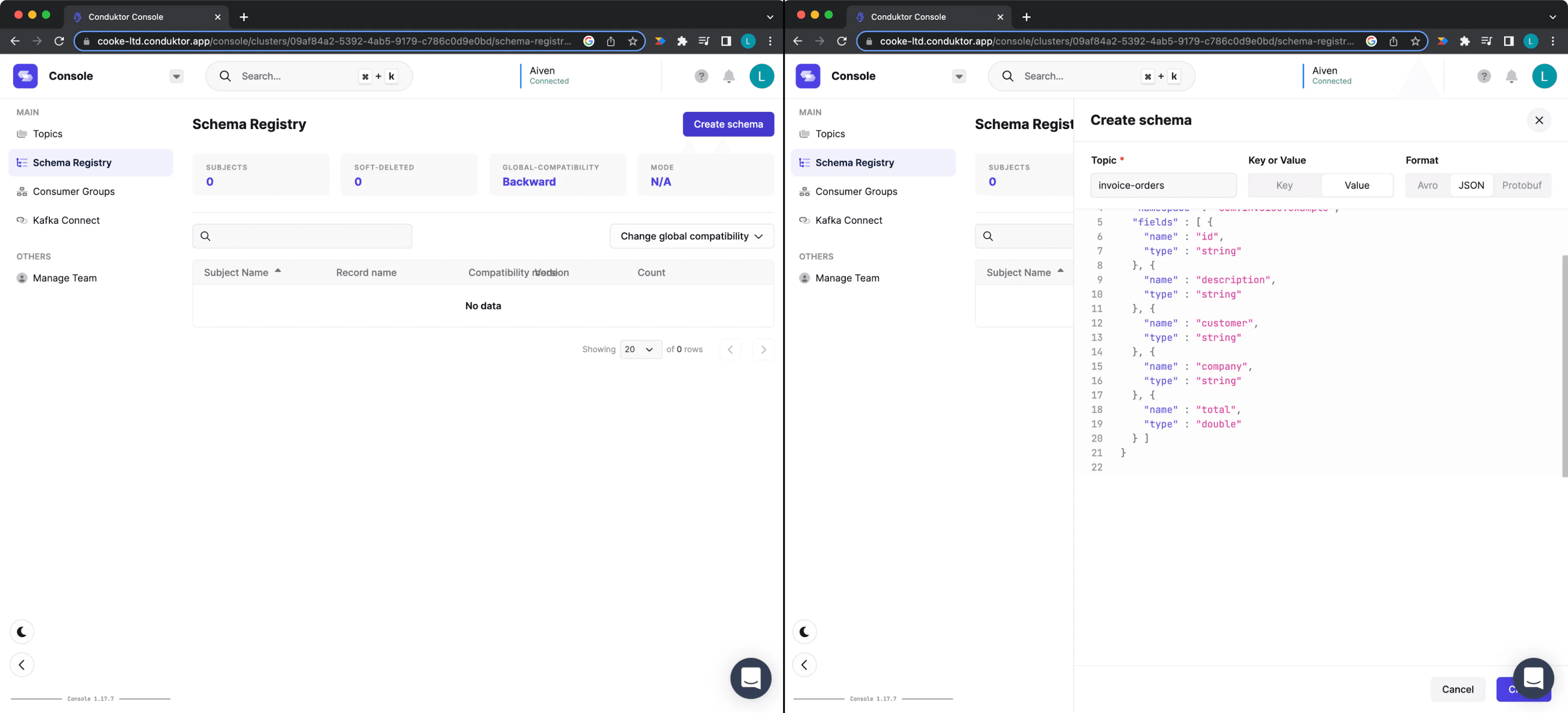
Creating a Schema on Conduktor Platform
Figure 10: Creating a schema on Conduktor Platform
The schema we will be using is a simplified JSON version of one being used for invoice processing.
While the schema vocabulary is out of the scope for this blog post, you can see six properties (key-value pairs) specified that describe an example invoice. Additionally, we make sure that all the objects are required, i.e. a message without all properties should be deemed as invalid.
Below is an example of a message according to this schema:
3) Produce messages according to the schema with a producer
We now want to produce messages according to the schema we have created. Conduktor Platform allows you to produce messages which can infer the data types of the schema concerned. Going back to the “invoice-orders” topic. We can produce one message or a flow of messages and have it end after a number of messages or after a period of time, as shown in figure 11.
This can help for testing in development or to trigger a specific message or event when it hasn't reached the topic.

Producing messages on “invoice-orders” topic
Figure 11: Producing messages on “invoice-orders” topic
4) Update the schema and check compatibility
In real life, our use of Kafka and the team that uses Kafka is going to change. Let's imagine we need to remove a field on this schema, whether that is because we want to cut down the information being sent, we don't trust our source of that particular information or it's just not required anymore.

Updating Schema and checking compatibility
Figure 12: Updating Schema and checking compatibility
In this case, we have removed the “Description” field, which is a string. To do that we will click “Update Schema” and remove this field, and before making this change we will “Check compatibility”. This lets us understand if this change will break anything upstream or downstream on our applications.
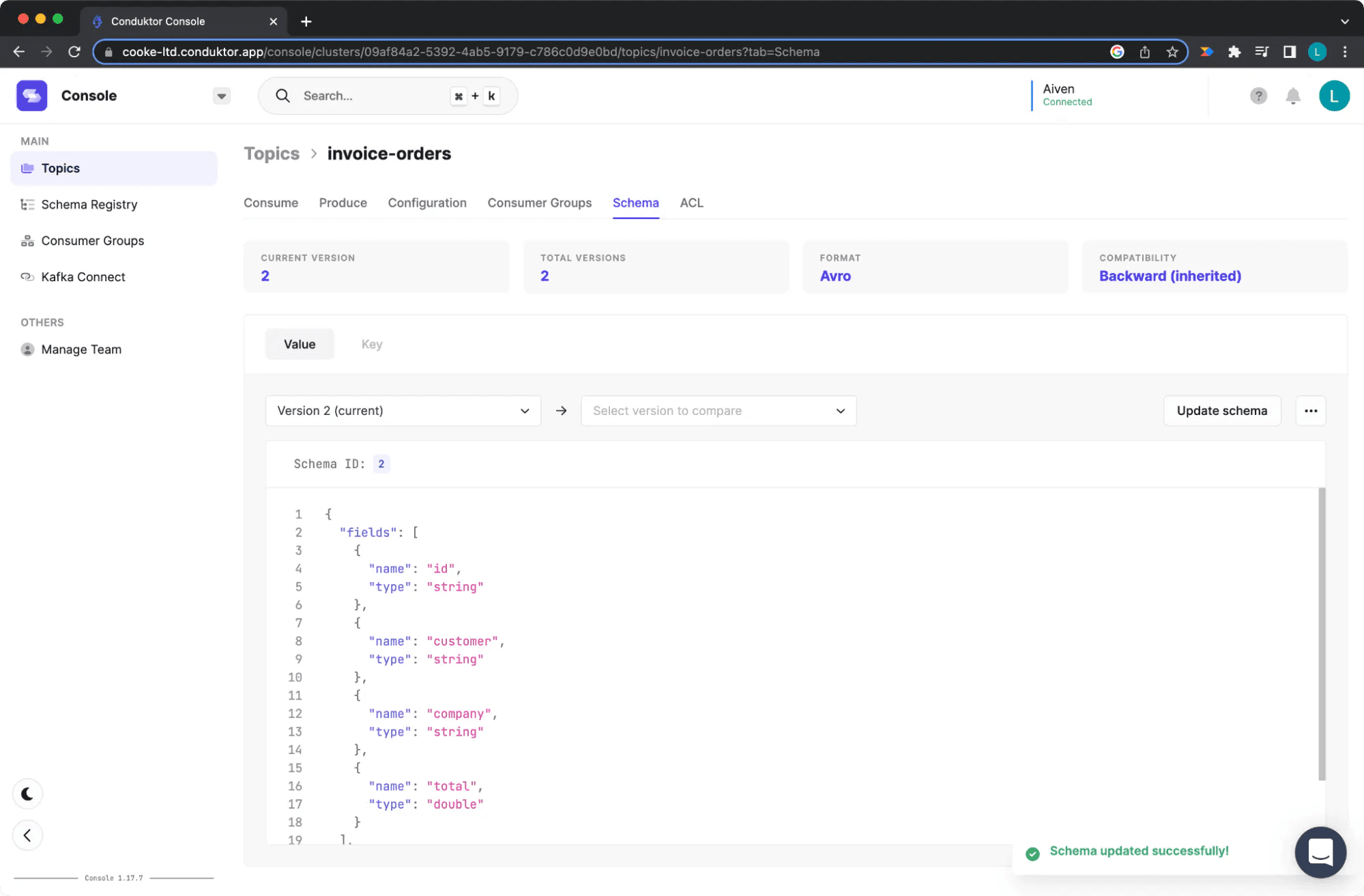
Updating the Schema once it is compatible
Figure 13: Updating the Schema once it is compatible
As can be seen after checking the compatibility, our update is not going to make any breaking changes upstream or downstream so we click update and are able to make our required change.
Final words
Using a Schema Registry is best practice to control what is produced and consumed within your Kafka cluster. Each schema defines the data format of the topics it is linked to, allowing you to make fields mandatory or to force the type of field.
It improves the quality of your Kafka data by standardizing it, and ensures consistency and viability over time. Indeed, the schemas have a version and can be updated. With Conduktor, you can check the compatibility between the previous and the new schema, in order to make sure that the modification does not impact your cluster, nor your producers and consumers.
Check out Conduktor Platform here and Aiven Console here.
Bibliography
https://developpaper.com/what-is-the-so-called-zero-copy-technology-in-kafka/
https://www.10xbanking.com/engineeringblog/bulletproofing-kafka-and-avoiding-the-poison-pill
https://medium.com/slalom-technology/introduction-to-schema-registry-in-kafka-915ccf06b902
https://medium.com/@sunny_81705/what-makes-apache-kafka-so-fast-71b477dcbf
https://andriymz.github.io/kafka/kafka-disk-write-performance/#
https://livebook.manning.com/book/kafka-in-action/chapter-11/13
https://medium.com/@sunny_81705/what-makes-apache-kafka-so-fast-71b477dcbf0
https://aseigneurin.github.io/2018/08/02/kafka-tutorial-4-avro-and-schema-registry.html




