The Kafka Governance Platform
Conduktor is the Kafka governance platform: schema policies, topic ownership, RBAC, field-level encryption, audit trails, and data quality rules — applied across every Kafka cluster you run, without changing your brokers.
What Kafka data governance covers
Kafka data governance is the policy and control layer that keeps a multi-team Kafka platform safe to operate. For any given topic, it tells you who owns it, who can touch it, what shape the data has to take, and what happens to records that fail. It's not a single feature — it's the layer you build (or buy) once the brokers alone stop being enough.
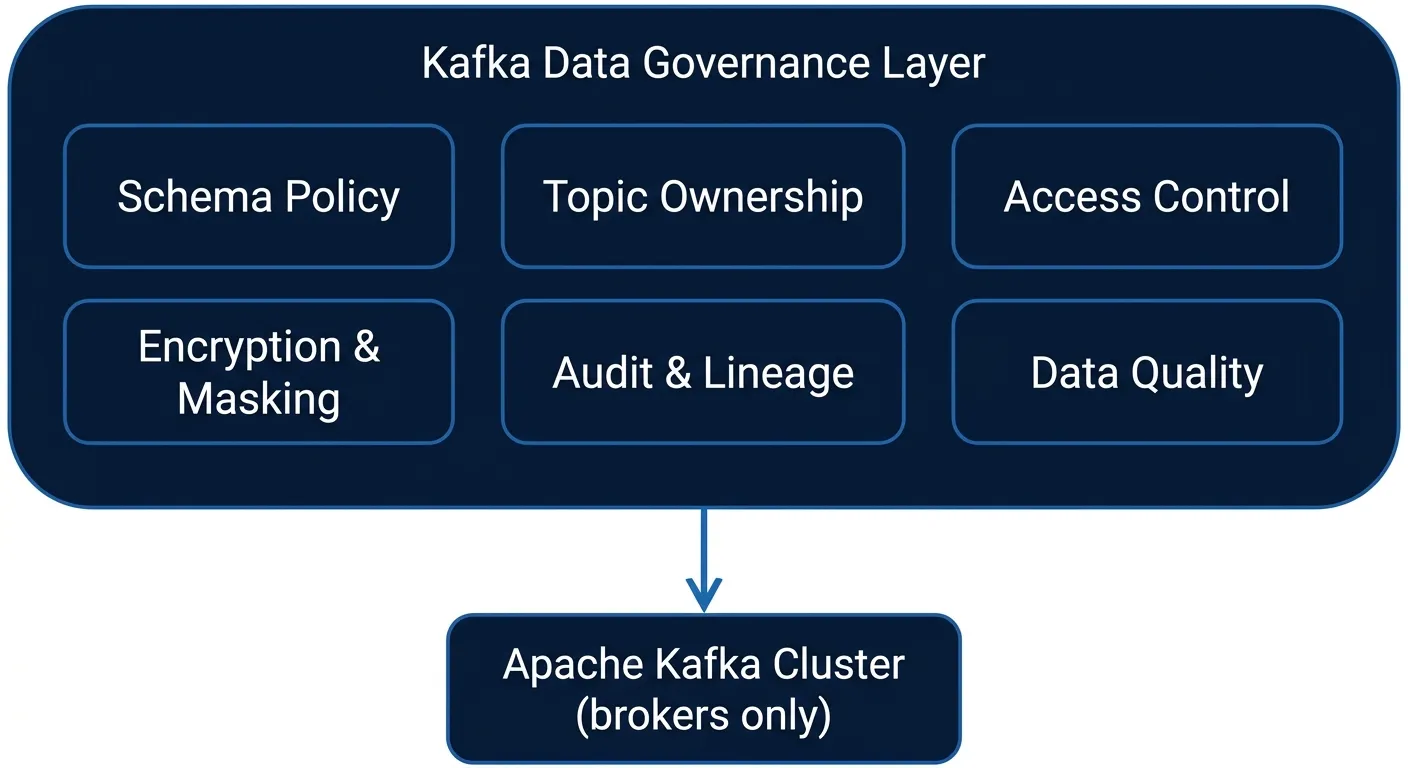
A complete Kafka governance platform answers six questions:
- Schema policy. What schemas are allowed on which topics, what evolution rules apply (backward, forward, full), and what happens when a producer breaks the contract.
- Topic ownership. For every topic, which application and which team is accountable. No orphan topics, no unowned resources.
- Access control. Who — human or service account — can produce, consume, create, or delete. Expressed as roles and groups, not raw ACLs.
- Encryption and masking. Which fields are PII, which need to be encrypted at the field level, which need to be masked in lower environments, and which keys protect them.
- Audit and lineage. Who did what, when, from where. Available in a queryable, exportable form, not just broker log lines.
- Data quality. What validation rules a message must pass to be considered acceptable, and what to do with the ones that fail.
A platform that only covers two or three of these is not a Kafka governance platform. It is a Kafka UI with some access control bolted on.
Why Kafka makes governance hard
Apache Kafka is a broker. It serves bytes. It does not, on its own, know what a "team" is, what a "topic owner" is, or what counts as a sensitive field. Every governance primitive above has to come from somewhere outside the broker:
- Schemas live in a Schema Registry, which is a separate service most teams treat as an artifact store rather than a policy point.
- Ownership is a Confluence page or a spreadsheet.
- Access is
kafka-acls.shand a manually-maintained ACL inventory. - Encryption is "we have TLS", which protects the wire but not the payload sitting on disk.
- Audit is brokers logging to local files, sometimes shipped, sometimes not.
- Data quality is whatever the producer team decided to validate, applied inconsistently.
Multiply that by 10 teams, 500 topics, three clusters, and an auditor asking "show me everyone who has access to topics containing PII", and the gap becomes visible.
How Conduktor delivers governance as one platform
Conduktor is built as a governance platform rather than a UI with policies attached. Three components share one identity, ownership, and policy model:
- Conduktor Console — topic-level governance at the management plane
- Conduktor Gateway — a Kafka proxy enforcing wire-level controls at the data plane
- Schema Registry Proxy — per-subject RBAC and audit at the schema layer
| Governance primitive | Conduktor capability |
|---|---|
| Schema policy | Schema Registry Proxy adds per-subject RBAC and audit on top of Confluent Schema Registry (AWS Glue coming); Gateway blocks breaking changes at produce time |
| Topic ownership | Application catalog: topics registered against an application inherit an accountable team |
| Access control | RBAC with roles, groups, and SSO/LDAP identity; ACLs managed for you at the broker |
| Encryption | Field-level encryption for JSON, Avro, and Protobuf payloads via Conduktor Gateway, with KMS-backed keys (Vault, AWS KMS, Fortanix) |
| Audit | Console audit logs cover management actions; Gateway audit events cover request-level traffic. Both are exportable to a SIEM |
| Data quality | CEL-based validation rules at the gateway, with route-on-failure to a DLQ |
Conduktor governance vs Confluent Control Center
| Concern | Confluent Control Center | Conduktor |
|---|---|---|
| Cluster support | Confluent Platform and Confluent Cloud | Any Kafka (MSK, Confluent, self-managed, Redpanda, Aiven) |
| Topic ownership model | Limited | Application catalog with accountable owners |
| RBAC | Confluent RBAC, Confluent-only | Works against any cluster, SSO-integrated |
| Field-level encryption | CSFLE (limited, schema-dependent) | Gateway encryption with KMS, any payload |
| Data quality validation | Schema Registry only | CEL rules at the gateway, with DLQ routing |
| Audit centralisation | Per-product logging | One audit trail across Console + Gateway |
| Self-service for developers | Limited | First-class: topic and access requests with workflow approval |
Where governance lives in the Conduktor architecture
- Conduktor Console enforces policies at the management plane: schema rules, topic naming, ownership, RBAC, self-service approvals, audit. Read more on the Console page.
- Conduktor Gateway is a Kafka proxy that enforces policies at the data plane: authentication, RBAC, field-level encryption, masking, data quality, traffic transformations. It sits between clients and brokers, so applications connect to the gateway instead of the cluster directly. Read more on the Gateway page.
- Conduktor Schema Registry Proxy sits in front of your Schema Registry (Confluent SR today, AWS Glue coming) and adds per-subject RBAC, OIDC/JWT authentication, and audit without forking the registry itself. Read more on the Schema Registry Proxy page.
- Identity is shared via your IdP. Console authenticates users through OIDC SSO or LDAP; Gateway and Schema Registry Proxy accept OIDC/OAuth tokens (LDAP via a federated IdP like Keycloak). Removing a user from the IdP cuts off every surface.
For the underlying security primitives the governance layer relies on (encryption, authentication, ACLs vs RBAC, auditing), see the Kafka Security Guide.
Frequently asked questions
What is Kafka data governance?
Kafka data governance is the set of policies and controls that determine, for every topic and message in a Kafka estate, who owns it, who can access it, what schema and quality rules apply, what data is sensitive, and how every action is audited. It is delivered by a governance platform on top of Kafka, not by the broker itself.
Is Apache Kafka enough on its own for data governance?
No. Kafka brokers serve bytes; they have no concept of teams, owners, sensitive fields, or audit retention. Governance requires a layer above Kafka — Schema Registry, an ownership model, RBAC, encryption, audit pipelines, and quality rules — coordinated through one platform.
How does Conduktor compare to Confluent for governance?
Both cover the basics. Conduktor extends governance to any Kafka cluster (not only Confluent), adds gateway-level encryption and data quality enforcement, and is built around an application/team ownership model that maps registered topics to an accountable owner. Confluent Control Center is tightly coupled to Confluent Platform and Confluent Cloud.
Do we need to change our brokers to run Conduktor governance?
No. Conduktor connects to any Kafka cluster as a client and runs the Gateway as a transparent proxy in front of it. No broker plugins, no broker reconfiguration.
Where does Schema Registry fit in?
Schema Registry stores schemas; out of the box it does not enforce per-subject access control or produce an audit trail. Conduktor's Schema Registry Proxy is a drop-in in front of Confluent Schema Registry (with AWS Glue support coming) that adds OIDC/JWT authentication, per-subject RBAC, and audit logging. Schema content stays where it is — the proxy adds the governance layer around it.
I have more questions.
Drop us a line and we'll get back to you.
Run a Kafka Governance Platform Across Every Cluster
One control plane for schema policy, ownership, RBAC, encryption, audit, and data quality. Works in front of MSK, Confluent Cloud, Redpanda, Aiven, or self-managed Kafka.