Build a Kafka Streaming Platform That Scales Without a Bottleneck

Kafka adoption follows a predictable arc. One team discovers it, runs it themselves, and life is good. Other teams notice, start using it too, and suddenly you're managing a sprawling mess of clusters, topics, and competing practices.
Two responses emerge: centralize everything under one team, or let each team fend for itself. Both fail.
The Centralization Trap
A central Kafka team sounds reasonable. One group owns clusters, topics, ACLs, and configuration. Developers submit requests, the team executes.
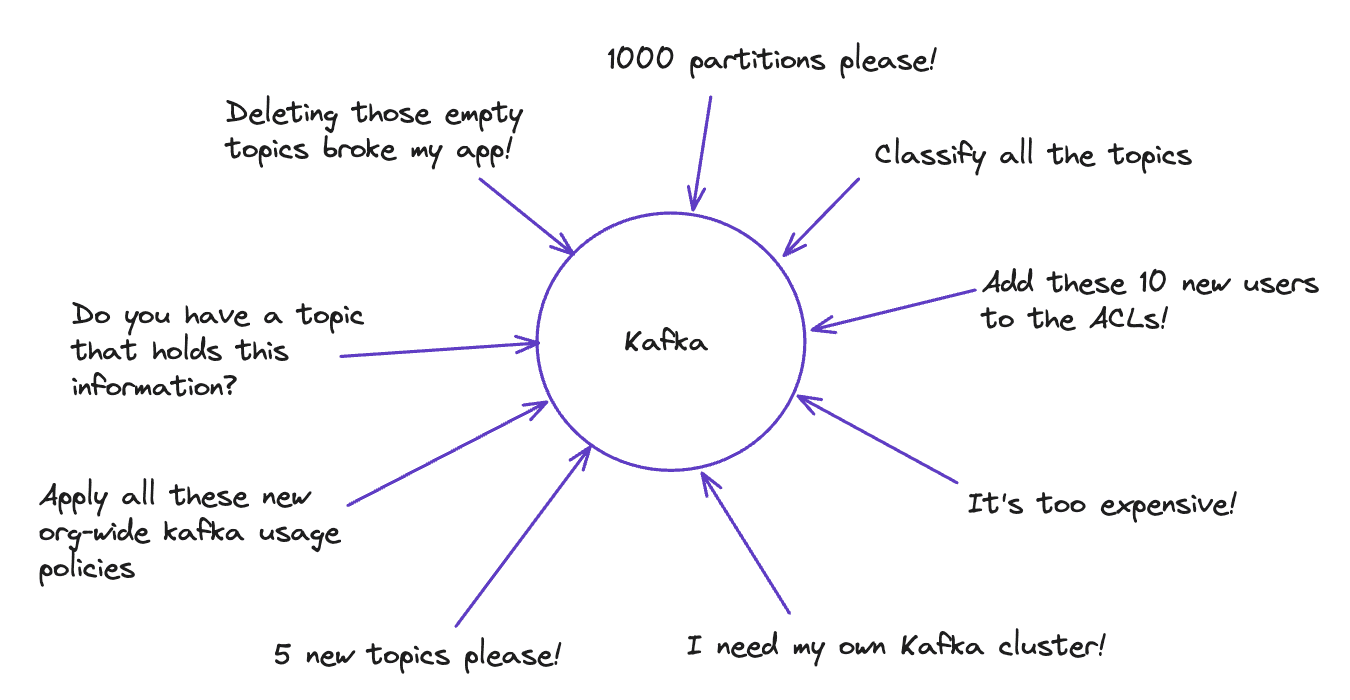
What happens:
- The team inherits 500 topics nobody can explain. Deleting anything risks breaking a forgotten legacy app.
- Every topic creation becomes a ticket. Developers work around the team or wait days.
- The CFO asks why Kafka costs so much. The team has no visibility into what's actually used.
The central team becomes a bottleneck. Their job shifts from building value to processing requests and answering support questions. Organizations respond by growing the team, which treats symptoms, not causes.
The Decentralization Trap
The opposite approach: let each product team own their Kafka infrastructure. Move fast, solve problems locally.
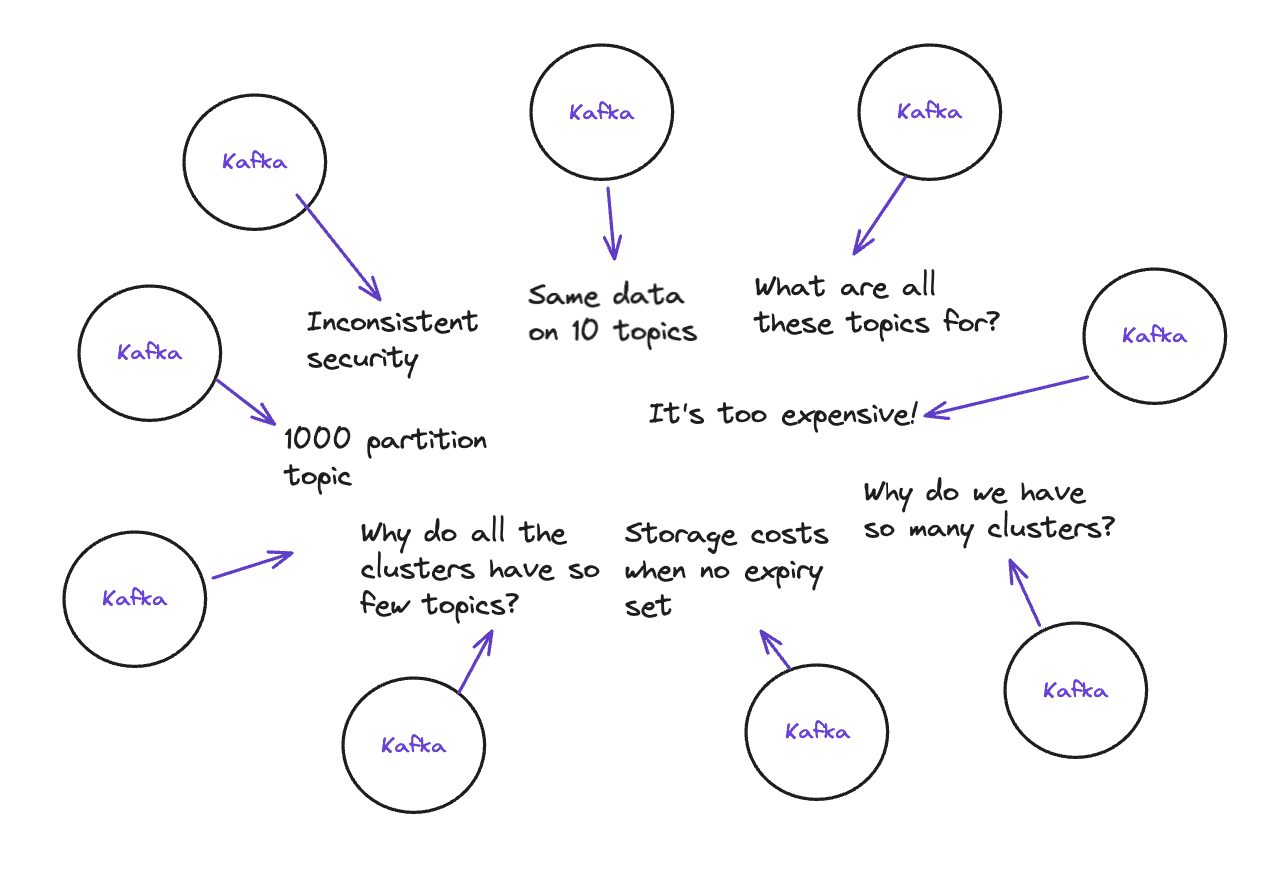
What happens:
- Teams create 1000-partition topics because no one stopped them.
- Security policies vary wildly. Some clusters have no encryption.
- Configuration sprawls: infinite retention here, wrong replication factor there.
- 150 clusters, each with a handful of topics. Cloud bills explode.
Nobody knows what exists across the organization. Enforcing GDPR, PCI, or any compliance standard becomes impossible. Staff turnover creates knowledge voids.
Hybrid: Decentralized Governance With Guardrails
Both extremes fail because they solve the wrong problem. Centralization creates bottlenecks. Decentralization creates chaos. The solution combines self-service with enforcement.
Five principles make this work.
Decide If You Need Structure
Skip this if:
- You're small and Kafka won't grow
- Kafka is a side project, not core infrastructure
- You have one use case and no cross-team dependencies
Otherwise, structure now costs less than structure later. The longer you wait, the more archaeology you'll do when you finally clean up.
Put a Gateway Between Apps and Clusters
Applications and tools connect directly to Kafka. To enforce rules, you'd need to modify every app or somehow add logic to Kafka itself (impossible).
Conduktor Gateway, our Kafka proxy, intercepts all traffic:
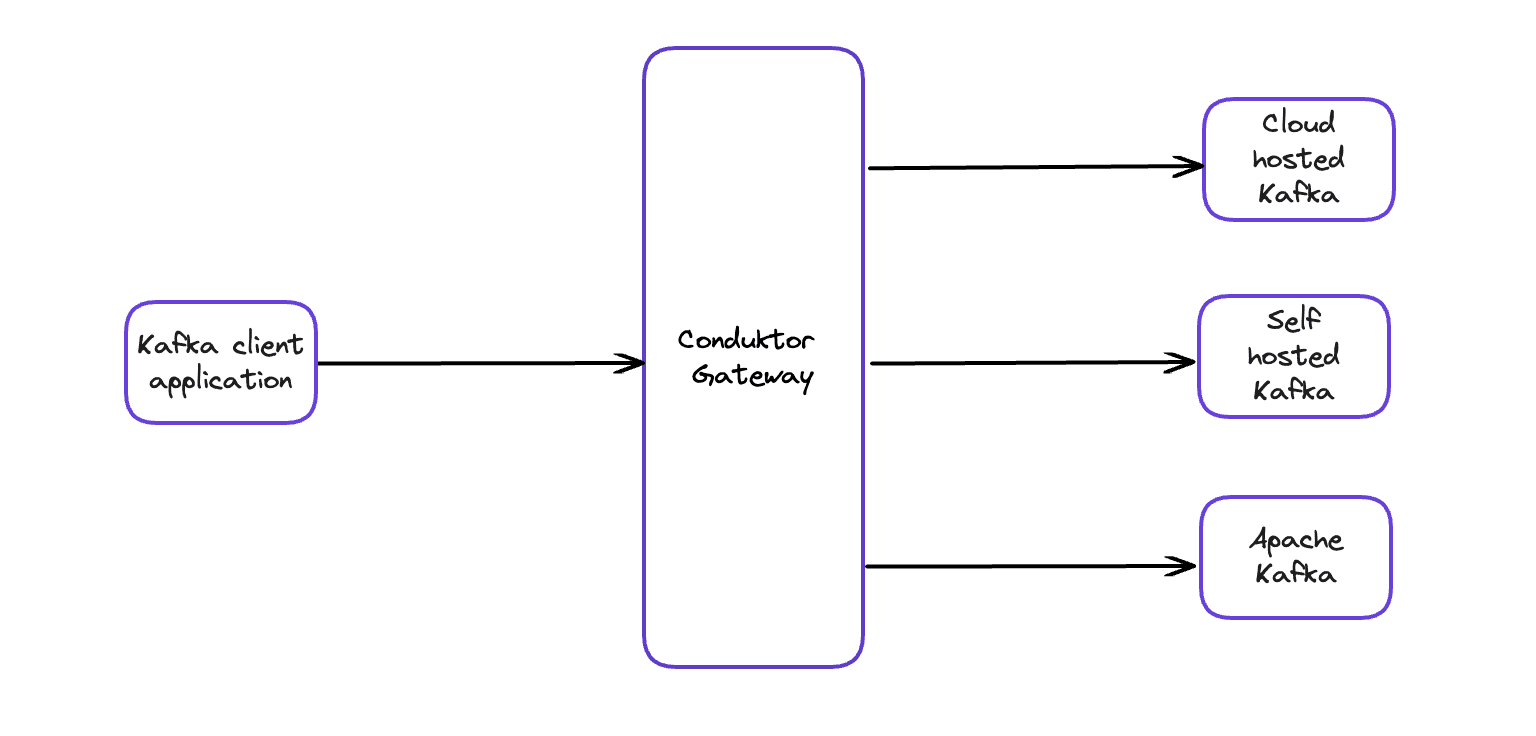
Every request passes through: topic creation, configuration changes, produce/consume operations, ACL setup. You get enforcement without touching applications or Kafka. Works across clusters, languages, and tooling.
Use Multi-Tenancy to Reduce Cluster Sprawl
Multi-tenancy splits one physical Kafka cluster into isolated virtual clusters. Each tenant sees a standard Kafka cluster but can't access other tenants' resources.
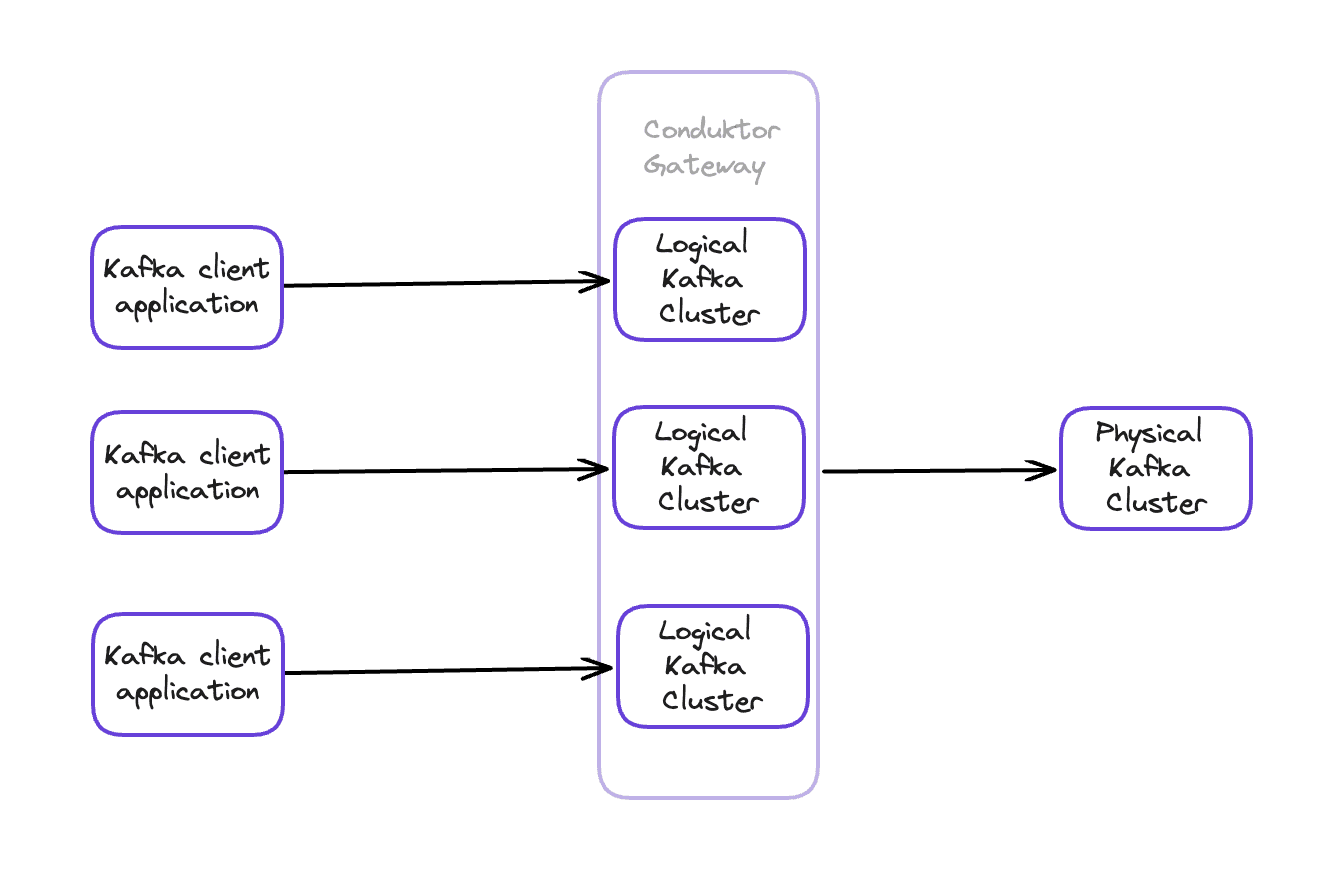
A tenant can represent:
- A business domain (delivery, sales, customers)
- A project with its own apps and topics
- A single application
Benefits:
- Fewer physical clusters to manage (cost)
- Spin up temporary clusters for testing or sandboxes
- Share data between domains without cross-cluster replication
Native Kafka supports a crude form of multi-tenancy through prefixes and ACLs, but it's manual and error-prone. Conduktor Gateway handles this natively. View multi-tenancy demo.
Enable Self-Service Within Boundaries
Give teams their own virtual clusters. They create topics, set retention, configure ACLs, all without waiting for a central team.
No tickets. No delays. Teams own their data.
This looks like decentralization, but with one difference: all actions pass through the Gateway, which enforces the next principle.
Enforce Rules at the Gateway
Self-service without guardrails creates the same chaos as full decentralization. The Gateway intercepts requests and enforces organizational standards:
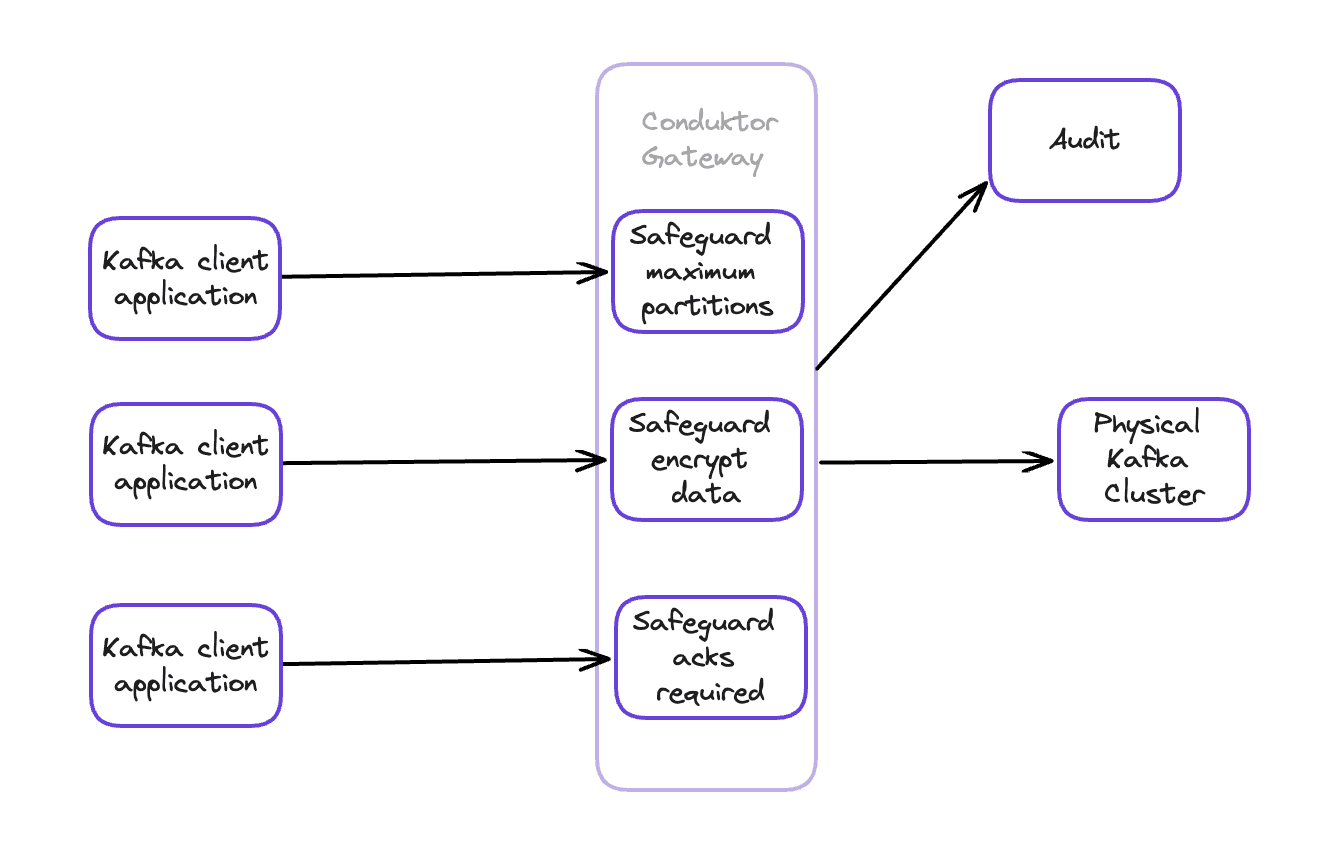
Examples:
- Reject topics with
replication_factor=1when you require 3 - Encrypt all
credit_cardfields automatically - Enforce topic naming conventions like
[BU]-[Project]-[PrivacyLevel]-name - Soft enforcement: log violations without blocking, for migration periods
The Gateway provides what Kafka doesn't: policy enforcement, audit trails, field-level encryption, RBAC, and lineage.
Tradeoffs
Hybrid isn't free. You're adding infrastructure (the Gateway) and operational complexity. If your Kafka usage is small and stable, pure decentralization or centralization might work fine.
But if you're scaling, the hybrid approach prevents both bottlenecks and chaos. Self-service keeps teams fast. Enforcement keeps infrastructure sane.
Contact us to discuss your use case.