
Over 40% of organizations suffer from poor data quality, affecting their operations and decisions (source: Experian). A simple fix exists: tagging resources.
This article covers how tags save resources and improve data analytics accuracy.
Tags Are Free-Form Metadata
A tag is a label assigned to a piece of information. Hashtags on X or Instagram work the same way. Click #apachekafka and you find everyone talking about it.
Trello and Linear use the same concept. Columns are tags that organize tickets.
A tag on a resource can represent:
- Owner, team, project name
- Environment, update frequency (millis, daily, weekly)
- Internal code name, cost center
Tags can encode time as key:value pairs: shutdown_at:xxx, restart_every_ms:xxx. They trigger automation and GitOps workflows. Adding or removing a tag can kick off any process.
Tags are free fields to store metadata on a resource. A key-value store attached to anything.
In Conduktor, tags on topics clarify ownership and simplify management:
Tags as Lossy Compression
Tagging is lossy compression for data categorization.
Data tagged as "PII" indicates personal identifiers like email, name, and phone number. In libraries, categorizing books under "A-B" doesn't pinpoint exact locations but enables binary-tree-style searching.
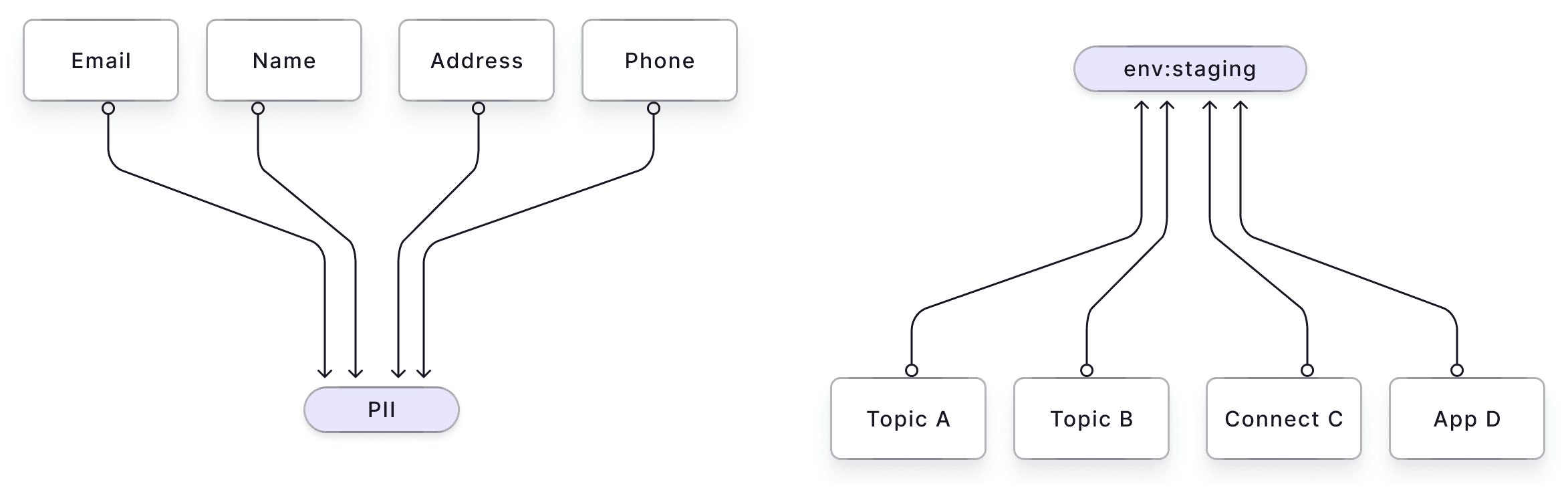
Tags offer multiple perspectives on data, like a prism. They simplify resource selection for analysis, organize information, and support visual representations like charts and tables.
Tags Enable Data Mesh
Conduktor believes in Data Mesh principles. Our mission is helping platform teams adopt this model to maximize their data's value.
In Data Mesh, tags categorize everything into Data Products. They define:
- Ownership, description
- Semantic models, data schemas
- SLAs, lifecycle, intended use
- Data quality, freshness, lineage, versioning, origin
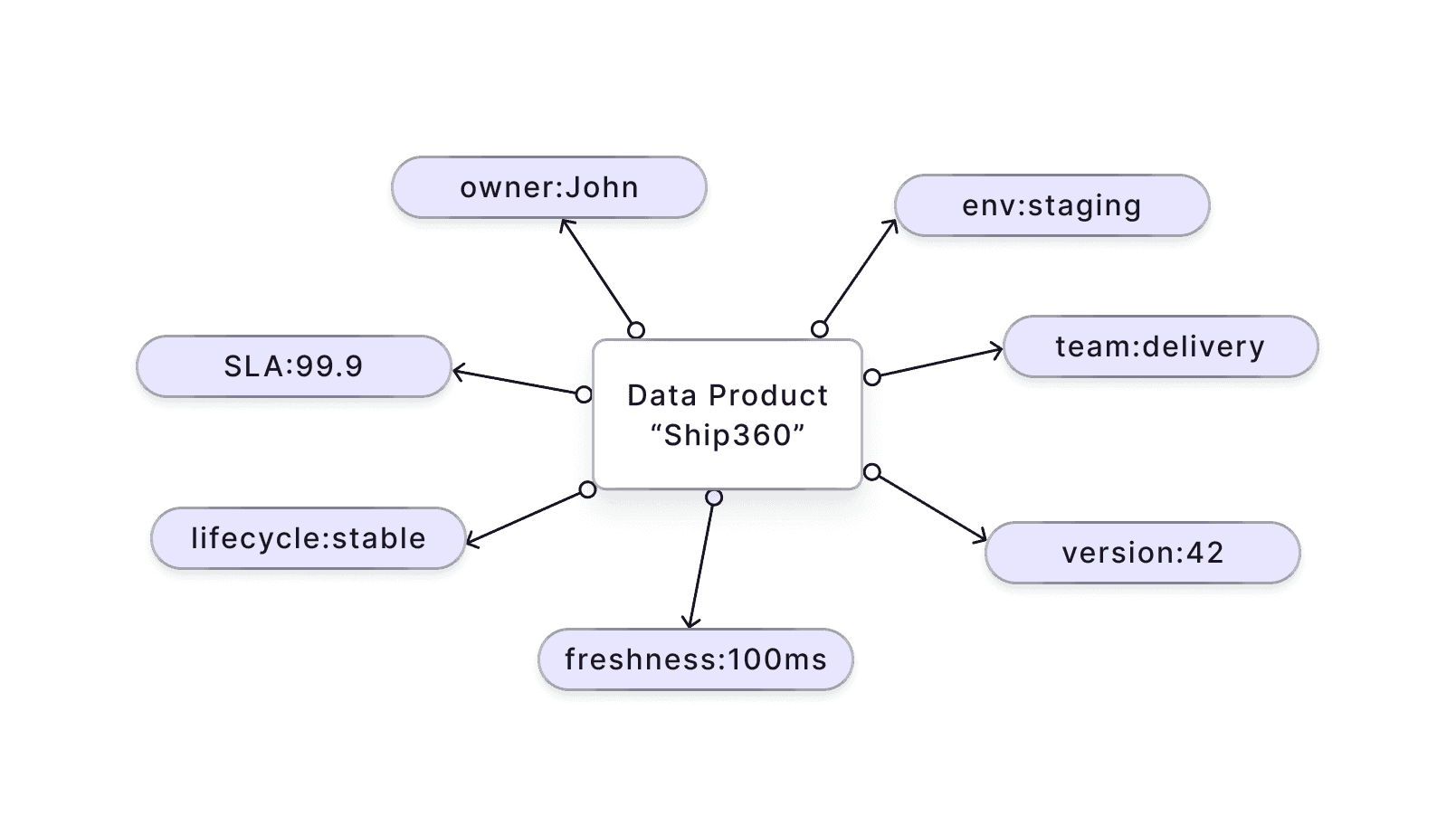
Tags form a core component of data governance. Most are curated manually, though AI is moving toward automating suggestions.
Missing tags signal poor data quality and weak governance. Tags don't just organize data. They add context and meaning, improving accessibility, compliance, and utility across the ecosystem.
In Data Mesh architecture, where decentralized ownership and domain-oriented design matter, tags act as connective tissue. They ensure coherence in sprawling data landscapes.
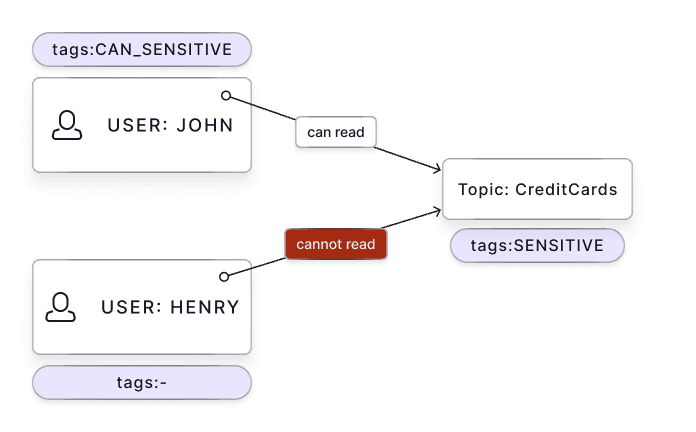
Tags Enable ABAC Security
Attribute-Based Access Control (ABAC) is an alternative to RBAC. Permissions depend on attributes (tags) of resources and users.
Tags apply to roles and users, not just resources. This enables ABAC policies based on "who" the user is and "what" they access. Authorization happens only when user tags match resource tags.
Example: Sensitive data tagged sensitive requires users or roles tagged can_sensitive to interact with it.
Hierarchical Tags Beat Flat Lists
Tags can be hierarchical, like folders. Nested structures clarify relationships between concepts.
In large ecosystems with many tagged items, hierarchical structures outperform flat tagging. They simplify navigation and reduce conflicts.
In diverse organizations, the same tag may mean different things across teams. Combining flat tags to understand the big picture gets messy.
Hierarchical tagging introduces order and intuitive data relationships:
roles/ownersales/onlinesalesteam/summarygeo:europe/france/paris
Beyond Tags: Ontologies
Not the metaphysical kind. Data ontologies are structured frameworks for organizing information that define categories, properties, and relationships.
Ontologies carry more meaning than tags. AI systems, databases, and the semantic web use them when rich, formal structures are necessary.
Ontologies establish a comprehensive, nuanced, and interconnected data model beyond basic categorization.
Tag Everything, Everywhere
Tags are essential for any serious data ecosystem. Their purpose varies by scale: metadata, automation, analytics, or compliance.
Whether you're a team of 5 with hundreds of resources or 100 people with five resources, tagging everything pays off.
Conduktor helps tag resources like topics for classification, search, and ownership. Tags provide quick insights into your ecosystem and enable faster decisions through automation.