
Conduktor Gateway enhances Kafka by enforcing best practices at the protocol level. It sits between clients and brokers, intercepting requests before they can cause damage.
Safeguarding combines data governance with technical enforcement. It protects both the data flowing through your cluster and the cluster itself. Good safeguarding helps organizations:
- Minimize outages
- Respond gracefully to change
- Reduce friction between teams
Three Stages of Kafka Safeguarding
Most organizations progress through three stages:
- Safeguarding by habit (manual checklists)
- Reactive automation (alerts after the fact)
- Proactive automation (enforcement at request time)
Manual Checklists: The Production Readiness Problem
Most safeguarding today relies on documented practices that are periodically discussed and partially applied.
This approach suffers from three problems:
Relevance. Rules are "one size fits all" and rarely tailored to specific technologies or domains.
Timeliness. Checks happen at the end of the development cycle when changes are expensive.
Perception. Teams view safeguarding as a necessary evil. "What can we get away with?" becomes the default attitude.
The production readiness checklist is a perfect example. A week before go-live, teams are presented with boxes to tick. The rules are generic, the timing is bad, and everyone resents the process.
Reactive Automation: Catching Problems Too Late
The obvious fix is automation. Reactive automation turns safeguarding rules into metrics, thresholds, and alerts.
When a misbehaving client impacts cluster health, an alert fires. Then what?
Simple logic says: turn off the bad actor. But what if it has dependencies? What if it's more mission-critical than the applications it's affecting?
These decisions must be made quickly under pressure, usually in production, with a wide blast radius. The result is workarounds and temporary fixes that never get removed. Technical constraints that persist for years.
This is how tech debt accumulates.
Proactive Automation: Enforcing Rules at Request Time
Proactive automation enforces rules at the point of interaction with Kafka. Requests that violate standards are rejected or automatically corrected before reaching the broker.
Example: A client requests a topic with 50,000 partitions. This will strain the cluster. Instead of rejecting the request, proactive automation modifies it to cap at 50 partitions.
Compare this to reactive automation. The reactive approach discovers the high-partition topic days or weeks later. By then, the topic holds data. Reducing partitions is now difficult and time-consuming.
Where to Implement Proactive Safeguarding
There are three options:
Broker Plugin
Deploying within Kafka puts the logic close to the data and cluster state. The downside: plugin updates require broker restarts. Version coupling creates maintenance headaches.
Client Plugin
A client-side plugin integrates well with applications but creates a massive surface area. You need plugins for every client language. Worse, the broker can't verify that clients are using the plugin. Bad actors can bypass it entirely.
Kafka Proxy
A proxy between clients and brokers avoids both problems. It can be configured and restarted independently of the Kafka cluster. Clients connect to the proxy as if it were Kafka. Direct broker access can be disabled through standard Kafka security.
How Conduktor Gateway Implements Proactive Safeguarding
Conduktor Gateway is a Kafka proxy that enforces safeguarding rules through Interceptors.
The partition limit example works like this: Gateway executes an Interceptor on the CreateTopics request. The client sends 50,000 partitions. Gateway modifies the request to 50 partitions before forwarding to the broker.
Gateway is a stateless Java application that presents itself as a Kafka cluster to clients. Typical deployments use one Gateway cluster per Kafka cluster, but you can also deploy per-application or in tiers (application-level rules, organization-level rules).
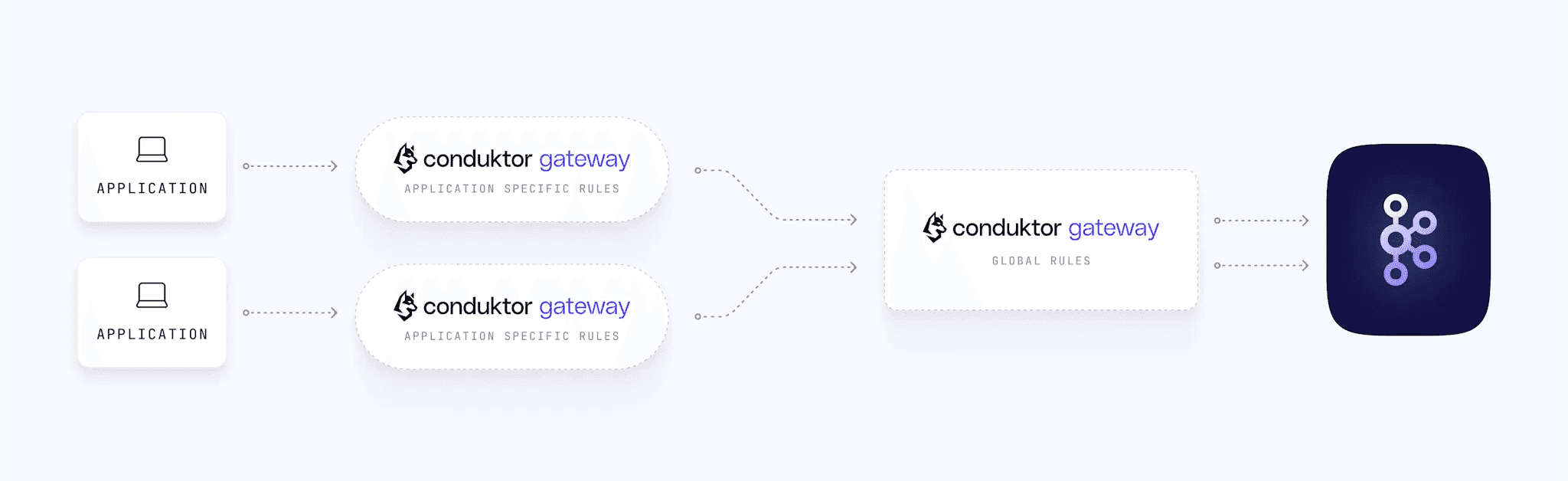
The Hidden Benefit: Developer Buy-In
Proactive safeguarding prevents outages and increases cluster resilience. That's the obvious benefit.
The subtle benefit is perception. Manual checklists and reactive alerts feel like barriers. Developers and operators resent them.
Proactive safeguarding is different. It provides immediate feedback with specific guidance. Teams understand why a request was modified. This makes it easier to get buy-in for best practices and governance.