Building Kafka Tooling That Actually Scales: Security, Governance, and GitOps

Real-time data powers modern digital products. The sources multiply. The volume grows.
Businesses need this data to act on information as it happens and to gather insights for long-term decisions. Yet 36% of IT decision makers worry their infrastructure won't meet future data requirements. In the rush to keep pace with demand, engineers often overlook security and governance.
These oversights become expensive at scale.
Why Real-Time Data Processing Matters
Teams handle streaming from thousands or millions of endpoints to applications and environments. Processing data as it emerges unlocks business value.
In programmatic advertising, real-time bidding serves the right ads to the right audience. In transport logistics, real-time data combined with AI optimizes fleet tracking, route efficiency, and connections for hundreds of thousands of passengers daily.
Organizations tap into real-time insights but struggle to build tooling that works at scale.
Consider a retailer whose online store sends customers products similar to, but not matching, their exact order. This happens because the stock inventory doesn't update the website in real time:
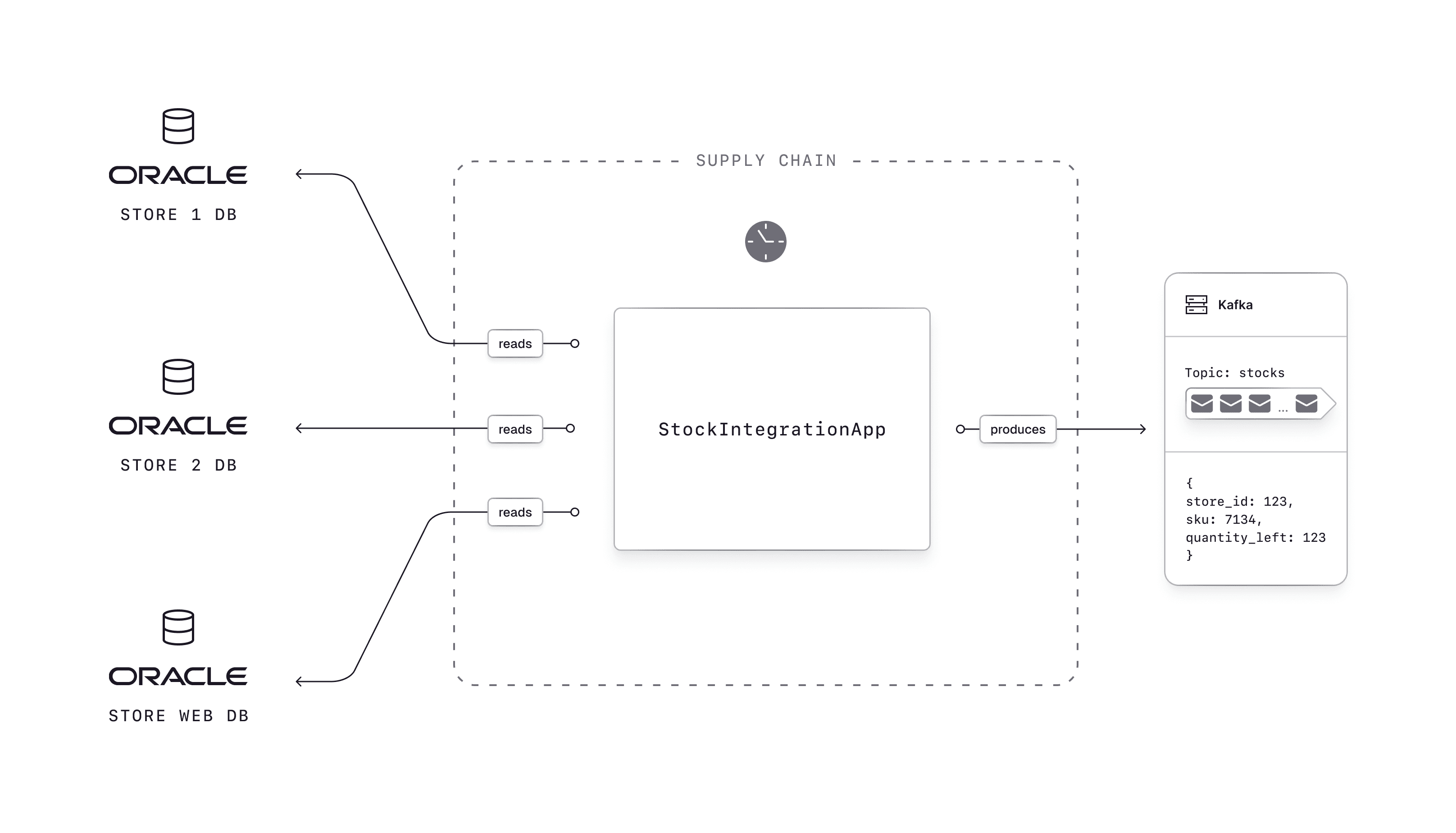
Data sitting in a pipeline provides no value. Real-time streaming changes this:
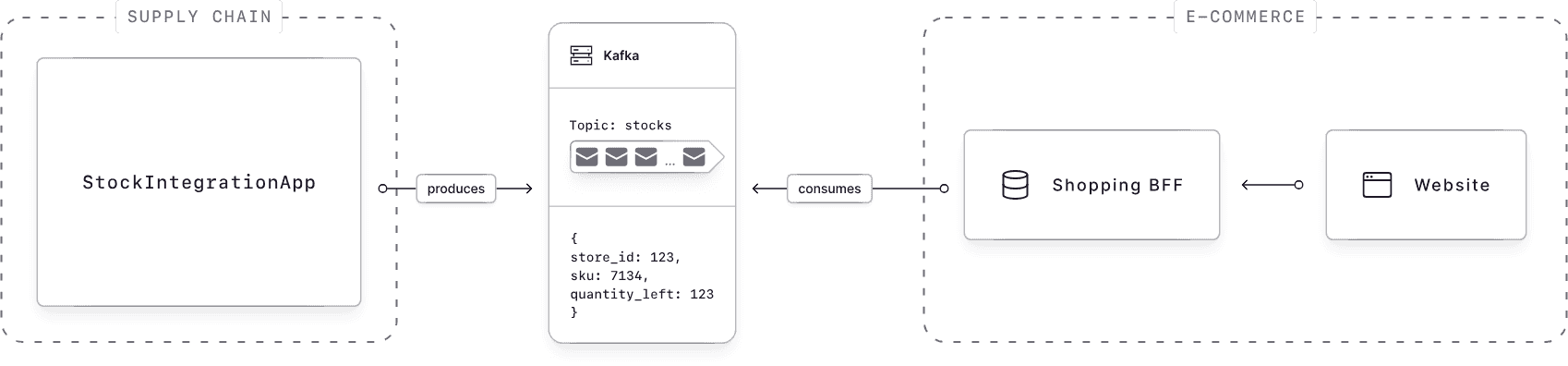
What looks simple on paper gets complex in production, especially at scale. Proper preparation and tools prevent costly mistakes.
Common Problems When Building Kafka Infrastructure
Kafka's flexibility makes it popular. But ad-hoc tooling creates problems.
Kafka's Learning Curve Slows Teams Down
Kafka requires understanding topics, partitions, offsets, schemas, producers, consumers, and streams. Teams that skip this foundation face data reliability problems and poor visibility. Without a clear overview of streaming processes, fixing issues like poison pills in Kafka becomes difficult.
Implementation Grows Beyond the Original Plan
Implementation usually starts with a specific use case. Development rarely follows a clear plan from day one.
Teams focus on proving value rather than planning for future challenges: new microservices, domains, applications, and resources.
What starts as a single business case grows uncontrollably once it proves value. New domains get added. More data intersections require more processing. This growth happens haphazardly.
Different Teams Have Different Needs
Real-time data streaming involves software developers, data engineers, DevOps, business analysts, architects, and support. These groups have differing goals: building applications, building pipelines, understanding data, standardizing processes.
Complexity Compounds With Each New Domain
As your streaming ecosystem grows, each new domain adds data intersections and processing requirements. This demands more advanced streaming knowledge applied to different use cases. Central teams cannot manage this alone.
Security and Compliance Get Treated as Afterthoughts
With massive data leaks worldwide, Kafka security cannot be an afterthought.
Apache Kafka secures network communications with TLS or mTLS but lacks native field-level data encryption. This exposes personally identifiable information (PII) and data covered by GDPR or CCPA, especially as new producers and consumers are introduced.
Ignoring this when designing pipelines creates technical debt and last-minute patches. Oversights lead to higher costs and regulatory exposure.
Human error at this marketing analytics firm earlier this year led to sharing sensitive data. A vulnerable Kafka broker leaked private information of over a million users.
Seven Factors for Evaluating Tooling Options
Planning determines how easily you scale. Assess these areas when evaluating options:
- Observability: Monitor and understand internal states by analyzing outputs for fast issue resolution.
- Organizational knowledge: Team awareness of the tool and how to optimize it for your needs.
- Velocity: Speed of delivering new features or updates.
- Cost: Total cost including licensing, implementation, time, and resources.
- Maintenance: Ongoing overhead for updates, fixes, and optimization.
- Security: Measures protecting tools and data from unauthorized access and threats.
- Governance: Policies and controls ensuring proper management and compliance.
Some priorities conflict, usually cost versus security. Weigh them for your specific context.
Comparing Tooling Approaches
Kafka's Command-Line Interface
The CLI works for learning and small projects. It won't scale for large production systems.
Custom-Built Tools
Custom tools start nicely. Teams create solutions molded around their needs.
The downsides emerge over time: maintenance burden, integration costs, and distraction from core business. Building custom tools makes sense only when no existing solution serves your needs. That's rare in 2024.
Custom tools should be glue between internal repos, services, and existing tooling. Nothing more.
GitOps for Kafka Governance
Using Git repositories as a single source of truth for infrastructure as code (IaC) solves many Kafka governance and scaling issues.
GitOps standardizes and systematizes requests, making them testable and auditable. You validate requests against business policies. Ownership moves from the central platform team to the requestor.
GitOps alone doesn't solve all challenges, especially as operations grow.
Third-Party Development and CI/CD Tools
Docker for containerization, Jenkins for CI/CD, Lens for K8s: third-party tools support all actors building data pipelines. For Kafka, these tools automate deployment and testing while increasing visibility and reliability.
Your team focuses on core business while tools provide maintenance, updates, documentation, and integrations. Introducing tools early, especially those automating governance and security, prevents costly issues later.
GitOps Plus Third-Party Tools Works Best
Once past proof of concept and into production, combining GitOps with third-party tools empowers teams. GitOps provides a single source of truth and standardizes processes. Tools solve diverse problems different teams face.
This requires upfront investment. It saves trouble long-term. Security issues will haunt you at scale unless you build in the mechanisms from day one.
Conduktor adds logic on top of your existing Kafka deployment. The proxy provides functionality unavailable natively: end-to-end encryption, RBAC, and data masking controls.
Check the demos to see how Conduktor Gateway can help.
Getting Started
Implementing Kafka comes with a steep learning curve and multiple challenges.
GitOps combined with third-party tools provides the best mix of visibility, flexibility, reliability, and security. This combination delivers standardization, automation, governance, and support for frictionless scaling.
Start small with a proof of concept. Scale up with careful planning.
Try Conduktor to optimize your Kafka security and governance at scale.