Schemaless data structures emerged from the NoSQL wave of the 2010s. Relational databases couldn't easily scale or accommodate different data formats. The solution: do away with schemas altogether.
The results were mixed. Ingesting all types of data without schema validation simply delays the problem, forcing teams to clean up messy data after the fact. Schemaless databases needed validation mechanisms, or they would break downstream applications.
Kafka Transmits Bytes, Not Schemas
Kafka was designed to move data quickly and asynchronously between producers and consumers. It supports JSON, Protobuf, Avro, CSV, strings, XML, and more. Enforcing schemas would slow things down, so Kafka transmits data as byte arrays and ignores the content within.
This flexibility is valuable for prototyping, spinning up test environments, or internal projects where schema enforcement adds friction. Kafka's format-agnostic design makes it an excellent data backbone for connecting stores, sources, and sinks across any digital environment.
When Schema Enforcement Becomes Necessary
Skipping schema validation works for experiments and internal communication. In production, you pay for it later.
Incompatible message formats create knock-on effects for downstream applications. Consider an analytics application at a government institution that ingests an age value of 200 years. The application breaks. Engineers must manually comb through data to find the offending record.
Schema enforcement improves observability. Structured data enables searches, queries, troubleshooting, and auditing. Without clear data formats, isolating individual messages by field or value becomes difficult.
Encryption depends on schema too. Developers need to know which fields to obscure and how to monitor data flows for GDPR, HIPAA, or CCPA compliance.
Forward and backward compatibility also requires schema management. Without a registry to ensure logical schema evolution, applications might not access older or newer data. If an energy provider buys solar panels that generate new metrics with different firmware, the schema must be updated, or analytics and AI lose key context.
How Schema Registries Prevent Breaking Changes
Some Kafka distributions include schema enforcement tools. Confluent's Schema Registry is the most popular. It centrally stores and versions schemas, validates data during production and consumption, and checks for compatibility. This enables schema evolution so old and new devices can work together.
Schema Registry provides a solid foundation for implementing contracts and data structures throughout your Kafka environment. But for large, complex environments that require guaranteed data quality, additional tooling fills the gaps.
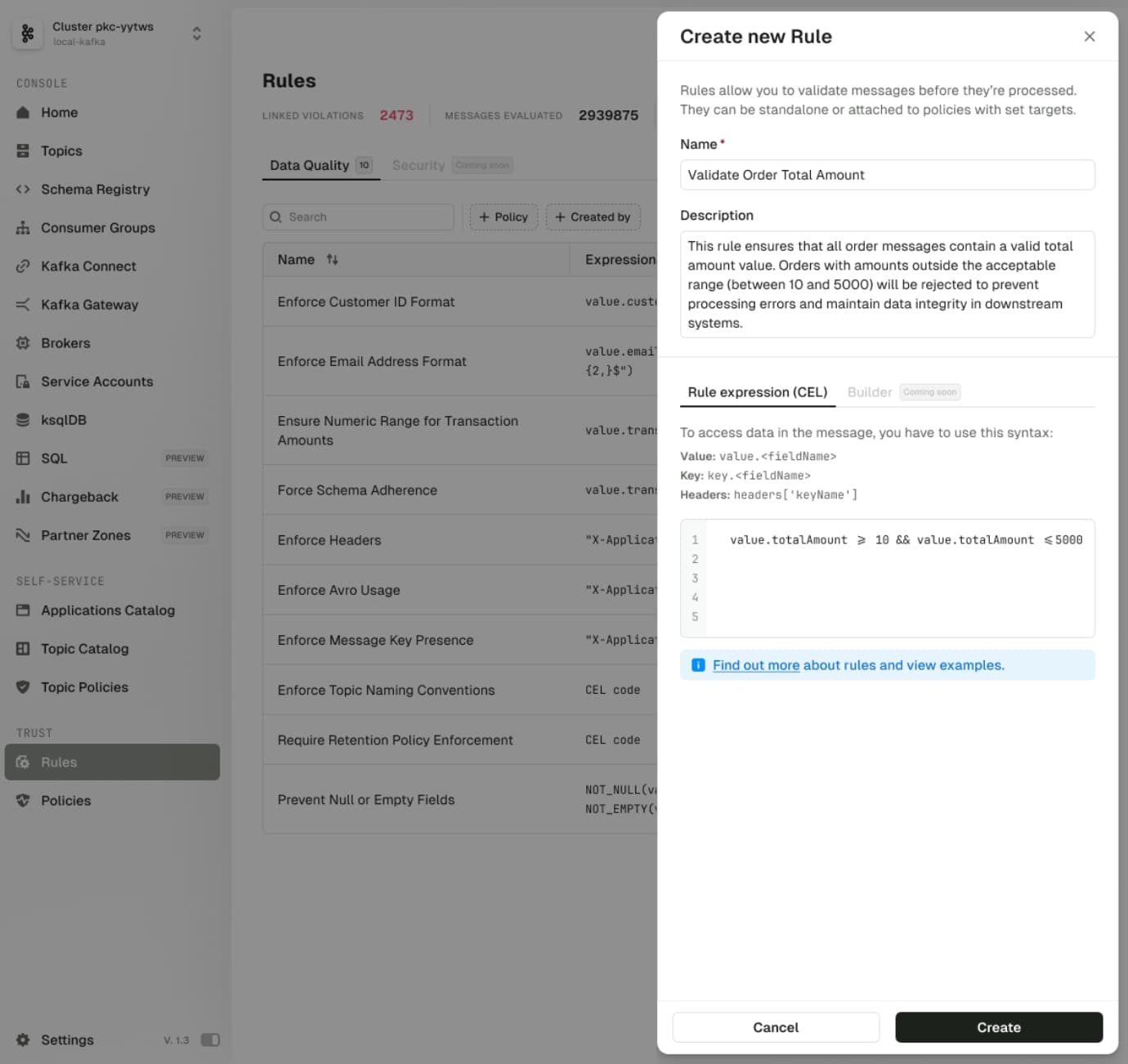
How Conduktor Trust Validates Data Before It Enters Pipelines
Trust applies validation at the producer level, preventing bad data from polluting pipelines. Teams set custom rules to block malformed data before it enters the system.
For the age validation problem: a team could use Trust to limit age values to 100 (or 115 at maximum). Trust requires no changes to existing producers, so you can add it with minimal overhead for observation before action.
Trust provides observability into rule violations. Teams monitor violation frequency and identify originating topics. Excessive violations indicate something is broken on the producer side and may trigger investigation. Alerting on rule infractions enables rapid response.
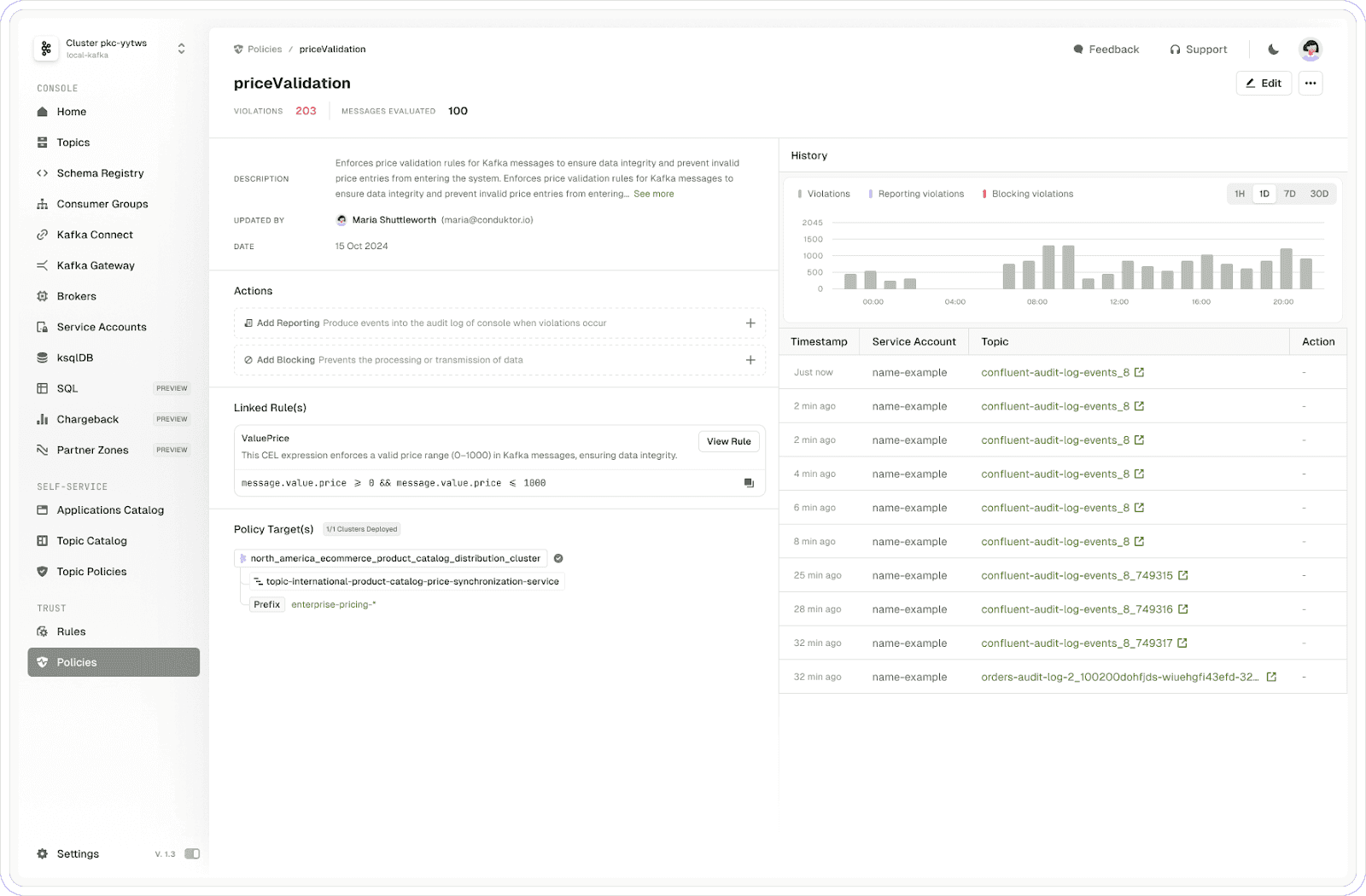
Trust works with schemaless data structures. User-defined rules apply to schemaless topics, validating and blocking malformed fields or payloads without requiring schema. For other schemaless topics, Trust dynamically infers schema, mapping key fields like orderIDs and transaction amounts and enforcing rules based on that understanding.
Schema Requirements in Production Kafka
Kafka's flexibility comes from ignoring data schema. Real-world production shows that structure is essential for data quality, observability, and compliance at scale.
Schema Registry validates and evolves schemas but may not include monitoring, auditing, or alerting. It may not work with schemaless topics.
Conduktor Trust validates data proactively: applying custom rules, blocking bad messages before they enter pipelines, and working with schemaless topics by inferring structure dynamically. Even if Kafka doesn't require schemas, your applications and operating conditions do. Trust enforces them where it counts.
To see what Conduktor can do for your environment, sign up for a free Trust demo.