Data mesh is a paradigm that decentralizes data ownership and governance, enabling data domains to share and collaborate.

Stéphane Derosiaux
4 mai 2023

Data mesh is a modern approach to managing data in large organizations that aims to increase agility, autonomy, and scalability by decentralizing data ownership. The idea of data mesh was first proposed by Zhamak Dehghani, a software architect at ThoughtWorks, in a blog post published in May 2019. Since then, the concept has gained significant traction among data and technology leaders who recognize the limitations of traditional centralized data management approaches.
The data mesh concept shares many similarities with domain-driven design (DDD) and Microservices principles. Both of these approaches prioritize the autonomy of individual teams and the modularization of complex systems. Data mesh is a paradigm shift from the traditional centralized data warehouse or lake approach, where data is collected and processed in a single location by a dedicated team. Data mesh advocates treating data as a product that can be owned, governed, and delivered by different domain teams across the organization. This way, data can be more accessible, reliable, and relevant for various use cases and stakeholders.
The core principles of Data Mesh
Data mesh is based on the following core principles:
Domain-oriented decentralized data ownership - Data should be owned by the domain experts who understand it best rather than by a central data team. This approach encourages autonomy and accountability and helps ensure that data is accurate, relevant, and up-to-date.
Data as a product - Data should be treated as a product that is designed, developed, and maintained by domain-oriented teams, with a focus on delivering value to internal and external customers. This approach fosters a product mindset and encourages a culture of experimentation, iteration, and continuous improvement.
Federated data architecture - Data should be organized in a federated architecture, where data products are discoverable, reusable, and composable. This approach promotes modularity, interoperability, and scalability, enabling teams to collaborate and share data effectively.
Self-serve data infrastructure - Teams should have access to self-serve data infrastructure to easily discover, access easily, and process data. This approach reduces dependencies on centralized data teams and empowers domain-oriented teams to quickly and independently create and iterate on data products.
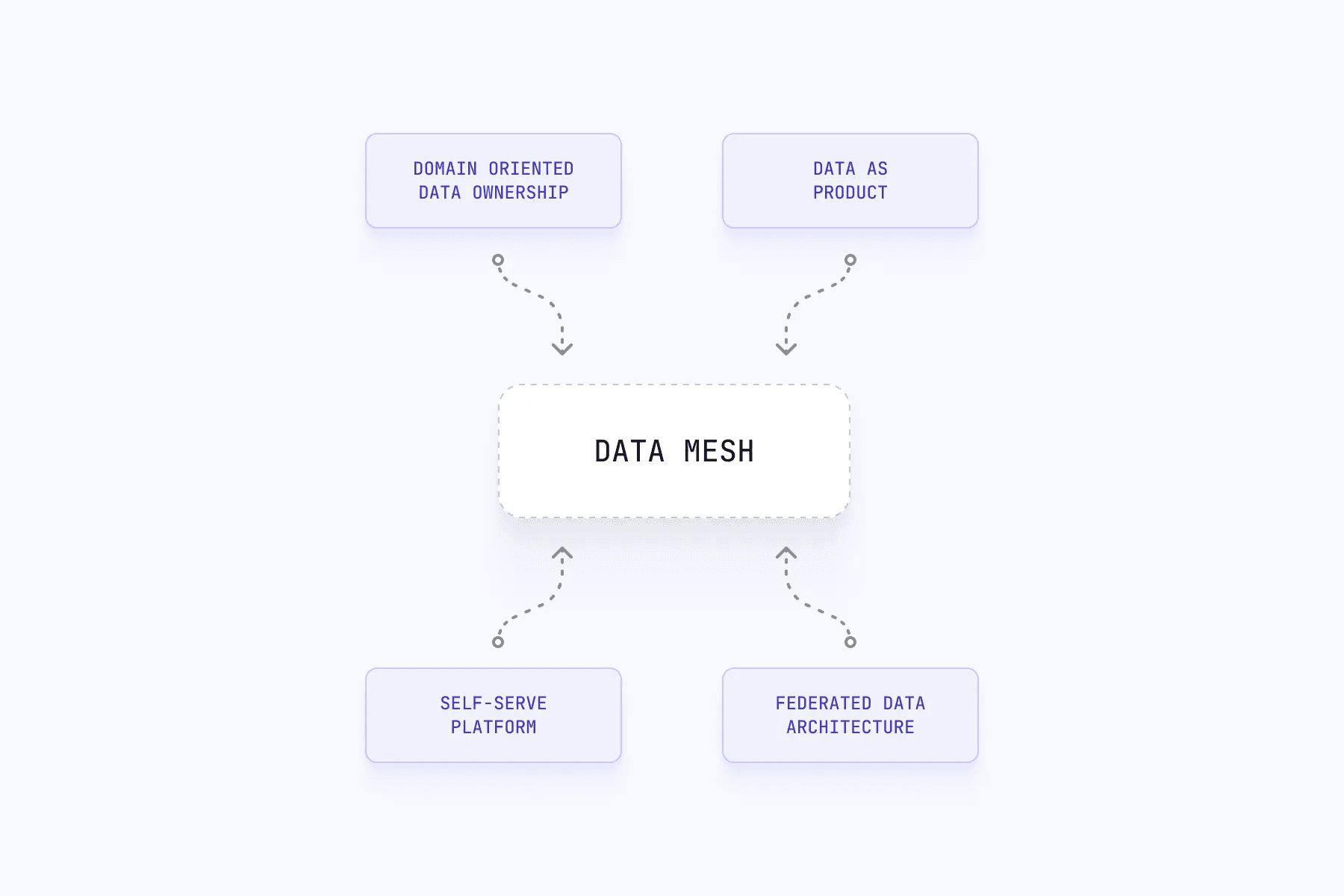
Logical architecture of Data Mesh
The core principles mentioned above encourage us to visualize data mesh as a set of self-contained entities covered with a connecting tissue that shares the features in common. This understanding is quite different from the centralized monolithic architecture we observed in traditional data platforms. At a high level, the architecture consists of four main components:
Domain-Oriented Teams: These are teams that are responsible for developing and maintaining specific data products within their domain. Each team has a clear understanding of the business domain they serve and is empowered to make decisions about the data products they develop.
Data Products: These are self-contained, modular pieces of data infrastructure that are developed by domain-oriented teams. Each data product is designed to solve a specific business problem and is responsible for its own data quality, governance, and delivery.
Platform Services: These are services that provide infrastructure and support for data products, such as data storage, compute, and security. Platform services are owned and managed centrally to ensure consistency across domains.
Data Mesh Bus: This is a shared communication layer that enables data products to communicate with each other and with external systems. The data mesh bus allows data products to be composed and orchestrated to solve more complex business problems.
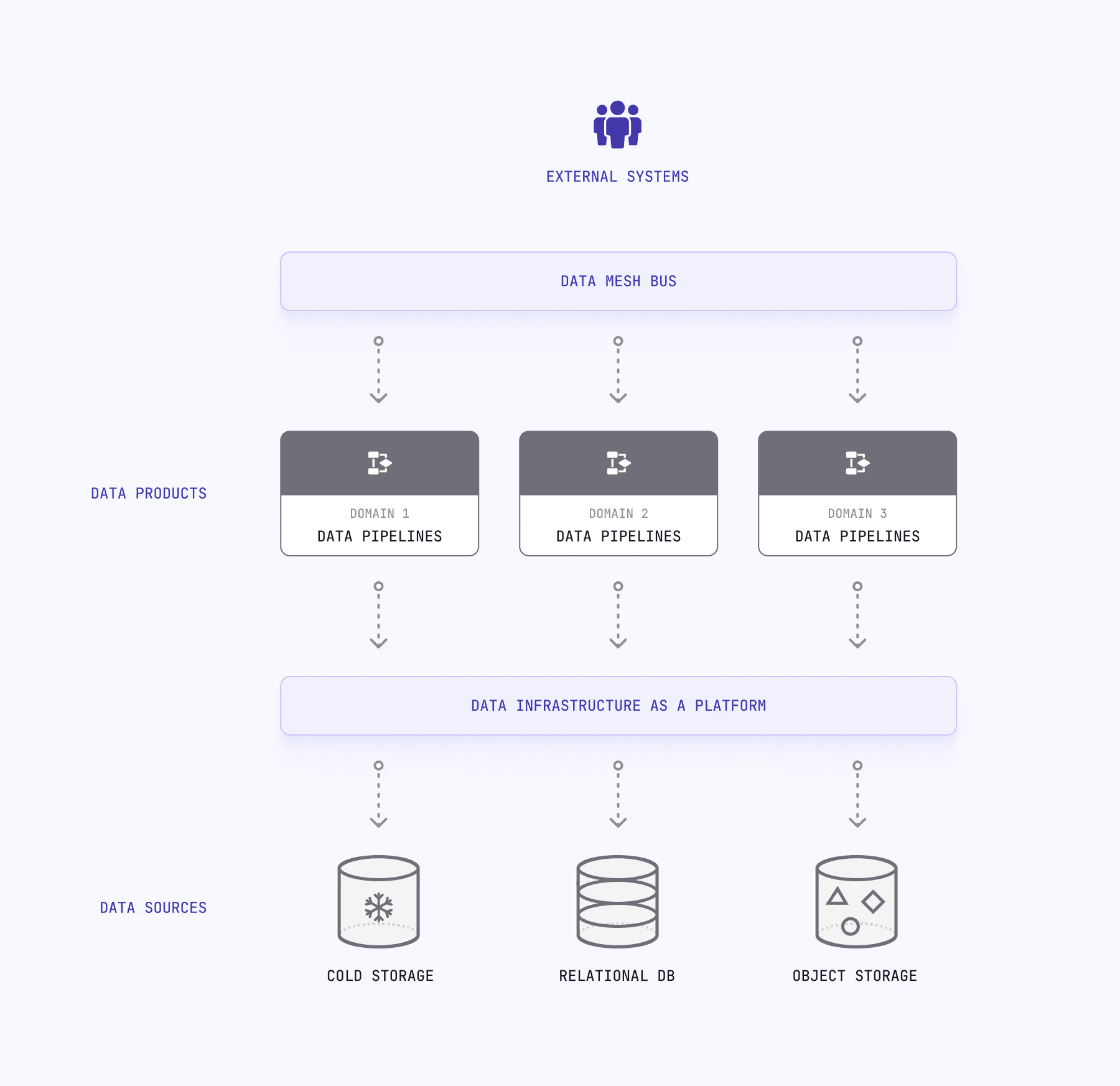
Data mesh architecture is inherently distributed and decentralized. By decentralizing data ownership and management, domain-oriented teams can develop data products that better align with the needs of the business and deliver value faster. The platform services provide the necessary infrastructure to support data products, while the data mesh bus allows data products to be composed and orchestrated to solve complex business problems.
Domain-oriented data ownership and data pipelines
The term domain in data mesh represents individuals with a common business function—for example, sales, marketing, customer service, and more—providing more ownership to the data they produce.
Domain-oriented data ownership--a key pillar in data mesh, means that data is owned by the domain experts who understand it best. This approach promotes autonomy and accountability, ensuring data is accurate, relevant, and up-to-date. Domain-oriented teams own and develop data products that serve specific business needs, promote a product mindset, and focus on delivering value to internal and external customers.
To support domain-oriented data ownership, data mesh promotes the use of data pipelines. Data pipelines move data from its source to its destination, a data product, or another system. These pipelines can be developed and managed by domain-oriented teams, which reduces dependencies on centralized data teams and promotes agility and autonomy.
Why Data Mesh?
Traditionally, the data platform of an organization was centered around a data warehouse, which was maintained by a central data team. These teams were small and composed of a handful of specialists. As the organizational data volume grows, these teams are often disrupted by fulfilling ever-increasing data requests.
These traditional architectures were often slow to adapt to changing business needs and market conditions. Centralized data teams are often responsible for managing data infrastructure and developing data products, which can create bottlenecks and dependencies. This can lead to long development cycles, slow time-to-market, and an inability to respond quickly to changing business requirements.
Moreover, siloed data is another problem in traditional data architectures. The data is often siloed by department or function, which can lead to duplication of effort, inconsistencies in data, and a lack of collaboration and knowledge sharing.
Data mesh addresses these problems by promoting domain-oriented data ownership and developing domain-oriented data products. That encourages collaboration and knowledge sharing across domain-oriented teams and promotes creating reusable data products that can be shared and reused across the organization.
Do I need a Data Mesh?
Whether or not your organization should start using a data mesh architecture depends on several factors, such as the size and complexity of your organization, the current state of your data architecture, and the availability of the necessary technical skills and resources.
Before adopting a data mesh architecture, it's important to consider the following critical factors:
Business Needs: Consider whether the benefits of a data mesh architecture align with the business needs and objectives of your organization. For example, if your organization values autonomy and agility and operates in a dynamic and fast-paced environment, a data mesh architecture may be a good fit.
Organizational Structure: Consider the current organizational structure of your company and how it aligns with a data mesh architecture. Data mesh requires domain-oriented teams with strong data expertise and a culture of collaboration and knowledge sharing. It's important to evaluate whether your organization has the right structure and culture to support a data mesh architecture.
Technical Skills and Resources: Consider the technical skills and resources needed to implement and maintain a data mesh architecture. Data mesh requires a combination of technical skills, such as data engineering, data science, and DevOps, as well as the necessary technical infrastructure, such as cloud computing and big data technologies.
Data Governance: Consider how a data mesh architecture will impact data governance. Data mesh requires strong data governance practices to ensure data quality, consistency, and security. Evaluating whether your organization has the necessary policies, processes, and tools to support data governance in a data mesh architecture is important.
Change Management: Consider how a data mesh architecture will impact your organization's culture and workflows. Adopting a data mesh architecture requires significant changes in managing and processing data. Planning for change management, including training and communication, is important to ensure successful adoption.
Why should data observability co-exist with a Data Mesh?
Data observability is the practice of measuring, monitoring, and understanding the behavior of data in real-time to ensure that it is accurate, complete, and consistent. When you have a data mesh architecture in place, consider cultivating a good data observability practice. It ensures that the data products developed by domain-oriented teams are of high quality and meet the organization's needs.
A solid data observability practice enables domain-oriented teams to monitor the quality and behavior of their data products in real-time, allowing issues and errors can be quickly identified and addressed before they become bigger problems. That also ensures data products are consistent and adhere to established data governance policies.
Another benefit is that it promotes transparency and trust. When domain-oriented teams have visibility into the behavior of their data products, they can share this information with other teams and stakeholders. This promotes collaboration and knowledge sharing and helps build trust in the data products developed by domain-oriented teams.
Data observability also enables organizations to improve the performance of their data products. By monitoring the behavior of data products in real time, organizations can identify bottlenecks and inefficiencies in their data pipelines. This information can then be used to optimize data pipelines and improve the performance of data products.
Benefits of Data Mesh
Improved agility: Data mesh enables organizations to quickly adapt to changing business requirements and market conditions by promoting autonomy and decentralization. Domain-oriented teams can independently develop and iterate on data products, reducing dependencies on centralized data teams and increasing agility.
Better data quality: Data mesh promotes domain-oriented decentralized data ownership, which helps ensure that data is accurate, relevant, and up-to-date. This approach fosters a culture of accountability and encourages domain experts to take ownership of their data.
Faster time-to-market: Data mesh enables teams to quickly create and iterate on data products, reducing the time to market for new products and services. This approach also fosters a culture of experimentation and innovation, which can help organizations stay ahead of the competition.
Increased scalability: Data mesh promotes a federated data architecture, which enables teams to share and reuse data products across the organization easily. This approach promotes modularity, interoperability, and scalability, enabling organizations to scale their data capabilities as needed.
Better collaboration: Data mesh encourages collaboration and knowledge sharing across domain-oriented teams, reducing silos and promoting cross-functional teams. This approach also fosters a culture of transparency and openness, which can lead to better decision-making and increased trust.
Improved data governance: Data mesh promotes governance at the domain level, which helps ensure that data is managed in a secure, compliant, and ethical manner. This approach also enables organizations to manage data privacy and regulatory compliance requirements better.
Conclusion
The rising significance of data mesh is driven by the need for organizations to manage large, complex data systems in a way that is scalable, flexible, and resilient. As more and more organizations adopt cloud-based architectures and microservices-based approaches, the need for a decentralized approach to data management becomes increasingly important.
Apache Kafka is a natural fit for the data mesh architecture because it provides a highly scalable, distributed, and fault-tolerant platform for managing streaming data. By using Kafka as the backbone of the data mesh bus, organizations can create a flexible, decentralized architecture that allows domain-oriented teams to own and manage their data products while still ensuring that data is available and accessible across the organization.
Conduktor is an enterprise-grade platform for Apache Kafka that provides tools for monitoring, managing, and developing Kafka-based applications. We provide a centralized platform for managing Kafka-related tasks related to the data mesh, including real-time monitoring of Kafka clusters and topics, schema management for Kafka data, and tools for managing Kafka-based workflows, while still allowing individual domain-oriented teams to own and manage their data products. This aligns with the data mesh philosophy of decentralized data ownership and management, while still providing the necessary infrastructure and governance to ensure data quality and security.
Conduktor's Topic as a service (TaaS) crystalizes this philosophy by giving developers from individual teams the power to create, update, share, and promote Kafka resources with the automated blessing of the central platform team.