
Real-time data quality in Apache Kafka directly affects your data infrastructure performance and business outcomes. How can Kafka platform teams ensure high quality data at scale without becoming bottlenecks, while keeping application teams responsible for their own data?
This article covers common data quality issues, remediation techniques, and how to implement automated quality monitoring without disrupting Kafka operations.
Poor Data Quality Breaks Downstream Systems
Data quality issues compound. Invalid data causes applications to crash. Crashes cascade into dependent systems. Your team scrambles to fix problems while business stakeholders wait.
Kensu research shows 85% of data management leaders have made improving data quality their highest priority.
The DBT state of analytics engineering report reveals why: unclear data ownership (50% of respondents) and poor quality data at the source (57%) are the biggest problems data teams face. Over half of analysts can't complete their work because of data quality issues.
Why Kafka Makes Data Quality Harder
Kafka sits at the center of your streaming architecture. It enables upstream data quality issues to propagate downstream.
Kafka lets producers put anything into a topic. When messages match expected formats, everything works. When a producer starts outputting invalid data, things break fast.
Producers fail for many reasons: bad inputs, misconfigurations, bugs, inexperienced users. Teams scramble to fix the issue before downstream consumers are affected. Root cause analysis takes additional time.
Kafka's permissiveness is intentional. The flexibility that lets it serve as your data backbone also makes it an ideal place to centrally monitor and catch data quality issues before they spread.
Common Data Quality Failures

The most common causes of poor quality data in Kafka:
- Invalid message: Data differs from what downstream applications expect. Example: a consumer expects an IBAN but receives a license plate number.
- Missing or unknown schema: The schema reference is missing, points to a deleted schema, or references the wrong one.
- Wrong format: Data has the intended content but wrong serialization. Expected Avro, got JSON.
- Invalid data values: Values satisfy the schema but fail business logic. Example: an IBAN with invalid check digits.
Standard Guardrails Are Not Enough
Standard protections handle individual issues but don't prevent bad data from entering the system:
- Log and skip: Skip problematic messages and log them for later review (which rarely happens). Requires every consumer to handle errors gracefully.
- Manual intervention: Crash on failure, restart, try again. Time-consuming and error-prone. Incorrect offset manipulation causes either reprocessing of bad data or data loss.
- Dead letter queue (DLQ): Route failed messages to a separate topic for inspection. Best practice, but debated whether to implement on producer or consumer side. If only producers implement DLQ, consumers may skip error handling, causing problems when bad data slips through.
- Schemas: Define what data should look like. Non-conforming data is rejected. Schemas don't catch invalid values that follow the correct structure.
These approaches don't prevent bad data from being introduced. A single misbehaving producer can break everything.
Using a Proxy Layer for Quality Enforcement
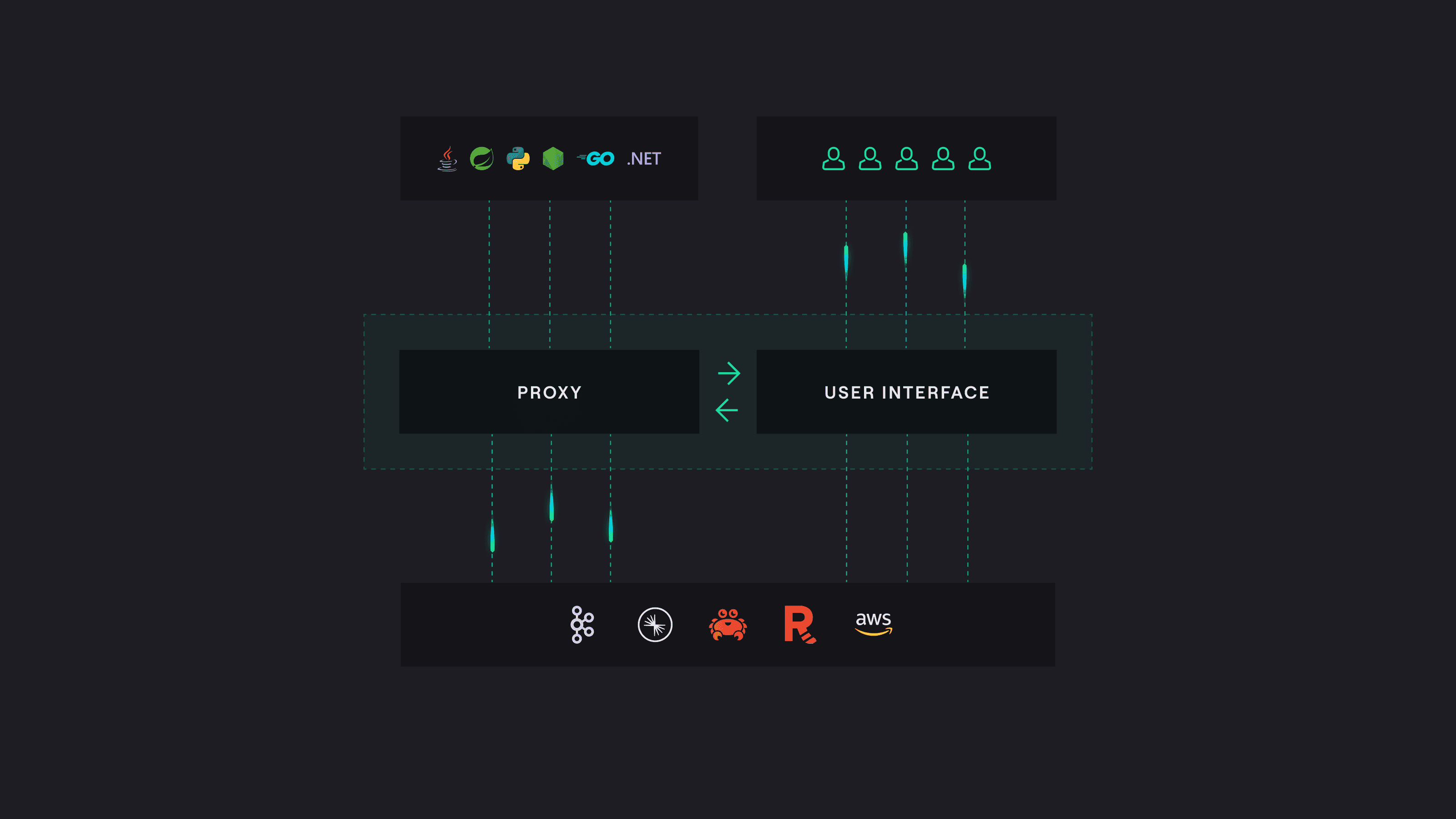
Instead of relying on every actor to behave correctly, use a middleware approach to enforce data quality at scale.
Conduktor's Kafka proxy lets producers and consumers connect the same way as a Kafka cluster. It validates payloads, checks schemas, and runs data quality rules before records reach your actual Kafka infrastructure.
This approach fixes issues for all users at once. No application code changes required beyond pointing at the proxy.
You can validate payloads against schemas or define SQL statements to assert data quality. Schema ID validation ensures messages conform to a schema and that the schema exists in the registry. Conduktor makes the schema the contract, letting you embed business logic directly.
This adds infrastructure to manage. The tradeoff is worth it: centralized enforcement scales better than distributed error handling across every producer and consumer.
Scaling Quality Enforcement with Data Mesh
Your data quality tools should reduce operational overhead so teams can focus on improving data processes.
Don't push data quality responsibility downstream. Automate processes where possible. Assign topic ownership to teams with the most context: where data comes from, what it should look like, what it will be used for.
This is the core of data mesh. When data ownership is clear and management is distributed, teams can enforce quality standards for the data they know best. They can identify invalid values and trace likely causes faster than a central team ever could.
See how FlixBus built their self-service data streaming platform or book a demo to see data quality enforcement in action.