
Kafka adoption follows a pattern: a few clusters become dozens, a few topics become thousands, a few apps become hundreds. Growth is good, but costs grow with it.
This guide covers eight ways to reduce Kafka expenses using Conduktor Gateway, a Kafka proxy that sits between your apps and brokers.
Replace Physical Clusters With Virtual Clusters
Companies accumulate clusters for historical, technical, or political reasons. Dozens or hundreds of clusters, each costing money whether self-hosted (maintenance, support, tooling) or managed (AWS MSK, Confluent, Aiven).
Conduktor Gateway creates virtual clusters on a single physical cluster. Same isolation, same user experience, fraction of the infrastructure.
You choose when to use physical vs. virtual. Virtual clusters reduce infrastructure costs, installation costs, and monitoring overhead. Bootstrap a new cluster with one API call instead of a procurement process.
Cache Data to Cut Networking Costs
If your Kafka provider lives outside your VPC, you pay networking costs and latency penalties for every round trip.
Gateway sits between clients and clusters. Deploy it close to your applications, and it caches immutable Kafka data locally.
First request fetches from Kafka. Subsequent requests for the same data hit the cache, bypassing external network traffic entirely. Use the sidecar pattern in Kubernetes and latency drops to localhost. See the caching interceptor.
Enforce Compression at the Gateway
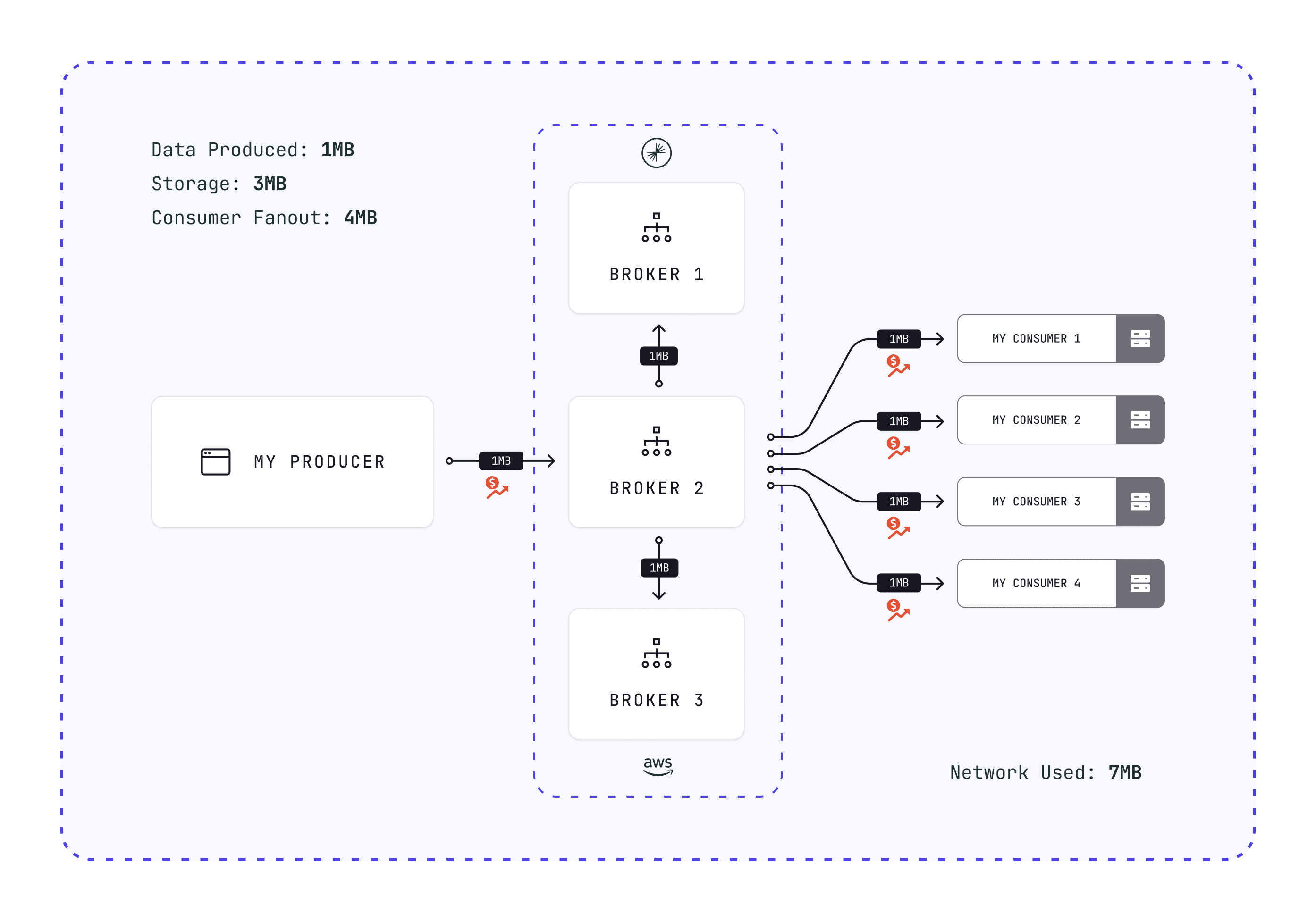
Storage cost compounds. A 1 MB batch:
- Moves over the network to Kafka: 1 MB
- Replicates to other brokers: 2 MB networking
- Flushes to disk on each machine: 1 MB storage per replica
1 MB produced = 3 MB storage + 3 MB networking. Four consumers add 4 MB more.
Compression can reduce this 10x. But enforcing compression across an organization is hard without tooling.
Conduktor Gateway's compression interceptor enforces compression at production time. A 1 MB batch becomes 100 KB.
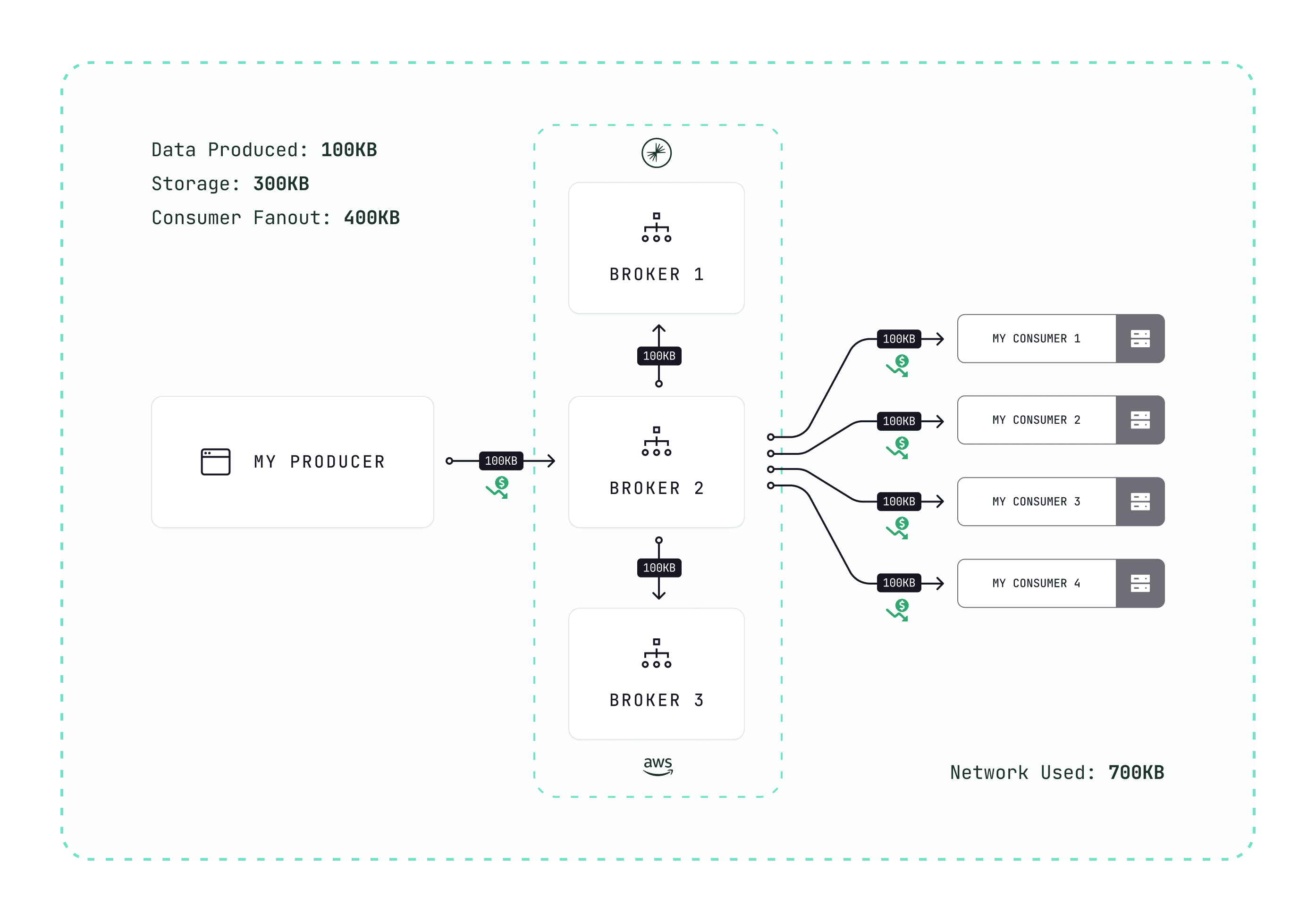
Results:
- 10x less networking
- 10x less storage
- Faster transfers, lower latency
Prevent Partition Sprawl at Creation Time
Partitions cost money. Typical pricing: $0.0015/partition/hour.
- 1,000 partitions = ~$1,000/month
- 10,000 partitions = ~$10,000/month
This excludes base costs, networking, storage, and services.
GitOps helps, but developers bypass it. Kafka Streams and ksqlDB create topics dynamically. The topic creation interceptor enforces limits at creation time.
Developers who need exceptions have a conversation with the platform team. Everyone else stays within guardrails.
Concentrate Topics to Eliminate Partition Costs
CDC tools like Debezium create hundreds of topics with thousands of partitions. Most go unused because the underlying tables rarely change. You still pay for them.
Topic concentration maps multiple virtual topics onto a single physical topic. Applications create and consume topics as usual. Behind the scenes, partition costs collapse.
Unlimited virtual partitions. Fixed physical cost. Contact us to try it.
Proactively Block Developer Mistakes
Developers cost more than infrastructure. Few receive Kafka training. They learn on the job, and mistakes compound.
Common problems:
- Infinite retention without realizing it
- 1,000-partition topics
- Missing
acks=all+min.insync.replicas=2 - Schema violations that crash consumers
Fixing these in production is expensive. The original developers may be gone. Teams have evolved. You inherit technical debt with no context.
Conduktor Safeguard intercepts requests before they hit Kafka. Enforce rules proactively:
Replace ACLs With Real RBAC
Kafka's ACL model (who can do which action on what resource) is basic. Organizations build custom RBAC systems on top, integrate with their IDP, maintain GitOps, document it, train teams.
This becomes a bottleneck. More clusters, more requests, more overhead. Hire more people, repeat.
Conduktor Gateway provides RBAC across all your Kafka infrastructure. Connect to your IDP/LDAP, configure groups and permissions, done. It abstracts provider-specific security (Confluent Cloud, Aiven) so you define policies once.
Handle Large Messages Without Breaking Kafka
org.apache.kafka.common.errors.RecordTooLargeExceptionKafka rejects large messages by design. This protects the cluster but frustrates developers.
Workarounds exist:
Chunking: Split the file into pieces, reassemble on consume. Fragile and error-prone.
Claim Check Pattern: Store the file in S3, send a reference to Kafka. Producers and consumers need S3 credentials. Another secret management problem.
Conduktor Gateway's cold storage: The Cold Storage Interceptor implements claim check automatically. Producers send files of any size. Consumers fetch records normally. Gateway handles S3 transparently.
Only Gateway needs S3 credentials. No application changes. No governance overhead.
PII and GDPR Compliance Without Application Changes
Sensitive data access requires control and audit. Common approaches:
Filter and project: Build applications that create sanitized topic copies. This duplicates data, complicates security, increases costs, and creates dependencies.
End-to-end encryption: Cross-cutting concern that developers implement poorly. Java library works, then the Rust team needs a port. Interoperability testing begins. KMS governance becomes your problem.
Conduktor Gateway's field-level encryption handles this transparently. No application changes, no secret distribution, no language-specific libraries.
These eight approaches target the real cost drivers: cluster sprawl, storage, networking, partitions, developer mistakes, security overhead, and compliance complexity. Contact us to discuss your specific situation.