
Data sharing is on every enterprise roadmap, yet most teams can't share a live stream outside their own network. I've been talking to platform teams and enterprise architects for years, and when I ask "how do you share your streaming data with external partners today?", the most common answers are: "we dump CSVs on an SFTP", "we spin up a separate cluster", or simply "we don't". These teams aren't thinking about data monetization. They're fighting to get data outside their own network without creating a security incident.
The requests come from everywhere: supply chain partners needing real-time updates, financial institutions running credit checks, marketing agencies building audiences, regulators requiring audit trails. Different partners, same underlying problem.
The gap between "we have raw streams" and "we sell data products" isn't one step. It's four, and each one depends on the previous.
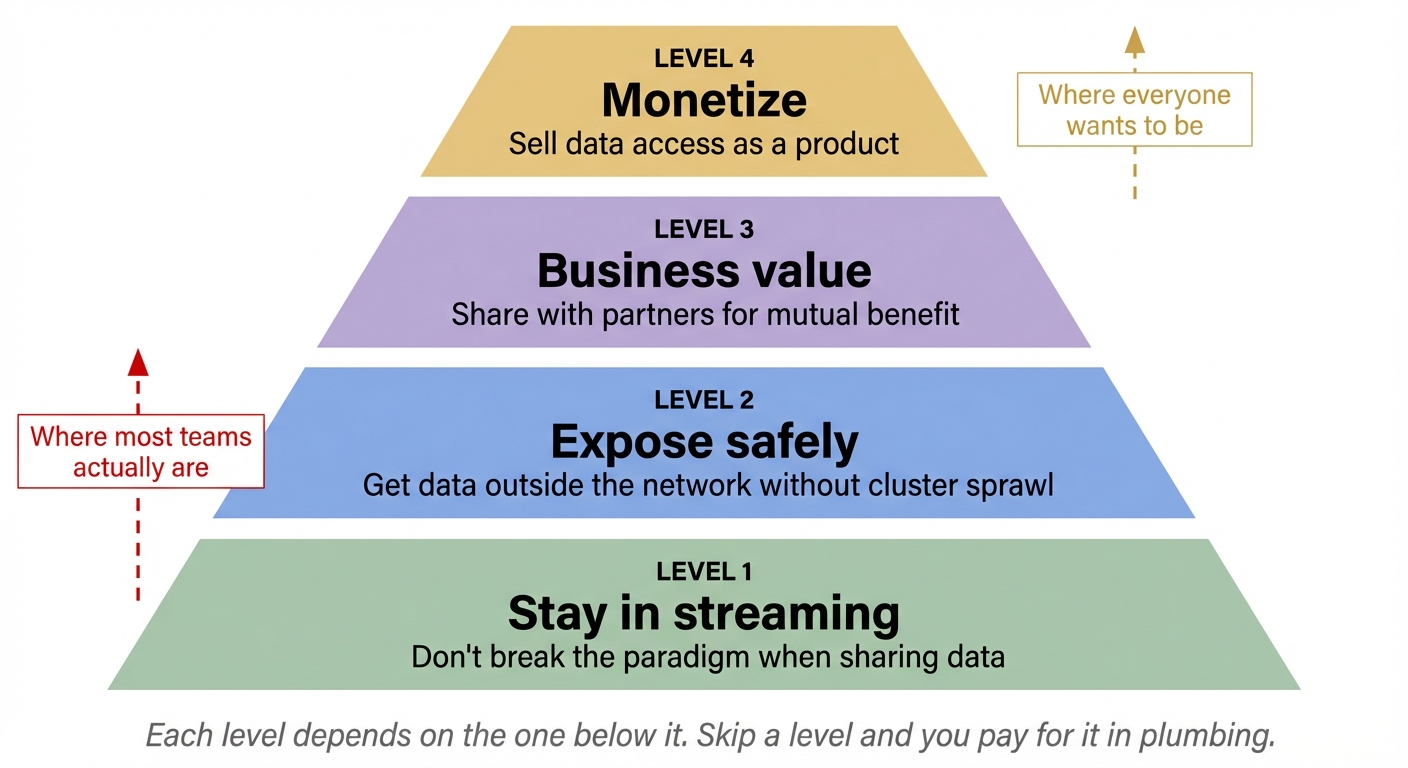
Level 1: keep your data in streaming when sharing it
You have Kafka. Data flows in real time. Your internal consumers depend on that. Then someone says "we need to share this with a partner" and the first reaction is to reach for what the team already knows: dump it to a file, expose a REST API, schedule an ETL job. Something familiar, something that doesn't require giving an external party access to your Kafka cluster.
Export means ETL. ETL means batch. Batch means you now have a CSV on an SFTP that's six hours stale. Your partner polls a REST API every 15 minutes instead of consuming a real-time stream. You've built a reconciliation pipeline to detect what the batch process missed. You're maintaining two parallel worlds: streaming internally, batch externally.

What you lose when you export:
- Real-time delivery. Your partner can act on events immediately instead of waiting for two batch jobs: one on your side to export, one on theirs to import. That's the difference between reacting to something as it happens and discovering it hours later.
- Schema as a contract. With Schema Registry, you can't break your partners. Schema compatibility is enforced automatically: you change a field, the registry tells you if it breaks consumers before it reaches them. Partners should have access to the schema registry too, so they can discover what's available and validate their consumers against it. We offer a Schema Registry Proxy for this. Without any of this, the structure of what you share lives inside ETL transformation rules that nobody owns, nobody reviews, and nobody notices until a partner's pipeline breaks.
The cost compounds. You're running a data streaming platform and a batch export pipeline side by side, both touching the same data, with separate infrastructure and separate on-call.
Staying in streaming means the partner consumes events through the Kafka protocol. Ordered, real-time, no batch intermediary. They don't need to know your cluster topology or partitioning strategy.
If your sharing layer introduces a protocol break, everything above this level falls apart. Levels 2, 3, and 4 assume the data is still streaming when it crosses the boundary.
Level 2: expose Kafka data outside your network
Your internal Kafka clusters sit inside a VPC. They're not internet-facing, and for good reason. No security team wants to open firewall rules to let a partner's consumer group connect to your production brokers. That conversation ends with "absolutely not."
The traditional answer: create a second Kafka cluster in a DMZ, replicate data from internal to external using MirrorMaker or Cluster Linking (we wrote about the proxy alternative), and have partners connect to the DMZ cluster.
This creates problems that scale with your partner count:

Per-partner clusters don't scale. Your first partner gets a dedicated cluster. By partner five, you're running five additional Kafka deployments with their own monitoring, patching, credentials, and capacity planning. On AWS, each MSK cluster with three brokers in three AZs costs roughly $1,500-3,000/month before storage. That's infrastructure cost to share data you already have.
The alternative: a Kafka proxy at the boundary. One gateway in front of your cluster, handling authentication, topic-level ACLs, encryption, rate limiting, and audit logging for all external partners. Each partner gets a partner zone: an isolated endpoint, scoped to specific topics, with its own credentials and audit log. Partners only see what you explicitly map into their zone. A misconfigured ACL on a physical cluster can expose everything; a partner zone can't leak topics that were never mapped. Your internal cluster stays untouched.
The gateway also handles topic aliasing: internal names like team-alpha.payments.raw-v3 stay internal. Partners see clean, documented topic names that don't reveal your org structure.
Exchange does this for any Kafka cluster (MSK, Confluent Cloud, Redpanda, or self-managed). No broker changes required.
Two use cases drive adoption at this level:
SaaS integration. A third-party tool needs to consume your events but can only connect to public Kafka endpoints. This includes customer 360 platforms, data enrichment services, but also data platforms like Snowflake or Databricks that ingest from Kafka. One of our banking customers hit this: their customer 360 platform and their data enrichment service both speak Kafka, but neither can reach a private cluster. The options were "open the firewall" or "build another cluster." Even here, you often want field masking so the external service only sees the fields relevant to its function. Once the gateway is in place, the HTTP adapters and batch export jobs your team built as workarounds can retire.
Cross-environment sharing. Multiple cloud regions, hybrid setups, or separate environments that need data flowing between them without a mesh of cross-cluster replication. We see this often with large banks where business units are treated in isolation, almost like external partners. Sometimes it's the result of an acquisition, sometimes it's a deliberate choice to keep regulatory perimeters separate. Either way, the data still needs to flow between them.
"We see an advantage in using the gateway in addition to making it easier — we can manage the failover for them."
— Platform architect at a large North American asset manager, on choosing a proxy over per-partner clusters
A misconfigured ACL on a physical cluster can expose everything. A partner zone can't leak topics that were never mapped into it. The blast radius is the difference between "we shared the wrong topic" and "we exposed the cluster."
Level 3: share Kafka data for business value
Levels 1 and 2 are plumbing. Level 3 is where data sharing starts to justify its own existence.
You're not connecting a SaaS tool anymore. You're sharing data with another company, and the data creates value that wouldn't exist without both parties.

Here's how our customers use it:
Retailer and logistics partner. The retailer has the data (inventory levels, order events, demand signals) but not the routing expertise. The logistics company has the optimization algorithms but needs the retailer's data to feed them. The retailer streams events to the logistics partner, who returns optimized delivery schedules. Both sides need each other, and the data flows in both directions through a shared streaming channel.
Bank-to-bank fraud detection. Two banks share anonymized transaction patterns so each bank's fraud model gets broader signal coverage. A fraudulent pattern invisible in bank A's data alone becomes obvious when combined with bank B's transactions. The data is anonymized and access-controlled at the Exchange layer before it crosses the boundary.
Airline and distribution platforms. An airline pushes booking availability and pricing to distribution partners like Amadeus. The distribution partner gets real-time inventory instead of batch feeds that were always slightly wrong (overbooking errors, phantom inventory). The airline gets broader reach without maintaining per-partner integrations.
"We're talking 50 to 100 thousand farmers logging into an app to see their real-time data."
— Platform lead at a global agricultural equipment maker, scoping partner zones for end-customer data
The difference from Level 2 is the nature of the relationship:
| Level 2 | Level 3 | |
|---|---|---|
| Partner type | SaaS tool / internal service | Another business |
| Direction | Mostly one-way | Often bidirectional |
| Data sensitivity | Operational | Business-critical, often regulated |
| Governance | ACLs and rate limits | Legal agreements, compliance, audit |
| Risk profile | Service disruption | Business liability, regulatory exposure |
| What's shared | Events from specific topics | Curated data products |
Chargeback and cost attribution matter too. When multiple partners consume from your infrastructure, you need to track who uses what capacity and charge it back to the right cost center (actual billing comes at Level 4).
Producer identity also becomes critical. When a partner produces messages, the gateway automatically injects their identity as a message header, without relying on the partner to self-report. Native Kafka has no equivalent: if you want producer attribution across partners, you're trusting them to tag their own traffic.
And when a partnership ends, you need to cut access cleanly and verifiably. Partner-level isolation, not just ACL removal. A data leak to a partner's competitor is regulators at your door, so the scrutiny before a single message flows is on a different scale from Level 2.
Level 4: monetize streaming data (the horizon)
Data as a product. Streaming marketplaces. Revenue from access. Some organizations are actively working toward it. A large bank I spoke with described monetization as their "grail": the last stage of their data sharing platform.
They wanted to act as a marketplace, selling access to anonymized financial insights.

They also said they were years away from it. Their current fight was Level 2: sharing data with partner banks without spinning up dedicated clusters for each one.
What Level 4 actually requires, on top of levels 1-3:
- Usage metering. Not "how many messages" but "what's the billable unit and how do we invoice."
- SLA contracts. Uptime, latency, data freshness guarantees. "Best effort" isn't an SLA when someone is paying.
- Billing integration. Stripe, Zuora, custom invoicing. Your platform team is now also a billing team.
- Commercial terms. Pricing, tiers, trials, overage charges. This is product management and legal, not engineering.
- Marketplace dynamics. Multiple data providers and consumers, discovery, quality ratings. You're building a platform, not a feature.
None of this is impossible. Catena-X in automotive is building real-time data sharing across entire supply chains. B2B data marketplaces built on Kafka exist. It's happening.
But the trend is also young. Most potential data buyers are still figuring out their own streaming infrastructure. Selling them access to a real-time data feed when they're running nightly batch imports doesn't work. They can't consume what you're offering.
To be clear about what Conduktor Exchange provides: the operational foundations for data sharing. Isolation, access control, encryption, audit, monitoring. That's the horizontal infrastructure you need before monetization is even possible. We don't do billing, invoicing, or marketplace mechanics. We give you the controlled, auditable data sharing layer that makes those things buildable when you're ready.
Selling access to a real-time data feed only works if your buyers can consume it. Most can't yet — they're still running nightly batch imports. Help them consume first; billing can wait.
Get levels 1-3 working first.
Where you probably are
| What you're doing today | Level | What changes with a gateway |
|---|---|---|
| Exporting Kafka data as CSVs or batch ETL for external use | Below Level 1 | Partners consume via Kafka protocol, no export pipeline |
| Dedicated partner cluster with MirrorMaker | Level 1-2 transition | One proxy replaces N clusters, no replication |
| Proxy/gateway exposing specific topics to external services | Level 2 | Add partner zones, field masking, audit trails |
| Exchanging data with partners for mutual business outcomes | Level 3 | Chargeback tracking, compliance-grade logging |
| Selling data access with metering, SLAs, and billing | Level 4 | Usage metering at the gateway layer |
Working your way up
Concrete next moves, depending on where you sit.
Below Level 1? Audit every data flow that leaves your streaming platform. Map them. Which ones are batch exports that could be streaming? The easy win: any consumer that already speaks Kafka but gets batch data because "that's how we set it up three years ago."
Level 1-2? Count your partner clusters. If the number grows with every new partner, you have a scaling problem. A gateway layer collapses N clusters into one. Conduktor Exchange does this. It sits in front of your existing cluster, no migration needed. Already running MirrorMaker? Exchange can run alongside it. Migrate partner by partner, zero downtime. Start with whichever integration costs you the most operational time.
Level 2? Find one external partnership where data sharing creates genuine business value. "We share data, they do something with it that benefits us both" is the bar. That's your Level 3 pilot.
Level 3? The hard part is working. Monetization is incremental from here. The real question is whether your buyers are ready. If they're still figuring out their own streaming setup, help them consume first. Billing can wait.
Partner onboarding shouldn't require a new cluster. With Conduktor Exchange, you create isolated partner zones on your existing Kafka infrastructure with encrypted streaming and full audit trails. No cluster duplication. No MirrorMaker. Book a demo or see how it works.
Related: Secure Data Sharing | Why Real-Time Data Sharing Matters | Partner Zones | Kafka Chargeback | Kafka Proxy