Federated Ownership
Accelerate Revenue, Scale with the Same Team,
and Cut Operational Costs
Automate guardrails, define ownership, and enable discovery. Developers get autonomy, platform teams maintain control, and every team creates data products they can trust.

Trusted by engineering teams at














Kafka Scales. Manual Processes Don't.
The scripts, the Slack requests, the 'just ask the platform team'? They worked at 5 teams, but scaling them is a full-time job. Your platform team has better things to build.
Misconfigurations cause downtime and erode reliability
Without automated validation, broken configs slip through to production. Every hour of unplanned downtime directly impacts revenue and customer trust.
Unclear ownership slows delivery and inflates platform costs
Developers wait days for access because every request routes through the platform team. At scale, there's no system of record, and Kafka adoption stalls.
Duplication inflates infrastructure costs and wastes engineering capacity
Teams rebuild what already exists because there's no way to discover it. Redundant infrastructure and engineering effort compound to $100K+ per year in waste.
Impact with Conduktor
Based on results reported by Conduktor customers.
75% Fewer Provisioning Tickets
as developers self-serve instead of filing requests. Platform teams stop being a bottleneck for every topic, schema, and connector.
$200K+ Annual Savings
from reduced duplication, faster provisioning, and clear ownership.
3,500+ Hours Saved Per Year
across provisioning, access reviews, and ownership resolution. Time reclaimed goes back to building, not administrating.
4x Faster Provisioning
through automated guardrails that validate instantly, so teams don't wait on manual review.
See How Teams Do It
How Federated Ownership Works
Five steps to shift control to the right people.
CEL-based policies validate instantly. No manual review needed.
Declare applications so every resource maps to an accountable team.
Make topics discoverable. Teams reuse existing data instead of rebuilding.
Data owners approve requests. Platform teams stay out of the loop.
Clear ownership, validated configs, governed access. Data products your org can depend on.
Self-Service Provisioning with Automated Guardrails
Developers create topics, schemas, and connectors themselves. Policies validate instantly. No manual review needed.
- Naming conventions enforced via regex patterns
- Partition and retention limits enforced via min/max bounds
- Config restrictions like
cleanup.policy,compression.type, andmin.insync.replicas - Custom error messages shown in Console, CLI, or GitOps when validation fails
- Compliant resources created instantly in Kafka and tracked in Console
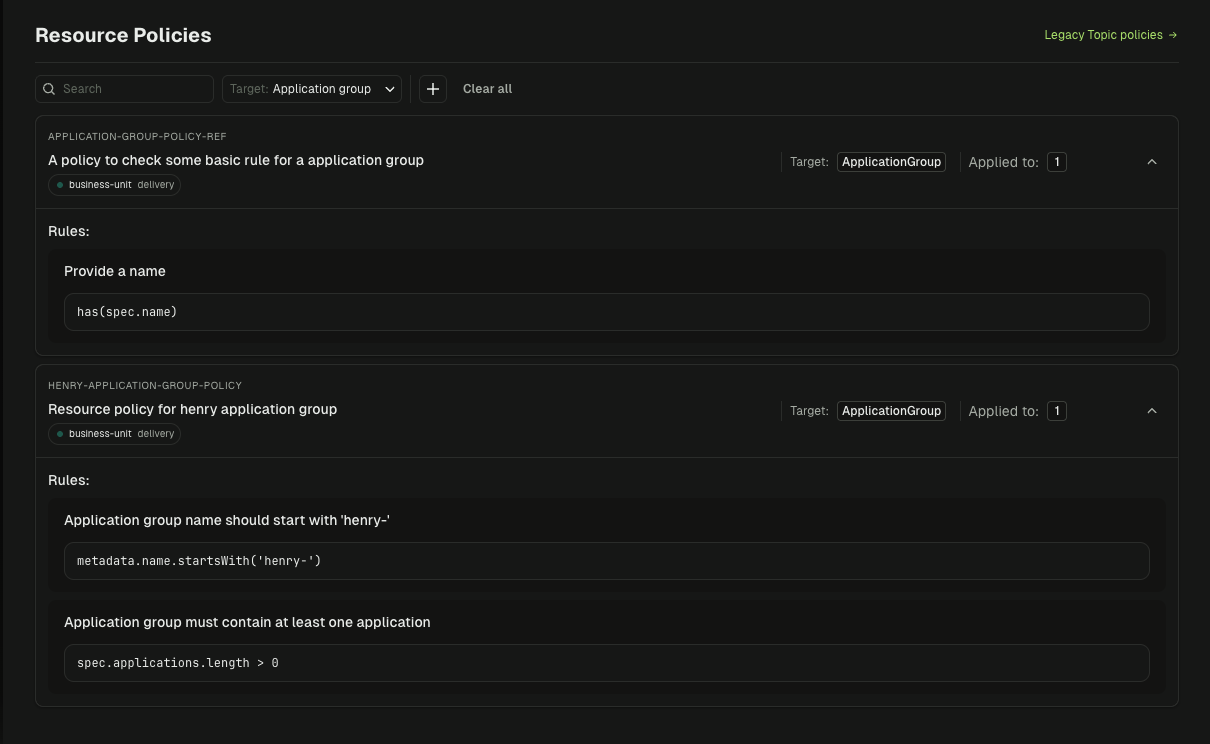
Application Catalog
Define applications with ownership patterns so every resource maps to an accountable team. No more guessing who owns what.
- Ownership patterns using literal names or prefixes like
orders-* - Permission modes for full control (ALL) or read/write only (LIMITED)
- Service account binding with one service account per application instance
- ACL generation with Kafka ACLs auto-created from ownership definitions
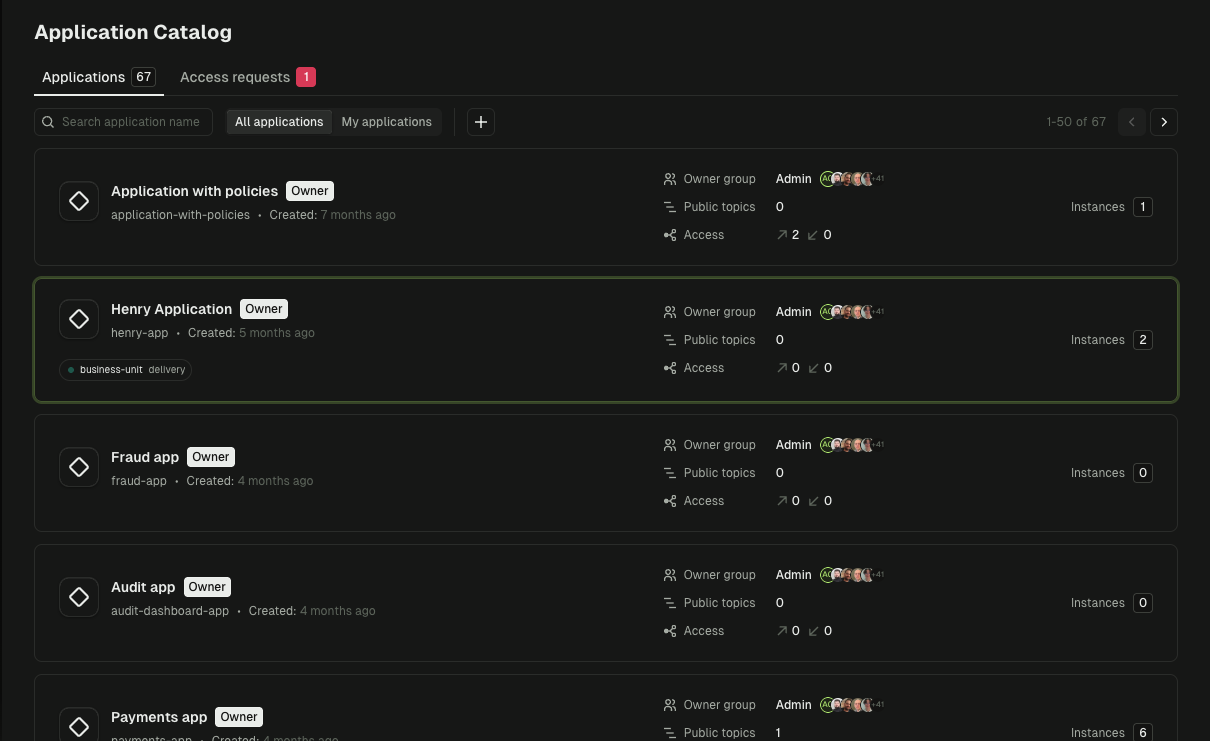
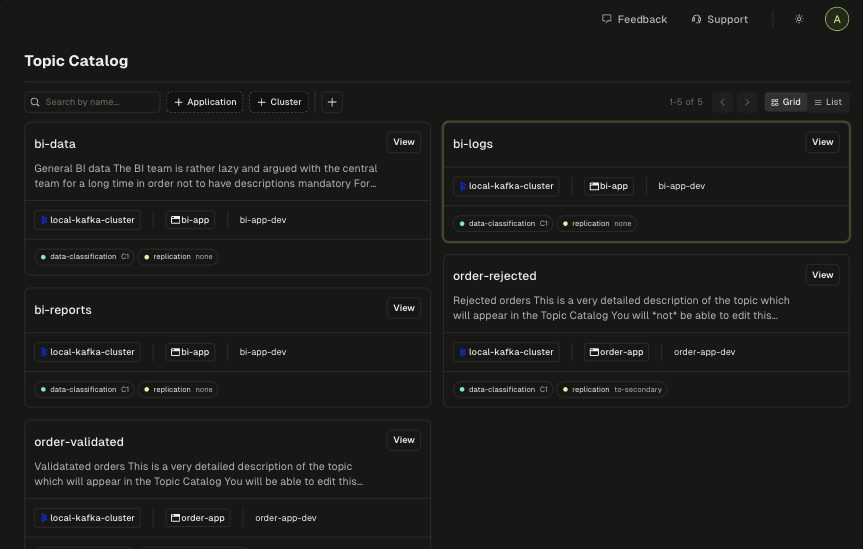
Topic Catalog
Discover data across clusters. Control visibility to protect sensitive resources. Reuse existing topics instead of rebuilding.
- Full-text search across topic names and descriptions
- Label-based filtering by team, domain, or environment
- Public/private visibility to control who can discover each topic
- Subscriber stats showing which apps consume each topic
Approval Workflows
Request access to other teams' resources for cross-team collaboration. Data owners approve or reject — not platform teams. Works with GitOps or direct approval.
- Owner group approval so only members of the owning team can approve
- Granular grants with separate permissions for users and service accounts
- GitOps or UI to approve via pull request or directly in Console
- Full state history tracking who requested, who reviewed, when, and why
vs. Building Your Own
No policy engine to build. No approval workflows to maintain. No catalog to keep in sync. Focus on your product, not your platform.
vs. Scripts & Tickets
Scripts break on edge cases. Tickets create bottlenecks. Automated guardrails validate instantly, whether you have 10 apps or 1,000.
vs. Confluent Cloud
Confluent offers fewer than 25 fixed RBAC roles with no self-service or approval workflows. Conduktor enables fine-grained, team-level permissions within guardrails.
How is this different from just using Terraform or IaC?
Terraform provisions resources but doesn't validate them against policies. Conduktor adds a governance layer — CEL-based policies validate configs at creation time, ownership is tracked automatically, and cross-team access has a proper workflow. You can use both together.
How do I prevent teams from creating inconsistent resources?
Conduktor's policy controls enforce naming conventions, partition limits, retention settings, and other standards automatically. Teams can only create resources that comply with your defined policies.
Can I still require approvals for sensitive operations?
Yes. Conduktor supports configurable approval workflows. You can require manual approval for production changes while allowing self-service for development environments.
Do I need to restructure my existing Kafka setup?
No. Conduktor works with your existing Kafka clusters — Confluent, AWS MSK, Redpanda, or self-managed. You define applications and ownership patterns on top of what you already have.
How does this integrate with GitOps and CI/CD?
Conduktor has a CLI and Terraform provider for managing resources as code. Teams define applications, topics, and permissions in YAML, commit to Git, and deploy through your existing pipelines. Policies validate at every step.
Explore the full documentation →
Ready to automate Kafka governance?
See how federated ownership works in your environment.