Disaster Recovery & Failover
Single-Command Failover. Zero Application Changes. Recovery in Minutes, Not Hours.
When Kafka goes down, every minute counts. Conduktor Gateway, a Kafka proxy, handles cluster failover with a single API call. No application changes, no cross-team coordination. Recover in minutes instead of hours.
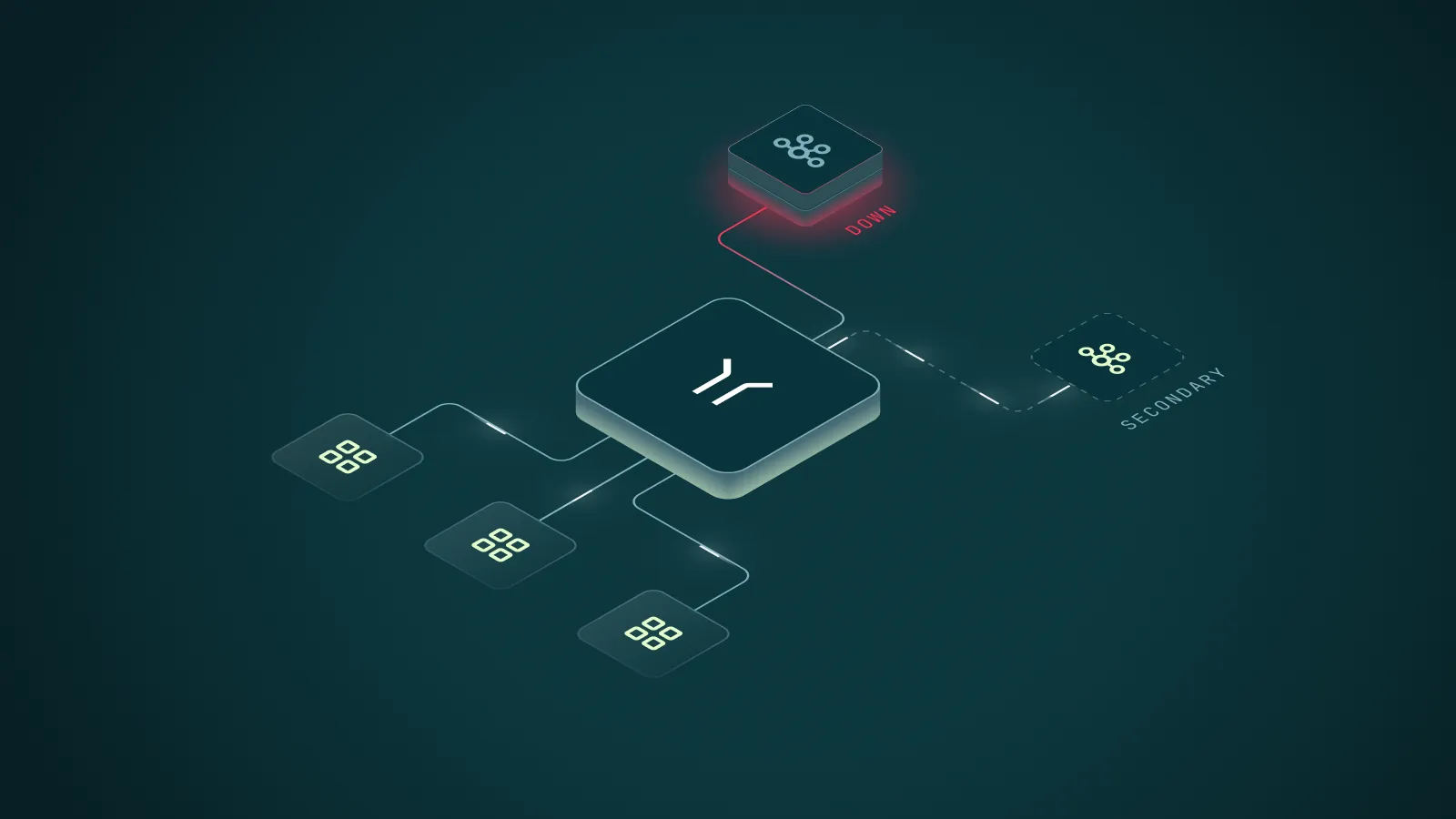
Why Manual Kafka Failover Breaks Down at Scale
The scripts, the runbooks, the war-room calls at 3 AM. They worked when you had a handful of applications on Kafka. But manual disaster recovery doesn't scale, and every new application makes Kafka failover harder.
Coordination That Can't Keep Up
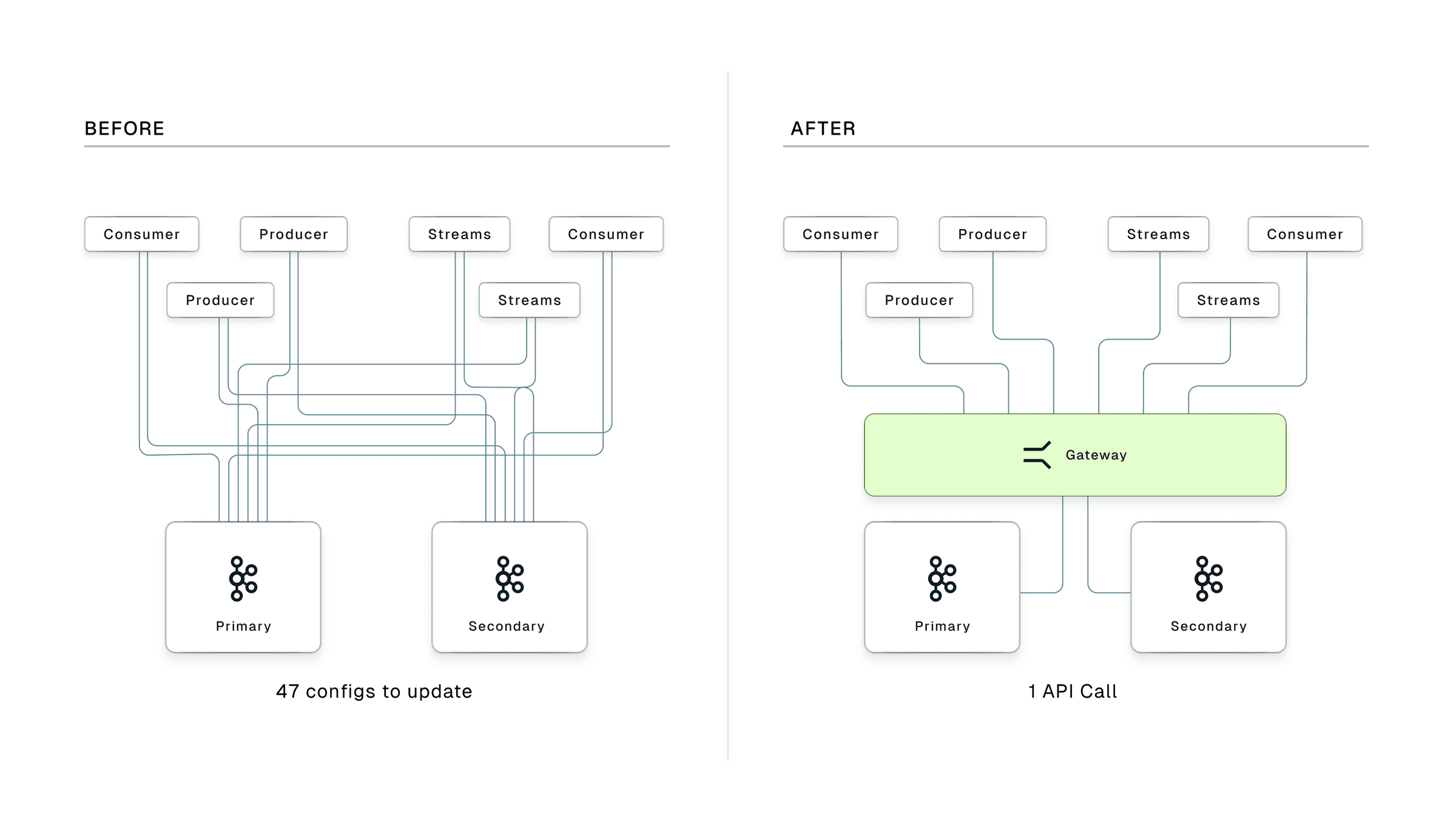
When a primary cluster fails, recovery means updating bootstrap server configs across hundreds of applications and coordinating dozens of teams in parallel. The complexity grows with every application you add to Kafka and every minute of coordination is a minute of downtime.
No Way to Prove Recovery Works
Most organizations invest heavily in DR infrastructure but rarely test it. Production-like drills are too risky, so runbooks go stale and assumptions go unvalidated. When a real incident hits, teams discover gaps in real time.
Security Gaps During Recovery
Encryption policies, RBAC configurations, and audit logging are often inconsistent between primary and backup clusters, or skipped entirely during emergency cutover. A failover that drops security controls is a compliance incident waiting to happen.
Transparent Cluster Switching
Applications connect to Conduktor Gateway, not directly to Kafka. When failover triggers, Conduktor Gateway routes traffic to the backup cluster with no config changes, no application restarts, and no cross-team coordination needed.
Unified State Switching
Conduktor Gateway switches topic mappings, interceptor configs, consumer groups, and virtual cluster definitions to the backup cluster in a single coordinated operation. No manual reconfiguration, no drift between clusters.
Security Continuity
Encryption, access controls, and audit logging are stored in Conduktor Gateway's internal topics and carry over to the backup cluster when replicated with your cross-cluster replication tool. The same security policies you enforce on your primary cluster apply during and after failover.
Application Resilience Testing
Simulate broker failures, network partitions, and latency using Conduktor Gateway's chaos interceptors to validate how your applications handle infrastructure disruptions. Pair with the cluster-switching API to run end-to-end DR drills.
Full Audit Trail
Every cluster switch operation is captured in the audit log. Provide regulators and auditors with evidence of DR execution and compliance continuity.
Failover-Ready Configuration
Conduktor Gateway maintains your failover cluster configuration alongside the primary, so switching requires a single API call. Pair with your replication tool of choice to keep Gateway state and consumer offsets replicated to the backup cluster.
Learn more: Kafka DR Beyond Replication (whitepaper) · Kafka failover configuration · Chaos testing and DR drills · Gateway audit logging · Gateway overview · Kafka data security
How Failover Works
Four steps from setup to full recovery.
Your producers and consumers point to Conduktor Gateway instead of directly to Kafka brokers. This architectural abstraction is the foundation of transparent failover.
Your cross-cluster replication tool (MirrorMaker 2, Confluent Replicator, or Cluster Linking) continuously replicates Gateway's internal topics, including consumer offsets, topic mappings, and security policies, to the backup cluster. Your failover target stays current.
When failover is needed, a single API call switches all traffic to the backup cluster. No application restarts, no config changes, no cross-team coordination.
Applications reconnect through Gateway automatically. Consumers resume from their replicated offsets on the new cluster. Note that consumers may reprocess a small number of messages due to group rebalancing during the switch.
How Conduktor Gateway Reduces Kafka DR from Hours to Minutes
Traditional Kafka DR relies on manual runbooks and cross-team coordination during an outage. Conduktor Gateway eliminates that by sitting between your applications and Kafka, handling cluster switching and security policy enforcement while MirrorMaker keeps state replicated across clusters.
Kafka Disaster Recovery Beyond Replication
The complete DR strategy covering the six technical areas beyond data replication, organized across three operational phases. Includes a chaos testing methodology, compliance mapping for DORA, SOC 2, PCI-DSS, and GDPR, and a step-by-step failover runbook.

95% Faster Recovery
Single-command failover reduces mean time to recovery from hours of manual coordination to minutes of transparent switching.
$250k+ in Prevented Losses
Kafka outages cost $300-500k+ per hour in financial services and e-commerce. Faster recovery directly reduces exposure.
60+ Hours Saved Annually
Eliminate manual runbook execution, cross-team coordination, and post-incident remediation time.
Validated DR Posture
Regular DR drills using chaos interceptors and the cluster-switching API replace annual exercises. Prove recovery works before you need it.
How does Conduktor Gateway handle failover without application changes?
Applications connect to Conduktor Gateway using standard Kafka clients. Conduktor Gateway manages the connection to the underlying Kafka cluster. When a failover is triggered, Conduktor Gateway re-routes all traffic to the backup cluster transparently. Your applications don't need new configs, restarts, or code changes.
What happens to consumer offsets during failover?
Consumer offsets are continuously replicated to the backup cluster using your replication tool of choice, whether that's MirrorMaker 2, Confluent Replicator, or Cluster Linking. When consumers reconnect through Gateway after a switch, they resume from their last replicated position on the new cluster. Consumers may reprocess a small number of messages due to replication lag and group rebalancing during the switch.
Can I test failover without affecting production?
Yes. Conduktor Gateway's chaos interceptors let you simulate broker failures, latency, and other disruptions to test application resilience. You can also run end-to-end DR drills by triggering the cluster-switching API in a staging environment to validate your recovery path without risking production traffic.
Does this work with Confluent Cloud, AWS MSK, and self-managed Kafka?
Yes. Conduktor Gateway works with any Kafka distribution. Your primary and backup clusters can even run on different providers, giving you true infrastructure independence for your DR strategy.
How fast is the actual cluster switch?
The cluster switch typically executes in seconds for most deployments. Conduktor Gateway re-establishes connections to the new cluster and resumes traffic routing automatically. End-to-end recovery, including application reconnection and consumer group rebalancing, typically completes in minutes. Actual time depends on deployment size and network conditions.
What about security and compliance during failover?
Encryption policies, RBAC configurations, and audit logging are enforced identically across both clusters. Conduktor Gateway maintains continuous audit trails throughout the failover process, so you can demonstrate uninterrupted compliance to regulators.
Ready to simplify Kafka failover?
See how Conduktor reduces recovery time from hours to minutes. Our team can help you design a DR strategy that eliminates cross-team coordination and validates recovery before you need it.