Agentic AI Pipelines: Streaming Data for Autonomous Agents
The evolution from traditional machine learning models to autonomous AI agents represents a fundamental shift in how we build intelligent systems. While traditional ML models wait passively for inputs and return predictions, AI agents actively pursue goals, make multi-step decisions, and take actions in their environment. This autonomy creates new demands on data infrastructure, particularly the need for continuous, high-quality streaming data that provides agents with fresh context for decision-making.
An agentic AI pipeline connects real-time operational data streams to autonomous agents, enabling them to react to events, retrieve relevant context, reason through problems, and execute actions, all while maintaining the data quality and governance controls essential for reliable AI operations.
Key Concepts: Understanding the Components
Key concepts to understand:
- RAG (Retrieval Augmented Generation): A technique where language models retrieve relevant information from external knowledge sources before generating responses. Instead of relying solely on training data, RAG systems query databases or document stores to ground their outputs in factual, up-to-date information.
- Vector Database: A specialized database that stores data as high-dimensional vectors (embeddings) and enables similarity searches. When you ask "what are our return policies?", the vector database finds documents with semantically similar content, even if they don't contain the exact words you used.
- Embeddings: Numerical representations of text, images, or other data that capture semantic meaning. Similar concepts have similar embeddings, enabling similarity searches. For example, "refund" and "money back" have embeddings close to each other in vector space.
- Context Window: The maximum amount of text a language model can process at once, measured in tokens. Models like GPT-4 have context windows of 128,000 tokens (~100,000 words). When relevant information exceeds this limit, agents must select which context to include.
- Hallucination: When language models generate plausible-sounding but factually incorrect information. Agents using stale or missing data are more prone to hallucination since they lack grounding facts.
Understanding AI Agents: Beyond Traditional ML
AI agents differ from traditional machine learning models in three critical ways:
- Autonomy: Rather than simply mapping inputs to outputs, agents operate independently to achieve specified goals. They can break down complex objectives into subtasks, plan sequences of actions, and adapt their approach based on results.
- Tool Use: Agents interact with external systems through tools, APIs, databases, search engines, or other services. This allows them to gather information, perform calculations, and take actions in the real world, extending their capabilities far beyond the model's training data.
- Multi-Step Reasoning: Instead of single-shot inference, agents engage in iterative reasoning loops. They observe their environment, plan actions, execute them, and reflect on outcomes, often across multiple cycles before completing a task.
Consider a customer service agent: it doesn't just classify support tickets. It reads the ticket, searches the knowledge base, retrieves the customer's order history, drafts a response, checks company policies, and sends the reply, all autonomously. Each step requires fresh, accurate data.
Why Streaming Data Powers Agentic AI
Agents depend on real-time operational data for three essential functions:
- Fresh Context: An agent's decisions are only as good as its context. Stale data leads to incorrect assumptions and poor actions. When a trading agent analyzes market conditions, five-minute-old prices might as well be ancient history. When a logistics agent routes deliveries, it needs current traffic data, not yesterday's patterns.
- Event-Driven Triggers: Agents don't operate on fixed schedules, they respond to events. A fraud detection agent springs into action when suspicious transactions occur. An incident response agent activates when system metrics cross thresholds. These triggers flow through streaming data pipelines, often from Kafka topics or event streams.
- Continuous Learning Loop: Agents improve through feedback. Each action produces outcomes that inform future decisions. This requires streaming the results of agent actions back into the pipeline, creating a closed loop where agents learn from their operational performance in near real-time.
Without streaming data, agents operate on stale assumptions, miss critical events, and fail to adapt to changing conditions.
Agentic AI Pipeline Architecture
A production agentic AI pipeline follows a consistent pattern: 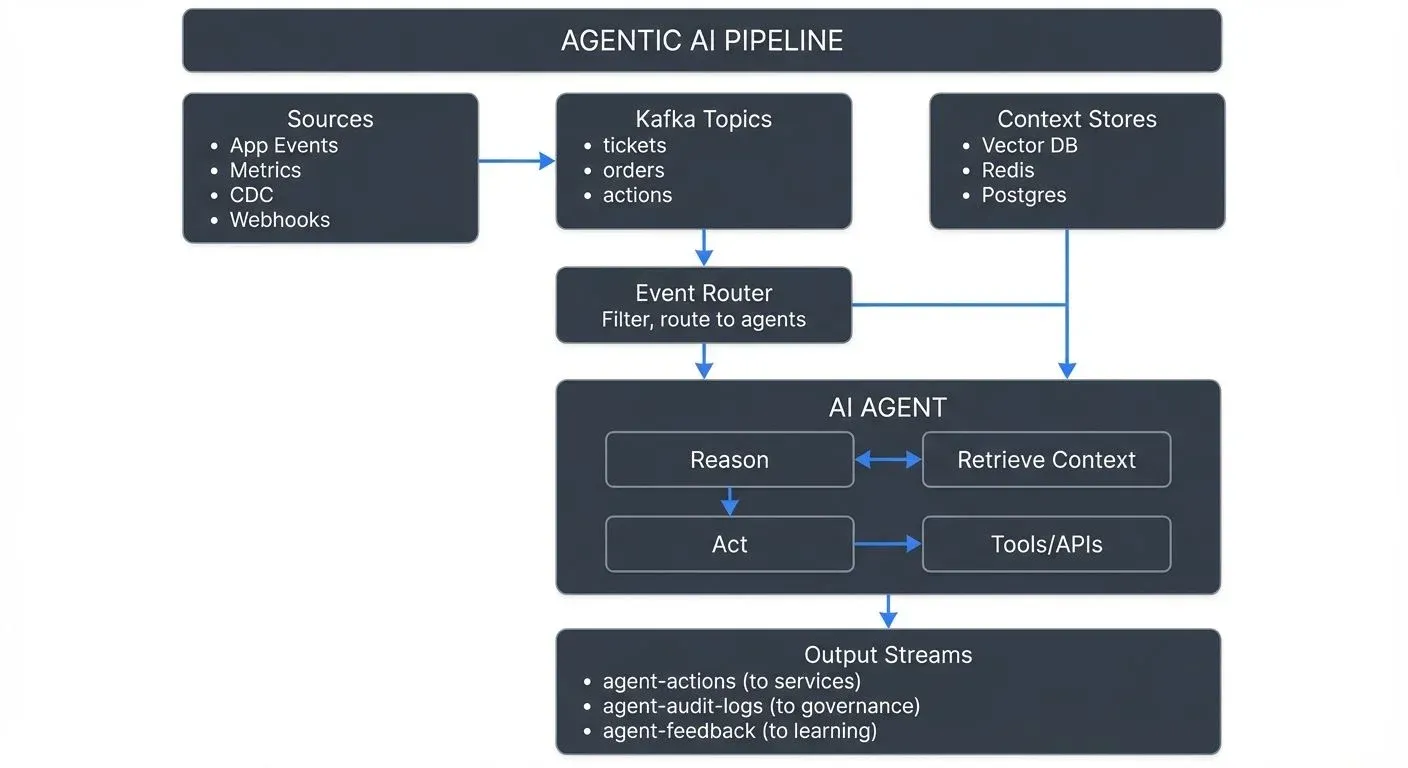
1. Event Ingestion Streaming platforms like Apache Kafka capture operational events: user actions, system metrics, transactions, sensor readings. These events flow continuously into topics organized by domain (orders, inventory, interactions).
2. Context Enrichment Raw events trigger context retrieval. The agent needs more than just "order cancelled", it needs customer history, cancellation reasons, inventory status. This often involves:
- Querying vector databases for semantic similarity searches
- Retrieving from key-value stores for fast lookups
- Joining event streams for correlated data
- Accessing RAG (Retrieval Augmented Generation) systems for relevant documents
3. Agent Execution The enriched context flows to the agent, which:
- Analyzes the situation using its language model
- Reasons through potential actions
- Consults tools (APIs, databases, calculators)
- Makes decisions based on its goal
- Generates actions (API calls, messages, database updates)
4. Action Execution Agent decisions become concrete actions streamed back into the operational environment: send an email, update a database, trigger a workflow, create a ticket.
5. Feedback Loop Action outcomes stream back as new events, providing the agent with feedback and enabling monitoring systems to track agent performance, data quality, and business impact.
# Production agent loop with error handling and structured data
from kafka import KafkaConsumer, KafkaProducer
from typing import Dict, List, Any
import json
from datetime import datetime
kafka_consumer = KafkaConsumer(
'support-tickets',
bootstrap_servers='localhost:9092',
group_id='customer-service-agent',
value_deserializer=lambda m: json.loads(m.decode('utf-8'))
)
kafka_producer = KafkaProducer(
bootstrap_servers='localhost:9092',
value_serializer=lambda m: json.dumps(m).encode('utf-8')
)
def retrieve_context(event: Dict[str, Any], vector_db, redis) -> Dict[str, Any]:
"""
Retrieve enriched context from multiple sources.
Returns: {
'customer_history': [...],
'similar_tickets': [...],
'knowledge_base': [...],
'product_info': {...}
}
"""
ticket_id = event['ticket_id']
customer_id = event['customer_id']
# Fast lookup: customer data from Redis cache
customer_history = redis.get(f"customer:{customer_id}")
# Semantic search: find similar resolved tickets
query_embedding = embed_text(event['description'])
similar_tickets = vector_db.query(
vector=query_embedding,
top_k=5,
filter={"status": "resolved"}
)
# Semantic search: relevant knowledge base articles
kb_articles = vector_db.query(
vector=query_embedding,
top_k=3,
filter={"type": "knowledge_base"}
)
return {
'customer_history': customer_history,
'similar_tickets': [t['metadata'] for t in similar_tickets['matches']],
'knowledge_base': [kb['metadata']['text'] for kb in kb_articles['matches']],
'product_info': event.get('product_id')
}
# Main agent processing loop
for message in kafka_consumer:
event = message.value
try:
# Step 1: Retrieve enriched context
context = retrieve_context(event, vector_db, redis)
# Step 2: Agent reasoning with structured input
agent_input = {
"ticket": event,
"customer_history": context['customer_history'],
"similar_cases": context['similar_tickets'],
"knowledge_base": context['knowledge_base'],
"goal": "resolve customer issue with empathy and accuracy"
}
# Agent returns structured output
result = agent.invoke(agent_input)
# result = {
# _34_: {
# _35_: _36_,
# _37_: _38_,
# _39_: _40_,
# _41_: _42_
# },
# _43_: _44_,
# _45_: 0.87,
# _46_: [_47_, _48_]
# }
# Step 3: Stream actions to appropriate topics
kafka_producer.send('agent-actions', {
'ticket_id': event['ticket_id'],
'action': result['action'],
'timestamp': datetime.utcnow().isoformat()
})
# Step 4: Stream audit logs for governance
kafka_producer.send('agent-audit-logs', {
'ticket_id': event['ticket_id'],
'agent_id': 'customer-service-v2',
'reasoning': result['reasoning'],
'confidence': result['confidence'],
'context_sources': list(context.keys()),
'timestamp': datetime.utcnow().isoformat()
})
# Step 5: Stream feedback for learning
kafka_producer.send('agent-feedback', {
'ticket_id': event['ticket_id'],
'action_type': result['action']['type'],
'confidence': result['confidence']
})
except Exception as e:
# Dead letter queue for failed events
kafka_producer.send('agent-dlq', {
'original_event': event,
'error': str(e),
'timestamp': datetime.utcnow().isoformat()
})This architecture requires low latency (agents can't wait minutes for context), high throughput (supporting many concurrent agents), and exactly-once semantics (duplicate actions can cause serious problems).
Data Requirements for Agent Reliability
Agent quality correlates directly with data quality. Several requirements stand out:
- Latency: Context retrieval must complete in milliseconds to seconds. An agent that waits 30 seconds for customer data provides a poor experience. Streaming platforms with low-latency connectors and fast vector databases (Pinecone, Weaviate, Milvus) are essential.
- Freshness: Embeddings in vector stores must reflect current documents. If your knowledge base updates but embeddings lag by hours, agents retrieve outdated information. Streaming pipelines should trigger re-embedding when source documents change.
- Completeness: Missing data forces agents to make assumptions or fail entirely. If inventory data is incomplete, an order fulfillment agent might promise products that aren't available.
- Consistency: Agents often pull from multiple data sources. Inconsistencies between systems lead to contradictory context and confused reasoning. Change Data Capture (CDC) streams help maintain consistency by propagating updates across systems in real-time.
Real-World Use Cases
- Customer Service Automation: Agents handle support tickets by streaming in ticket events, retrieving customer history and product documentation, generating responses, and updating CRM systems, all autonomously for routine issues.
- Operational Monitoring: DevOps agents monitor metric streams, detect anomalies, correlate across services, investigate root causes by querying logs and traces, and execute remediation workflows.
- Financial Trading: Trading agents consume market data streams, analyze patterns, evaluate risk against portfolio state, and execute trades, with latency measured in milliseconds.
- Supply Chain Optimization: Logistics agents process shipment events, weather data, and traffic conditions to dynamically reroute deliveries, reorder inventory, and optimize warehouse operations.
Each use case demonstrates the same pattern: streaming events trigger agents that retrieve fresh context, reason through problems, and take actions that feed back into operational systems.
Getting Started: Building Your First Agent
For teams new to agentic AI, start with these recommended frameworks and a phased approach:
Recommended Frameworks
- LangChain: The most popular framework for building AI agents. Provides abstractions for agents, tools, memory, and chains. Excellent for prototyping and has extensive community support.
- LangGraph: Extension of LangChain that adds explicit graph-based agent workflows. Better for complex multi-step agents where you want control over the reasoning flow.
- AutoGPT / AutoGen: Frameworks for fully autonomous agents that plan and execute complex tasks with minimal human intervention. More experimental but powerful for research.
- LlamaIndex: Specialized for RAG and data retrieval. Excellent when your agents primarily need to query and reason over documents.
Phased Implementation Approach
Phase 1: Read-Only Agent (Low Risk) Start with agents that only read data and provide recommendations without taking actions:
- Monitor event streams and flag anomalies for human review
- Answer questions from knowledge bases without modifying data
- Provide draft responses that humans approve before sending
Phase 2: Constrained Actions (Medium Risk) Add autonomous actions with strict guardrails:
- Auto-respond to FAQs with approved templates
- Update low-risk database fields (tags, categories)
- Send notifications with bounded content
Phase 3: Autonomous Agents (High Risk) Deploy fully autonomous agents for high-stakes operations:
- Execute financial transactions
- Make customer commitments
- Modify production systems
Each phase builds confidence in data quality, agent reliability, and governance processes before increasing autonomy.
Essential Skills for Agent Teams
Building production agentic AI pipelines requires:
- Streaming expertise: Kafka, Flink, or similar platforms
- ML/AI knowledge: Understanding LLM capabilities, limitations, prompt engineering
- Data engineering: ETL, CDC, real-time data quality
- Software engineering: Robust error handling, monitoring, distributed systems
- Domain expertise: Understanding the business context where agents operate
Challenges in Production Agentic Pipelines
Hallucination Risk: Language models can generate plausible but incorrect information. When agents act on hallucinations, the consequences are real, wrong answers to customers, incorrect data updates, or misguided actions.
Mitigation strategies:
- Ground responses in retrieved facts from streaming data (RAG)
- Add validation steps that verify agent outputs against known constraints
- Implement confidence scoring and route low-confidence decisions to human review
- Use structured output formats that constrain generation
Stale Data Impact: Vector databases with outdated embeddings cause agents to retrieve irrelevant context. Even short delays (minutes to hours) degrade agent performance.
Mitigation strategies:
- Implement CDC streams from source systems to vector databases
- Add timestamps to embeddings and filter by recency
- Monitor embedding freshness metrics and alert on staleness
- Use hybrid search (semantic + keyword) to catch recent exact matches
Context Window Limits: Agents have finite context windows. When relevant information exceeds this limit, agents must summarize or select, potentially losing critical details.
Mitigation strategies:
- Rank retrieved context by relevance and include only top results
- Use map-reduce patterns: summarize chunks first, then reason over summaries
- Implement progressive context loading: start with essentials, add details if needed
- Consider agents with larger context windows (Claude 3.5 Sonnet: 200K tokens)
Reliability and Error Handling: Agents interact with many external systems, each of which can fail. Pipelines need graceful degradation.
Mitigation strategies:
- Implement circuit breakers for external API calls
- Use exponential backoff for retries with maximum attempt limits
- Route failed events to dead letter queues for manual review
- Provide fallback responses when systems are unavailable
- Set aggressive timeouts to prevent hanging on slow dependencies
Cost and Resource Management: Running large language models for every event is expensive. A production agent handling 1M events/day can cost $10K+/month in LLM API fees.
Mitigation strategies:
- Batch similar requests when latency allows
- Use smaller/cheaper models for simple classification tasks (routing, filtering)
- Implement model routing: Claude Haiku for simple tasks, Opus for complex reasoning
- Cache common patterns (FAQ responses, standard procedures)
- Consider self-hosted models for high-volume, low-complexity scenarios
Governance for Autonomous Agents
Autonomous systems that take real actions demand rigorous governance:
- Action Auditing: Every agent decision and action must be logged with full context: what data was retrieved, what reasoning was applied, what action was taken, and what outcome occurred. Streaming these audit logs to governance platforms enables compliance, debugging, and quality improvement.
- Guardrails and Constraints: Agents need boundaries. A customer service agent shouldn't offer unlimited refunds. A trading agent needs position limits. These guardrails can be implemented through:
- Pre-execution validation (checking actions against policies)
- Streaming policy updates (real-time constraint propagation)
- Post-execution review (flagging policy violations)
- Human-in-the-Loop Workflows: Critical decisions should route to humans for approval. Streaming architectures support this through event-driven workflows: agent proposes action → streams to review queue → human approves/rejects → action executes or cancels.
- Data Quality Monitoring: Agent performance correlates with data quality. Tracking metrics like embedding freshness, context retrieval latency, and data completeness helps identify when degraded data quality impacts agent decisions.
Tools like Conduktor provide centralized governance for streaming data platforms, enabling teams to monitor data quality, enforce policies, and audit data access across the agentic AI pipeline, ensuring that agents operate on trusted, well-governed data streams. For data quality validation and testing, see Conduktor's Data Quality capabilities.
Integration Patterns: RAG and Vector Stores
Most production agentic AI pipelines integrate with Retrieval Augmented Generation (RAG) systems:
- Streaming to Vector Stores: As documents change (products updated, policies revised, knowledge articles published), CDC streams capture these changes and trigger re-embedding. The fresh embeddings stream into vector databases, ensuring agents retrieve current information.
- Hybrid Context Retrieval: Agents often combine:
- Semantic search (vector similarity for conceptual matches)
- Keyword search (traditional indexes for exact matches)
- Structured queries (databases for transactional data)
- Time-series data (metrics streams for temporal context)
- Context Caching: Frequently accessed context (product catalogs, common FAQs) can be cached, but caches must invalidate when source data streams updates. Event-driven cache invalidation keeps context fresh without constant re-retrieval.
- Feedback for Retrieval Improvement: When agents mark retrieved context as helpful or unhelpful, these signals stream back to improve retrieval rankings, creating a continuous learning loop for the retrieval system itself.
Monitoring and Observability
Operating agentic AI pipelines requires monitoring across multiple dimensions:
Agent Performance Metrics:
- Task success rate
- Action accuracy
- Reasoning quality (human evaluation samples)
- Goal completion time
Data Quality Metrics:
- Context retrieval latency
- Embedding freshness
- Data completeness scores
- Stream lag and throughput
- Correlation Analysis: The key insight comes from correlating these metrics. When does data staleness impact agent success rates? How does retrieval latency affect user satisfaction? These correlations guide infrastructure investment and quality improvements.
- Anomaly Detection: Sudden changes in agent behavior often indicate data quality issues. If success rates drop 20%, check for stale embeddings, incomplete data, or stream processing delays.
Summary
Agentic AI pipelines combine streaming data platforms, vector databases, and large language models into autonomous systems that perceive, reason, and act. Agent quality depends directly on data quality: the freshness, completeness, and reliability of the streaming context that informs their decisions.
Building production agentic AI pipelines requires:
- Low-latency streaming infrastructure (Apache Kafka, Apache Flink)
- Fast context retrieval (vector databases, caching layers)
- Robust agent orchestration (error handling, retries, guardrails)
- Governance (auditing, policies, human oversight)
- Continuous monitoring (data quality, agent performance, correlation)
The streaming data pipelines powering these agents are critical infrastructure and require the same engineering rigor and governance discipline as any mission-critical system.
Related Concepts
- Streaming Data Pipeline - Build data pipelines for autonomous agents
- Real-Time Analytics with Streaming Data - Analytics on agent performance and decisions
- Data Governance Framework: Roles and Responsibilities - Govern agentic AI systems and data access
Sources and References
- LangChain Documentation - Agents - Comprehensive guide to building AI agents with LangChain framework
- Apache Kafka Streams Documentation - Official documentation for real-time stream processing with Kafka
- Pinecone Vector Database Documentation - Guide to implementing semantic search and RAG systems with vector databases
- OpenAI Retrieval Augmented Generation - Best practices for implementing RAG with large language models
- Apache Flink Stream Processing - Low-latency stream processing architecture for AI pipelines