Automated Data Quality Testing: A Practical Guide for Modern Data Pipelines
Data quality issues cost organizations millions annually through incorrect analytics, failed ML models, and broken downstream systems. As data pipelines grow more complex, especially with real-time streaming architectures, manual testing becomes impractical. Automated data quality testing is essential for maintaining trust in your data infrastructure.
Why Automate Data Quality Testing?
Traditional manual data validation doesn't scale. When dealing with hundreds of data sources, schema evolution, and continuous data flows, you need systematic, automated approaches to catch issues before they propagate downstream.
Automated testing provides:
- Early detection: Catch schema changes, null values, and data anomalies immediately
- Continuous validation: Test data quality in real-time as it flows through pipelines
- Regression prevention: Ensure transformations don't break existing data contracts
- Documentation: Tests serve as executable specifications of data expectations
Core Testing Dimensions
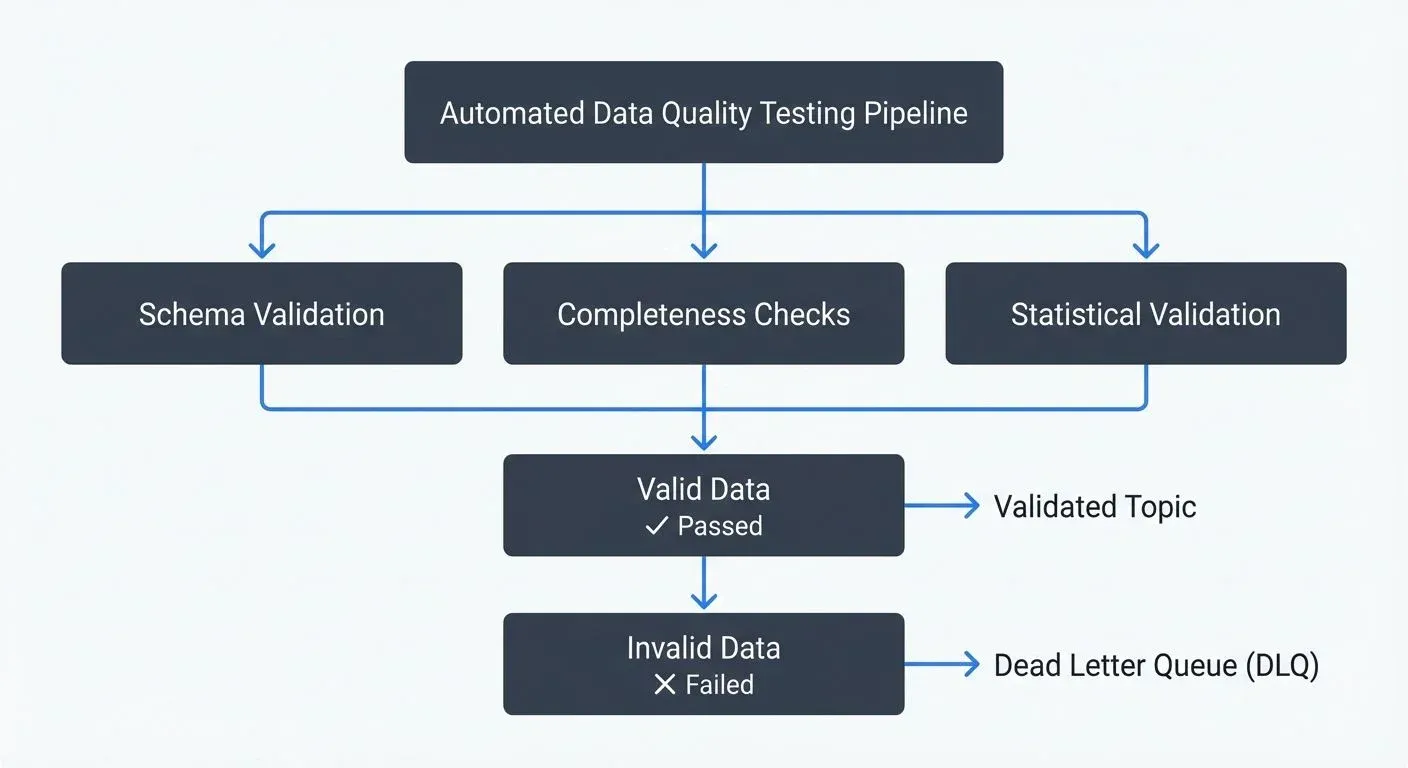
Effective data quality testing covers multiple dimensions. For broader context on quality dimensions and how they relate to organizational data strategy, see Data Quality Dimensions: Accuracy, Completeness, and Consistency.
1. Schema Validation
Ensure data structures match expected schemas, particularly critical in streaming environments where schema evolution can break consumers.
from pydantic import BaseModel, Field, field_validator
from typing import Optional
from datetime import datetime
class UserEvent(BaseModel):
user_id: str = Field(..., min_length=1)
event_type: str
timestamp: datetime
properties: dict
revenue: Optional[float] = None
@field_validator('revenue')
@classmethod
def validate_revenue(cls, v):
if v is not None and v < 0:
raise ValueError('Revenue cannot be negative')
return v
@field_validator('event_type')
@classmethod
def validate_event_type(cls, v):
allowed_types = {'page_view', 'click', 'purchase', 'signup'}
if v not in allowed_types:
raise ValueError(f'Event type must be one of {allowed_types}')
return v
# Validation in streaming pipeline
def validate_event(event_json: dict) -> bool:
try:
UserEvent(**event_json)
return True
except Exception as e:
log_validation_error(e, event_json)
return False2. Data Completeness
Check for missing values, null rates, and required field presence.
import pandas as pd
from typing import List, Dict
class CompletenessValidator:
def __init__(self, required_fields: List[str], max_null_rate: float = 0.05):
self.required_fields = required_fields
self.max_null_rate = max_null_rate
def validate_batch(self, df: pd.DataFrame) -> Dict[str, any]:
results = {
'passed': True,
'issues': []
}
# Check required fields exist
missing_fields = set(self.required_fields) - set(df.columns)
if missing_fields:
results['passed'] = False
results['issues'].append(f'Missing required fields: {missing_fields}')
# Check null rates
for field in self.required_fields:
if field in df.columns:
null_rate = df[field].isna().sum() / len(df)
if null_rate > self.max_null_rate:
results['passed'] = False
results['issues'].append(
f'{field} null rate {null_rate:.2%} exceeds threshold {self.max_null_rate:.2%}'
)
return results
# Usage
validator = CompletenessValidator(required_fields=['user_id', 'timestamp', 'event_type'])
validation_result = validator.validate_batch(events_df)
assert validation_result['passed'], f"Validation failed: {validation_result['issues']}"3. Statistical Validation
Detect anomalies using statistical boundaries and historical patterns.
import numpy as np
from scipy import stats
class StatisticalValidator:
def __init__(self, historical_mean: float, historical_std: float, z_threshold: float = 3.0):
self.mean = historical_mean
self.std = historical_std
self.z_threshold = z_threshold
def validate_metric(self, current_value: float) -> Dict[str, any]:
z_score = abs((current_value - self.mean) / self.std)
is_anomaly = z_score > self.z_threshold
return {
'value': current_value,
'z_score': z_score,
'is_anomaly': is_anomaly,
'expected_range': (
self.mean - self.z_threshold * self.std,
self.mean + self.z_threshold * self.std
)
}
# Example: Validate daily record count
daily_count_validator = StatisticalValidator(
historical_mean=1_000_000,
historical_std=50_000,
z_threshold=3.0
)
current_count = 1_200_000
result = daily_count_validator.validate_metric(current_count)
if result['is_anomaly']:
alert(f"Anomalous record count: {current_count} (z-score: {result['z_score']:.2f})")Streaming Data Quality with Kafka
For streaming pipelines, data quality testing must happen in real-time. When using Apache Kafka, streaming management tools provide valuable capabilities for monitoring and validating data quality in real-time contexts.
For foundational understanding of Kafka architecture and streaming patterns, see Apache Kafka.
Real-Time Validation Pattern
from kafka import KafkaConsumer, KafkaProducer
import json
class StreamingQualityTester:
def __init__(self, bootstrap_servers: str, consumer_group: str = 'quality-tester'):
self.consumer = KafkaConsumer(
'raw-events',
bootstrap_servers=bootstrap_servers,
group_id=consumer_group,
auto_offset_reset='earliest',
enable_auto_commit=False, # Manual commit for exactly-once
value_deserializer=lambda m: json.loads(m.decode('utf-8'))
)
self.valid_producer = KafkaProducer(
bootstrap_servers=bootstrap_servers,
acks='all', # Wait for all replicas
value_serializer=lambda m: json.dumps(m).encode('utf-8')
)
self.dlq_producer = KafkaProducer(
bootstrap_servers=bootstrap_servers,
acks='all',
value_serializer=lambda m: json.dumps(m).encode('utf-8')
)
self.metrics = {
'processed': 0,
'valid': 0,
'invalid': 0
}
def run(self):
try:
for message in self.consumer:
self.metrics['processed'] += 1
event = message.value
# Run validation suite
validation_results = self.validate_event(event)
if validation_results['passed']:
self.valid_producer.send('validated-events', event)
self.metrics['valid'] += 1
else:
# Send to dead letter queue with error details
error_event = {
**event,
'_validation_errors': validation_results['errors'],
'_original_topic': 'raw-events',
'_timestamp': message.timestamp
}
self.dlq_producer.send('validation-dlq', error_event)
self.metrics['invalid'] += 1
# Commit offset after successful processing
self.consumer.commit()
# Report metrics periodically
if self.metrics['processed'] % 1000 == 0:
self.report_metrics()
finally:
# Ensure clean shutdown
self.consumer.close()
self.valid_producer.close()
self.dlq_producer.close()
def validate_event(self, event: dict) -> Dict[str, any]:
errors = []
# Schema validation
try:
UserEvent(**event)
except Exception as e:
errors.append(f'Schema validation failed: {str(e)}')
# Business rule validation
if event.get('event_type') == 'purchase' and not event.get('revenue'):
errors.append('Purchase events must include revenue')
return {
'passed': len(errors) == 0,
'errors': errors
}
def report_metrics(self):
success_rate = self.metrics['valid'] / self.metrics['processed'] * 100
print(f"Processed: {self.metrics['processed']}, "
f"Success Rate: {success_rate:.2f}%")Quality Monitoring for Kafka Streams
Streaming management platforms provide visual monitoring and testing capabilities for Kafka streams:
- Monitor schema registry: Track schema evolution and catch breaking changes. For details on schema management patterns, see Schema Registry and Schema Management.
- Validate message format: Configure validation rules for incoming data. For implementing validation with Conduktor, see Enforcing Data Quality.
- Dead letter queue management: Easily inspect and replay failed messages. For error handling patterns, see Dead Letter Queues for Error Handling.
Set up quality gates to automatically route messages through validation topics, making it easy to visualize quality metrics and troubleshoot issues. For observing data quality metrics, see Observing Data Quality with Conduktor.
Continuous Validation with Data Quality Policies
Conduktor Data Quality Policies complement automated testing by providing infrastructure-level continuous validation. Data Quality Policies create Rules defining expected message formats and content that attach to specific topics, creating a centralized quality enforcement layer. In observe-only mode, Policies record violations without impacting message flow; when integrated with Conduktor Gateway (a Kafka proxy), they validate records before production, blocking or marking non-compliant messages.
This layered approach combines development-time testing with production-time enforcement, catching edge cases that testing environments might miss. For implementation patterns, see Data Quality Policies.
Implementing a Testing Framework
Build a comprehensive testing framework that runs continuously:
class DataQualityTestSuite:
def __init__(self, name: str):
self.name = name
self.tests = []
self.results = []
def add_test(self, test_name: str, test_func: callable):
self.tests.append((test_name, test_func))
def run(self, data: any) -> bool:
self.results = []
all_passed = True
for test_name, test_func in self.tests:
try:
result = test_func(data)
self.results.append({
'test': test_name,
'passed': result['passed'],
'details': result.get('details', '')
})
if not result['passed']:
all_passed = False
except Exception as e:
self.results.append({
'test': test_name,
'passed': False,
'details': f'Test failed with exception: {str(e)}'
})
all_passed = False
return all_passed
def generate_report(self) -> str:
report = [f"\nTest Suite: {self.name}"]
report.append("=" * 50)
for result in self.results:
status = "PASS" if result['passed'] else "FAIL"
report.append(f"[{status}] {result['test']}")
if result['details']:
report.append(f" Details: {result['details']}")
passed = sum(1 for r in self.results if r['passed'])
total = len(self.results)
report.append(f"\nResults: {passed}/{total} tests passed")
return "\n".join(report)Best Practices
- Test early and often: Validate data at ingestion, transformation, and output stages
- Separate validation logic: Keep quality tests decoupled from business logic
- Monitor quality metrics: Track validation success rates, common failure patterns
- Design for failure: Use dead letter queues and graceful degradation
- Version your tests: Treat quality tests as code with proper version control
- Balance strictness: Too strict validation creates false positives; too lenient misses real issues
Summary
Automated data quality testing shifts data reliability from a reactive problem to a proactive one. By validating across schema, completeness, and statistical dimensions — particularly in streaming architectures — you build data systems that teams can trust.
For production-grade implementation using established frameworks, see Great Expectations: Data Testing Framework. For formal agreements between data producers and consumers, see Data Contracts for Reliable Pipelines.
Automated testing reduces debugging time, improves confidence in data-driven decisions, and speeds up incident resolution.
Related Concepts
- Building a Data Quality Framework - Comprehensive approach to quality management
- Schema Registry and Schema Management - Schema validation infrastructure
- Data Contracts for Reliable Pipelines - Contract-based validation strategies
Sources and References
- Great Expectations Documentation - Leading open-source framework for data validation and quality testing
- Apache Kafka Schema Registry - Schema validation and evolution management for streaming data
- Pydantic Data Validation - Python library for data validation using type annotations
- dbt Data Testing - Testing framework for analytics engineering and data transformations
- AWS Glue Data Quality - Automated data quality monitoring for data pipelines