Dead Letter Queues for Error Handling
When building event-driven systems, not every message can be processed successfully. Network failures, schema mismatches, invalid data, and application bugs all contribute to processing failures. Dead Letter Queues (DLQs) provide a systematic approach to handle these failures without losing data or blocking the processing pipeline. 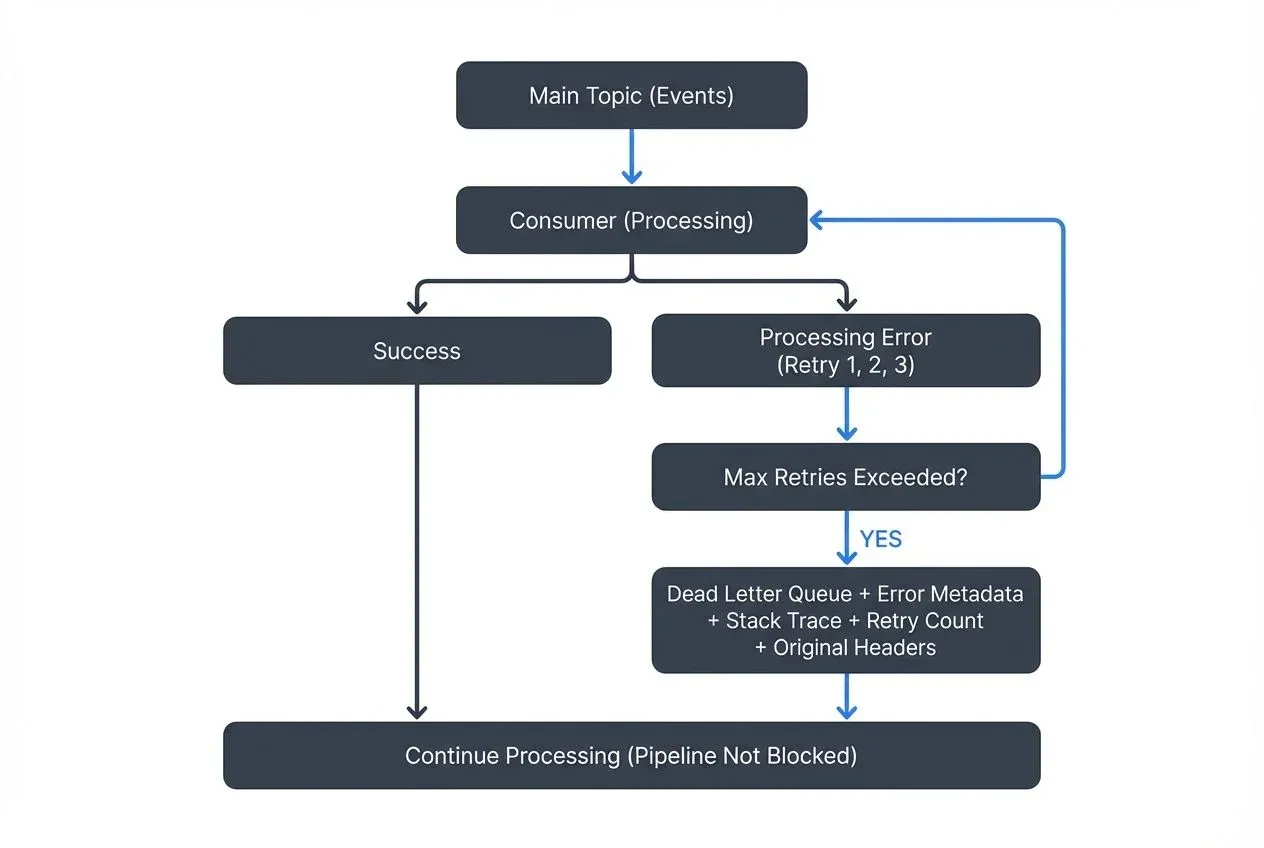
What is a Dead Letter Queue?
A Dead Letter Queue is a designated location where messages that cannot be processed successfully are sent for later inspection and handling. Rather than discarding failed messages or retrying them indefinitely, the system routes them to a separate queue where they can be examined, debugged, and potentially reprocessed.
The concept originates from traditional message queue systems but has become essential in modern streaming architectures. The core idea is simple: when a message fails processing after a defined number of retry attempts, move it to the DLQ and continue processing other messages.
This pattern prevents problematic messages from blocking the entire processing pipeline. Without a DLQ, a single corrupted message could cause a consumer to crash repeatedly, stalling all downstream processing.
How Dead Letter Queues Work
The typical DLQ flow follows these steps:
- A consumer attempts to process a message
- Processing fails due to an error (deserialization failure, validation error, downstream service unavailable)
- The system retries processing according to configured retry policies
- After exhausting retries, the message is routed to the DLQ
- The original consumer continues processing subsequent messages
- Operations teams investigate DLQ messages and determine remediation steps
Most implementations preserve metadata alongside failed messages, including error details, timestamps, retry counts, and the original topic or queue. This context is crucial for debugging and determining whether messages should be reprocessed.
Dead Letter Queues in Data Streaming
Dead Letter Queues are particularly important in data streaming platforms like Apache Kafka, where continuous processing of high-volume event streams is critical.
DLQs in Modern Kafka (KRaft Mode)
With Kafka 4.0's removal of ZooKeeper in favor of KRaft (Kafka Raft metadata mode), DLQ topic management becomes more streamlined through the KRaft metadata layer. DLQ topics benefit from faster metadata operations and improved cluster recovery times, making error handling more responsive in large-scale deployments. The simplified architecture also reduces operational complexity when managing DLQ topics across multiple environments.
Kafka Connect Error Handling
Kafka Connect provides built-in DLQ support for sink connectors (connectors that write data from Kafka to external systems like databases or cloud storage). When a sink connector cannot write a record to the destination system, it can route the failed record to a designated Kafka topic. This prevents the connector from halting on errors while preserving failed records for analysis.
Configuration example:
errors.tolerance=all
errors.deadletterqueue.topic.name=dlq-orders
errors.deadletterqueue.topic.replication.factor=3
errors.deadletterqueue.context.headers.enable=true
errors.deadletterqueue.key.serializer=org.apache.kafka.common.serialization.StringSerializer
errors.deadletterqueue.value.serializer=org.apache.kafka.common.serialization.ByteArraySerializer
errors.log.include.messages=trueThe errors.deadletterqueue.context.headers.enable setting adds headers containing error information (including the exception class name, message, and stack trace), making debugging significantly easier. The errors.log.include.messages option provides detailed error logging for faster troubleshooting. Using ByteArraySerializer for the value serializer ensures failed messages are preserved exactly as received, regardless of deserialization issues.
Stream Processing Applications
Stream processing frameworks like Kafka Streams and Apache Flink often implement custom DLQ patterns. A common approach involves catching exceptions during processing and producing failed messages to a separate topic.
Kafka Streams 3.x+ Pattern
Modern Kafka Streams applications use the FixedKeyProcessor API for DLQ handling:
// Kafka Streams 3.x+ DLQ pattern
stream.processValues(() -> new FixedKeyProcessor<K, V, ProcessedValue>() {
private FixedKeyProcessorContext<K, ProcessedValue> context;
private KafkaProducer<K, DLQRecord> dlqProducer;
@Override
public void init(FixedKeyProcessorContext<K, ProcessedValue> context) {
this.context = context;
this.dlqProducer = new KafkaProducer<>(dlqProducerConfig());
}
@Override
public void process(FixedKeyRecord<K, V> record) {
try {
ProcessedValue result = processMessage(record.value());
context.forward(record.withValue(result));
} catch (Exception e) {
// Send to DLQ with error context
DLQRecord dlqRecord = DLQRecord.builder()
.originalKey(record.key())
.originalValue(record.value())
.errorMessage(e.getMessage())
.stackTrace(getStackTrace(e))
.timestamp(System.currentTimeMillis())
.originalHeaders(record.headers())
.build();
dlqProducer.send(new ProducerRecord<>("dlq-topic", record.key(), dlqRecord));
}
}
@Override
public void close() {
if (dlqProducer != null) {
dlqProducer.close();
}
}
});This pattern maintains streaming throughput while isolating problematic messages. The FixedKeyProcessor API ensures type safety and proper key handling when routing to DLQs.
Apache Flink Side Outputs Pattern
Apache Flink 1.18+ uses side outputs for elegant DLQ routing, allowing failed messages to be processed in separate streams:
// Flink 1.18+ DLQ pattern using side outputs
OutputTag<DLQMessage> dlqTag = new OutputTag<DLQMessage>("dlq-output"){};
SingleOutputStreamOperator<ProcessedEvent> mainStream = stream
.process(new ProcessFunction<Event, ProcessedEvent>() {
@Override
public void processElement(Event event, Context ctx, Collector<ProcessedEvent> out) {
try {
out.collect(processEvent(event));
} catch (Exception e) {
// Route to DLQ side output with error context
DLQMessage dlqMessage = DLQMessage.builder()
.originalEvent(event)
.errorMessage(e.getMessage())
.stackTrace(ExceptionUtils.getStackTrace(e))
.processingTime(ctx.timestamp())
.build();
ctx.output(dlqTag, dlqMessage);
}
}
});
// Route DLQ messages to a Kafka sink
DataStream<DLQMessage> dlqStream = mainStream.getSideOutput(dlqTag);
dlqStream.sinkTo(KafkaSink.<DLQMessage>builder()
.setBootstrapServers(bootstrapServers)
.setRecordSerializer(dlqSerializer)
.build());Side outputs provide type-safe error handling without mixing failed and successful processing paths, maintaining clean stream topology.
Consumer Group Error Handling
Application consumers can implement DLQ patterns by catching processing exceptions and producing failed messages to a DLQ topic within the same transaction scope (when using Kafka transactions). This ensures atomic DLQ routing and offset commits, preventing message loss. Without transactional guarantees, DLQ routing typically provides at-least-once semantics, where a message might appear in the DLQ multiple times if the consumer crashes after producing to the DLQ but before committing the offset. For more details on transactional processing, see exactly-once semantics in Kafka and Kafka transactions deep dive.
Common Use Cases and Patterns
Dead Letter Queues address several recurring scenarios in distributed systems:
- Deserialization Failures: When message schemas evolve incompatibly or producers send malformed data, consumers may fail to deserialize messages. Rather than crashing, the consumer routes the unparseable message to a DLQ. Proper schema registry and schema management helps prevent many deserialization issues before they occur.
- Validation Errors: Business rule violations or constraint failures can render messages unprocessable. A DLQ allows these messages to be examined and potentially corrected or discarded based on business requirements.
- Transient vs. Persistent Failures: Distinguishing between temporary failures and permanent failures helps determine appropriate retry strategies:
- Transient failures: Network timeouts, downstream service temporarily unavailable, rate limit exceeded. These should be retried 3-5 times with exponential backoff before moving to DLQ.
- Persistent failures: Invalid JSON schema, malformed data, constraint violations, unsupported message version. These should be routed to DLQ immediately without retries.
Understanding this distinction prevents wasting resources retrying messages that will never succeed, while giving legitimately failed operations a chance to recover. A circuit breaker pattern (which automatically stops retry attempts after detecting repeated failures) can help prevent retry storms when transient failures become prolonged outages.
Schema Evolution Issues: When consumers cannot handle messages produced with newer schemas, DLQs provide a buffer while systems are updated to support the new format. Following schema evolution best practices helps minimize these scenarios.
Real-World Example: E-Commerce Order Processing
Consider an e-commerce system processing order events from a orders topic. The order fulfillment service encounters orders with invalid product IDs that fail inventory lookups. Rather than blocking all order processing, these problematic orders move to a dlq-orders topic.
The DLQ message includes rich context:
{
"headers": {
"original.topic": "orders",
"error.class": "ProductNotFoundException",
"error.message": "Product ID 'XYZ-999' not found in inventory database",
"retry.count": "3",
"failed.timestamp": "2025-12-16T14:30:00Z"
},
"key": "order-12345",
"value": {
"orderId": "order-12345",
"customerId": "customer-789",
"items": [{"productId": "XYZ-999", "quantity": 2}],
"total": 89.99
}
}The data quality team investigates the DLQ and discovers the issue: the product catalog synchronization job failed overnight, leaving inventory data stale. After fixing the sync issue and updating the product database, they replay the DLQ messages back to the original orders topic using their platform's DLQ management tools. The orders process successfully on the second attempt, and customers receive their fulfillment notifications. This scenario demonstrates how DLQs integrate with broader data quality dimensions and data quality incident management practices.
Best Practices and Considerations
Implementing effective DLQ strategies requires careful planning:
Monitor DLQ Growth: Rising DLQ message counts often indicate systemic issues requiring immediate attention. Set up alerts when DLQ volumes exceed thresholds. Modern observability practices using OpenTelemetry can track key DLQ metrics:
dlq.messages.total: Total count of messages routed to DLQdlq.messages.rate: Messages per second entering DLQdlq.processing.latency: Time from initial processing attempt to DLQ routingdlq.error.type: Categorization of error types (deserialization, validation, timeout)
These metrics help identify patterns and prioritize remediation efforts. Implementing comprehensive Kafka cluster monitoring and data observability practices ensures DLQ issues are detected and resolved quickly.
- Retention Policies: Configure appropriate retention for DLQ topics. Messages may need to persist longer than standard topics to allow thorough investigation.
- Include Rich Context: Capture error messages, stack traces, timestamps, and original source information. This metadata accelerates debugging and root cause analysis.
- Reprocessing Strategy: Establish clear procedures for reprocessing DLQ messages after fixing underlying issues. This might involve manual replay, automated retry with backoff, or permanent archival.
- Avoid Infinite Loops: Ensure reprocessed messages don't end up back in the DLQ. Implement circuit breakers (mechanisms that automatically stop retry attempts after detecting repeated failures) or tracking to detect and prevent retry loops.
- Separate DLQs by Error Type: Consider using different DLQ topics for different error categories (serialization errors, validation failures, downstream service errors). This enables targeted monitoring and remediation.
Conduktor Console: Inspect stream processing topology and debug stateful operators. Explore Conduktor Console →
Tooling and Platform Support
Managing Dead Letter Queues effectively requires visibility into failed messages and streamlined workflows for analysis and reprocessing.
Platforms like Conduktor provide dedicated features for DLQ management in Kafka environments. Teams can inspect DLQ messages, view error context in a unified interface, and replay messages back to source topics after resolving issues. This reduces the operational burden of manually managing DLQ topics through command-line tools or custom scripts.
Testing DLQ Behavior with Conduktor Gateway
Before deploying DLQ patterns to production, teams need confidence that error routing logic works correctly under various failure scenarios. Conduktor Gateway, a Kafka proxy, enables systematic testing of DLQ behavior through policy-based failure injection:
- Deserialization error simulation: Inject malformed data to verify DLQ routing for schema violations
- Downstream service failure testing: Simulate timeout and connection errors to validate retry logic
- Transient failure patterns: Test exponential backoff and circuit breaker behavior
- Message corruption scenarios: Verify handling of messages with missing required fields
This chaos engineering approach helps teams discover edge cases and validate DLQ configurations before encountering real production failures. Combined with comprehensive testing strategies for streaming applications, teams can build confidence in their error handling logic.
When evaluating DLQ tooling, look for capabilities including:
- Message browsing and search across DLQ topics
- Error context visualization (stack traces, headers, metadata)
- Selective or bulk message replay with filtering
- Integration with monitoring and alerting systems
- Audit trails for DLQ operations
- Failure injection for testing (via proxy like Conduktor Gateway)
These features transform DLQs from passive error repositories into active components of operational workflows.
Summary
Dead Letter Queues are essential for resilient event-driven systems. Routing failed messages to a designated queue lets the system maintain processing throughput while preserving data for analysis and remediation.
In streaming platforms like Kafka, DLQs prevent individual message failures from blocking entire pipelines. Kafka Connect provides native DLQ support, while stream processing applications implement custom DLQ patterns.
Effective DLQ implementation requires careful attention to monitoring, metadata capture, retention policies, and reprocessing strategies. With proper tooling and operational procedures, DLQs become a proactive component of system reliability, not just a fallback.
Related Concepts
- Backpressure Handling in Streaming Systems - Managing system load and preventing message failures
- Exactly-Once Semantics - Ensuring reliable message processing and DLQ routing
- Event-Driven Architecture - Architectural patterns requiring robust error handling
Sources and References
- Confluent Documentation: Kafka Connect Error Handling and Dead Letter Queues
- Apache Kafka Documentation: Kafka Streams Exception Handling
- Hohpe, G. and Woolf, B. (2003): Enterprise Integration Patterns: Designing, Building, and Deploying Messaging Solutions, Addison-Wesley Professional
- AWS Documentation: Amazon SQS Dead-Letter Queues
- Kleppmann, M. (2017): Designing Data-Intensive Applications, O'Reilly Media