Apache Kafka
Apache Kafka has become the backbone of real-time data systems. It powers everything from payment tracking to fraud detection to application logs. This article explains what Kafka is, how event streaming works, and why it matters for modern data architectures. It integrates both foundational concepts and practical operational details used in production systems today.
From Queues to Streams
Before Kafka, most systems shared data through message queues or scheduled ETL jobs. These methods moved data in batches and required tight coupling between producers and consumers.
Traditional queues worked well for point-to-point communication, but modern systems needed more: multiple consumers reading the same data, the ability to replay events after errors, and throughput in the millions of messages per second.
Streaming systems changed that model. Instead of moving data at fixed intervals, they process it continuously as events happen. Every click, transaction, or sensor reading can be captured and processed in real time.
This shift from discrete messages to immutable event streams represents a deeper change in how we think about data. Streams act as durable logs of facts that can be replayed to rebuild application state or debug failures. They bridge the gap between real-time processing and historical replay, connecting transactional systems to analytical platforms in one continuous flow.
For example, a bank can stream transactions through Kafka to detect fraud instantly while still retaining the full event history for auditing and model retraining.
What Apache Kafka Is
Apache Kafka is a distributed platform for event streaming. It is both a messaging system and a durable event store. Kafka was originally built at LinkedIn to handle high data volumes with low latency and open-sourced in 2011. Today it handles trillions of events per day in large enterprises.
Kafka plays three main roles in modern data infrastructure:
- Message Broker, Kafka decouples producers from consumers, allowing multiple applications to publish and subscribe independently.
- Storage System, Events are written to disk and replicated across brokers, enabling fault tolerance and replay from any point in time.
- Stream Processing Platform, Using Kafka Streams or external frameworks like Flink, data can be aggregated or transformed in motion.
Kafka's durability sets it apart from traditional messaging systems. It doesn't delete events once consumed. Instead, data is retained for a configurable period, allowing consumers to reprocess or recover from failures without data loss.
Core Concepts and Architecture
Kafka's architecture is designed for horizontal scalability, strong ordering, and high throughput.
Topics and Partitions
A topic is a named stream of events, like a table in a database. Topics are split into partitions, which are ordered, immutable logs of records. Each record in a partition has an offset, a unique sequential ID. Partitioning allows Kafka to scale by distributing data across servers.
For deep dives into partition assignment strategies, rebalancing, and performance implications, see Kafka Topics, Partitions, and Brokers: Core Architecture.
Brokers and Clusters
A broker is a Kafka server that stores event data and serves read/write requests. Multiple brokers form a cluster, which collectively manages replication and fault tolerance. A partition typically has one leader (handling reads/writes) and several followers that replicate data for durability. If a broker fails, a follower is promoted to leader automatically.
Cluster Coordination: From ZooKeeper to KRaft
- Critical 2025 Update: Kafka's cluster coordination mechanism has undergone a fundamental architectural change.
- ZooKeeper (Legacy, Deprecated in Kafka 4.0):
Historically, Kafka relied on Apache ZooKeeper for cluster coordination, tracking broker membership, electing partition leaders, and storing cluster metadata. ZooKeeper added operational complexity: a separate system to deploy, monitor, and scale. Organizations needed ZooKeeper expertise alongside Kafka knowledge.
KRaft (Kafka Raft Metadata Mode) - Production Ready in Kafka 3.3+: KRaft removes the ZooKeeper dependency entirely, implementing Kafka's own consensus protocol based on the Raft algorithm. This represents the biggest architectural change in Kafka's history.
Why KRaft Matters:
- Simpler operations: No ZooKeeper ensemble to manage separately
- Faster metadata operations: Leader elections complete in milliseconds instead of seconds
- Higher partition scalability: Supports millions of partitions per cluster (ZooKeeper topped out at ~200K)
- Improved recovery: Cluster recovery after failures is 10x faster
- Unified architecture: One system instead of two reduces operational surface area
KRaft Architecture: 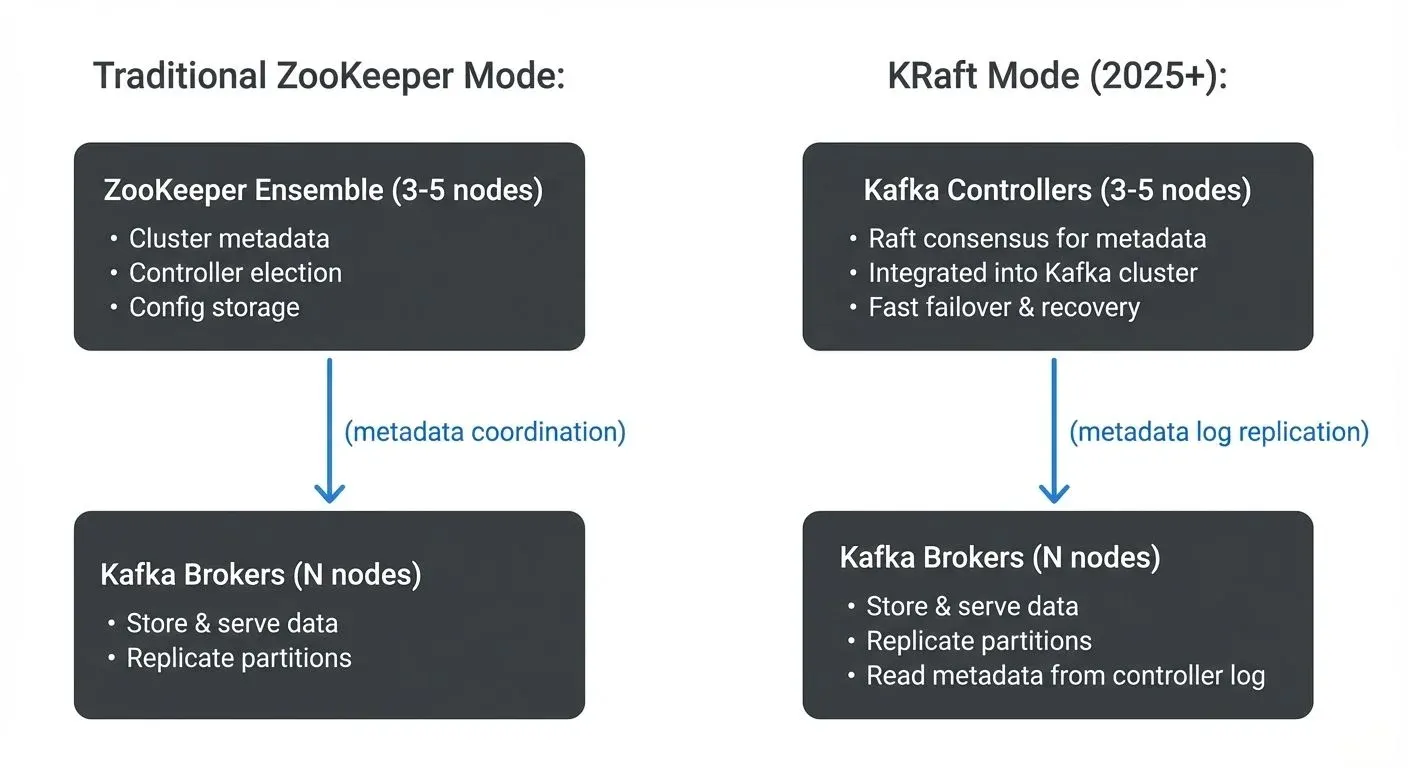 KRaft Architecture">
KRaft Architecture">
Deployment Modes:
- Combined mode: Controllers and brokers run on the same nodes (simpler for smaller clusters)
- Separated mode: Dedicated controller nodes (recommended for large production clusters)
Migration from ZooKeeper to KRaft: Kafka 3.6+ supports live migration from ZooKeeper to KRaft without downtime:
- Add KRaft controllers to existing ZooKeeper cluster
- Migrate metadata from ZooKeeper to KRaft
- Remove ZooKeeper dependency
- Continue operating in KRaft mode
When to Use KRaft:
- New deployments: All new Kafka clusters should use KRaft (ZooKeeper mode is deprecated)
- Existing clusters: Plan migration roadmap; ZooKeeper support ends in Kafka 4.0 (expected 2024-2025)
- High partition count: KRaft is essential for clusters with 100K+ partitions
- Cloud deployments: Managed services (Confluent Cloud, Amazon MSK) are transitioning to KRaft by default
Producers and Consumers
- Producers send records to topics. They can control where records go, for example, hashing by customer ID to preserve order for that key.
- Consumers read records and track their progress via offsets. They can operate independently or as part of consumer groups, which distribute partitions among members for parallelism.
For detailed consumer group mechanics, offset management, and rebalancing strategies, see Kafka Consumer Groups Explained.
A simple producer configuration might look like this:
bootstrap.servers=broker1:9092,broker2:9092
acks=all
key.serializer=org.apache.kafka.common.serialization.StringSerializer
value.serializer=org.apache.kafka.common.serialization.StringSerializer
retries=3This ensures messages are acknowledged only after full replication, providing strong durability guarantees.
How Data Flows Through Kafka
Each event in Kafka follows a clear path:
- Production, The producer serializes and sends the record to the appropriate partition.
- Replication, The leader broker writes it to disk and replicates it to follower brokers.
- Acknowledgment, The producer receives confirmation once enough replicas have written the data (based on
ackssetting). - Consumption, Consumers poll Kafka for new records and process them at their own pace.
Because consumers pull data, Kafka supports both near real-time and delayed processing. Offsets allow flexible replay and exactly-once semantics in combination with Kafka Streams or Flink.
Example: Stream Aggregation
A Kafka Streams application can aggregate events over time windows to track session activity:
stream.groupByKey()
.windowedBy(SessionWindows.with(Duration.ofMinutes(5)))
.aggregate(
SessionData::new,
(key, value, aggregate) -> aggregate.update(value),
Materialized.as("session-store")
);This type of processing lets teams build stateful real-time applications, for instance, aggregating clickstream data or monitoring user sessions without external databases.
Kafka in Modern Data Streaming
Kafka is the backbone of a broader streaming ecosystem. It connects real-time applications, analytical platforms, and machine learning pipelines.
- Change Data Capture (CDC): Tools like Debezium capture database changes and stream them into Kafka topics, eliminating polling and keeping data synchronized across systems.
- Stream Processing: Frameworks like Apache Flink consume Kafka streams to perform complex transformations and stateful analytics with exactly-once guarantees.
- Lakehouse Integration: Platforms such as Databricks or Snowflake can ingest Kafka data directly into Delta Lake or Iceberg tables, combining streaming and batch processing under a unified model.
This integration moves data from operational systems into analytical or AI pipelines. For instance, a retail company might stream purchase events into Kafka, use Flink to enrich them with customer data, and store the results in a Delta table for real-time dashboards.
End-to-End Streaming Architecture
Below is how Kafka fits into a real-world streaming ecosystem: 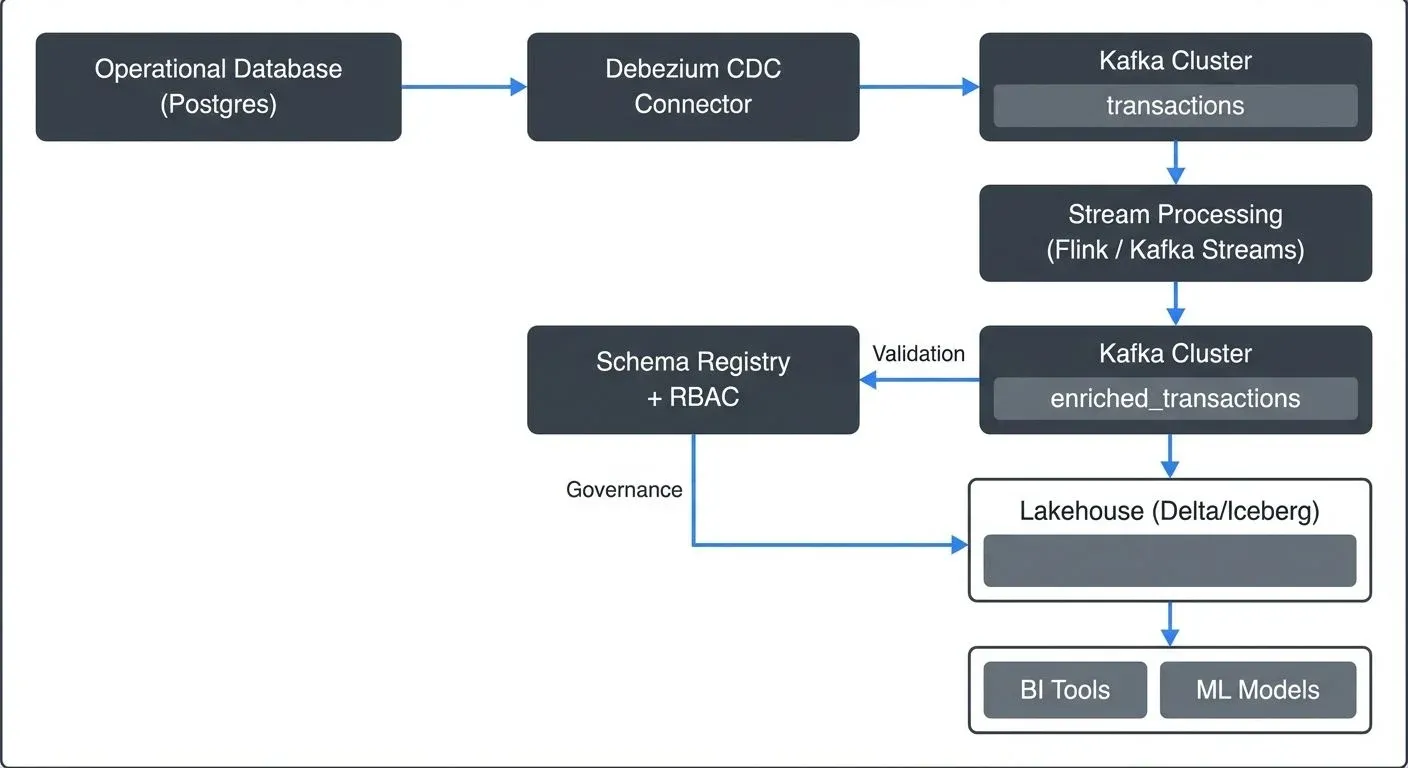
This structure shows how raw operational data flows through Kafka, gets processed and enriched in motion, and ends up in analytical and governance systems, all in near real time.
Managing Visibility, Security, and Control
Operating Kafka at enterprise scale introduces challenges that go beyond streaming performance.
Access Control and RBAC
Kafka's built-in ACLs define who can read, write, or manage topics. In large organizations with hundreds of users, this model often scales poorly. Many teams adopt Role-Based Access Control (RBAC) to simplify management. Instead of granting ACLs per user, RBAC assigns roles such as data-engineer, analyst, or auditor, each with predefined permissions. For example:
data-engineer: Can produce and consume data on development topics.analyst: Can consume from certified topics only.auditor: Read-only access to all logs and schema versions.
Governance platforms enforce and visualize these RBAC policies across clusters, integrating with LDAP or SSO providers to align identity and access.
Schema Evolution and Audit Scenario
Kafka's Schema Registry ensures producers and consumers share compatible message formats. Every schema change is versioned and validated to prevent breaking downstream systems.
In regulated environments (like finance or healthcare), teams often require data audit trails:
- When a schema changes, a record of who changed it and when must be logged.
- When sensitive data moves between topics, lineage must show where it originated and who accessed it.
- Audit teams must verify that data masking and encryption policies are consistently enforced.
Governance platforms can export audit logs, showing which topics contain sensitive data and which users or apps interacted with them. This closes the gap between data engineering and compliance without slowing down development velocity.
Observability and Governance
Monitoring Kafka involves tracking broker health, consumer lag, and throughput. Lag indicates how far a consumer is behind the producer, a key signal for diagnosing slow processing or overload.
Visibility across topics, consumer groups, and schemas is critical for debugging and compliance. Governance platforms centralize these aspects, offering:
- Dashboards for lag, throughput, and partition health
- Topic ownership tracking
- Fine-grained role-based access and field-level data masking
- Policy automation and audit logs for governance
This level of visibility turns Kafka from a raw cluster into a governed data platform, reducing operational risk while improving developer autonomy.
Common Use Cases and Next Steps
Kafka supports a wide range of real-time and data integration use cases:
- Financial Services: Fraud detection and risk scoring from live transaction streams
- E-commerce: Order events and inventory updates processed in real time
- Telecommunications: Customer behavior tracking and network event monitoring
- Data Synchronization: Database change capture pipelines feeding warehouses or lakehouses
- AI and Machine Learning: Real-time feature ingestion for model scoring
Teams often start with simple pub-sub pipelines, then evolve into event-driven architectures and stream processing. Success requires investing in schema management, governance, and developer training to handle streaming's continuous nature compared to batch data.
Summary
Apache Kafka has evolved from a simple messaging system into the foundation of real-time data infrastructure. Its durability, scalability, and ability to integrate with processing and storage systems make it central to modern streaming architectures.
Kafka enables continuous data flow between operational and analytical systems, bridging the gap between events and decisions. Yet operating it securely and transparently remains complex, a space where governance platforms provide value through access control, lineage, and observability.
Understanding Kafka's fundamentals, topics, partitions, offsets, replication, and consumers, is essential for anyone designing reliable, event-driven systems in today's data landscape.
Related Concepts
- Schema Registry and Schema Management - Essential for managing message formats and ensuring compatibility across producers and consumers in Kafka.
- Kafka Connect: Building Data Integration Pipelines - Complements Kafka's streaming capabilities by enabling seamless integration with external data systems.
- Exactly-Once Semantics in Kafka - Critical for building reliable streaming applications with strong delivery guarantees.