Schema Registry and Schema Management
In distributed data systems, ensuring that producers and consumers agree on data structure is fundamental. Schema Registry provides a centralized service for managing these data contracts, supporting safe schema evolution and maintaining data quality across your streaming infrastructure. 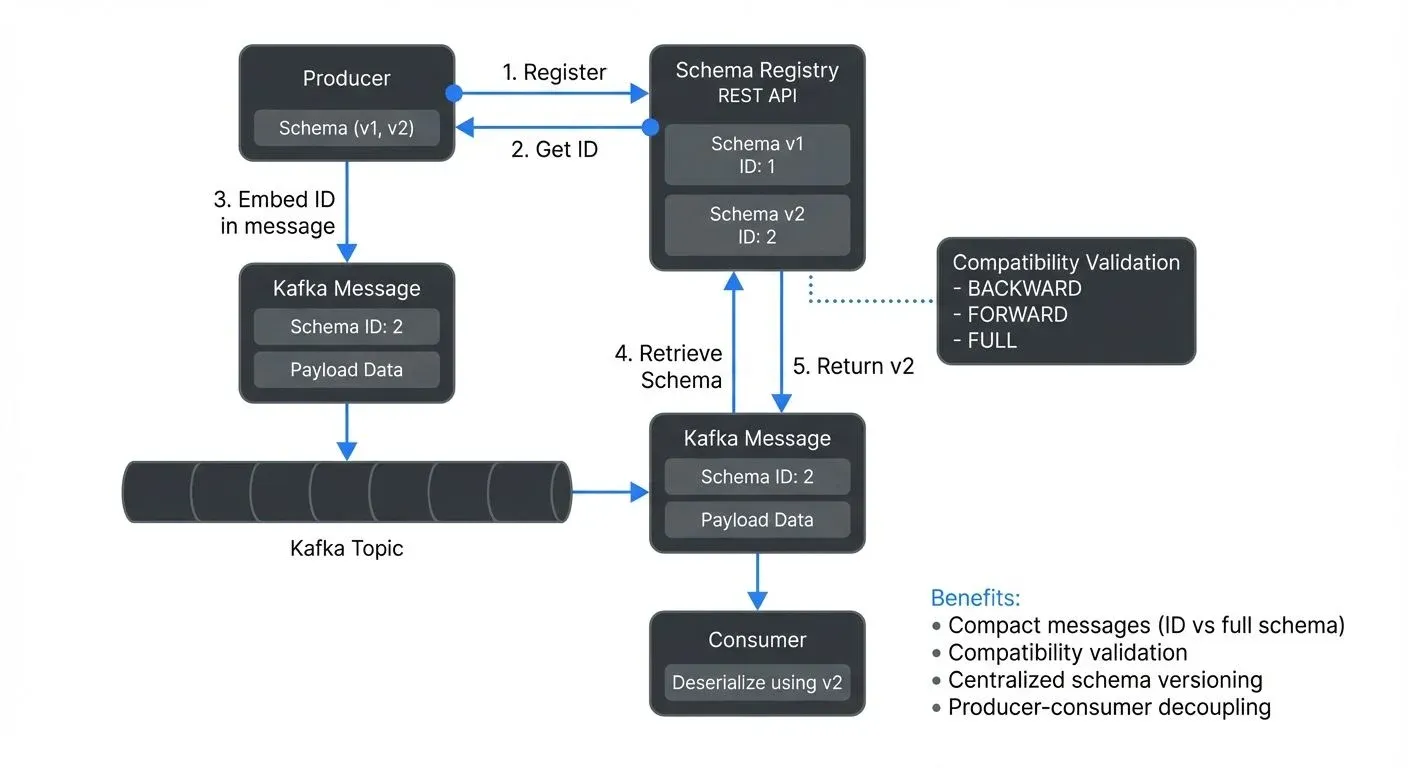
Why You Need Schema Registry
Without Schema Registry, teams face several challenges in distributed data systems:
- Data contract chaos. When producers and consumers independently define data structures, mismatches cause runtime failures. A producer adds a new required field, consumers crash trying to deserialize messages. There's no central authority enforcing compatibility.
- Message bloat. Embedding full schema definitions in every message wastes bandwidth and storage. A 1KB message might carry 5KB of schema metadata. This overhead multiplies across billions of messages.
- Version sprawl. Different teams use different schema versions with no visibility into what's actually deployed. Debugging becomes archaeology, which version produced this message? Which consumers can handle it?
- Breaking changes slip through. Without automated validation, incompatible schema changes reach production. A simple field type change breaks downstream applications, causing outages that could have been prevented.
Schema Registry solves these problems by centralizing schema storage, enforcing compatibility rules, and reducing message overhead through schema IDs. It transforms data contracts from informal agreements into enforceable policies.
What is Schema Registry?
Schema Registry is a standalone service that stores and manages schemas for your data. Think of it as a version control system for data structures. When a producer sends data to a topic, it references a schema stored in the registry. Consumers retrieve the same schema to correctly deserialize the data.
The registry assigns a unique ID to each schema version. These IDs are embedded in messages, making them compact while maintaining full schema information. This approach separates schema definition from the data itself, reducing message size and providing a single source of truth for data structures.
Beyond simple storage, Schema Registry enforces compatibility rules. Before accepting a new schema version, it validates that the change follows configured compatibility requirements. This prevents breaking changes from entering production and causing consumer failures.
How Schema Registry Works
The architecture centers on a REST API service backed by a storage layer. In most implementations (including Confluent Schema Registry), this storage layer is a Kafka topic, making the registry itself fault-tolerant and distributed. This design choice leverages Kafka's durability guarantees, the _schemas topic stores all schema registrations as an immutable log. Schema Registry instances read this topic on startup to build their in-memory cache, ensuring all instances have a consistent view. Using Kafka as storage eliminates the need for external databases and aligns the registry's availability with your Kafka cluster. As of Kafka 4.0+ (released in 2024), Schema Registry works seamlessly with KRaft mode, Kafka's ZooKeeper-less architecture that's now the default. For details on KRaft migration, see Understanding KRaft Mode in Kafka.
When a producer wants to send data, it follows this sequence:
- Serializes data according to a schema
- Checks if the schema exists in the registry
- If new, registers the schema and receives a unique ID
- Embeds the schema ID in the message header
- Sends the message to Kafka
Consumers reverse this process. They read the schema ID from the message, retrieve the schema from the registry if not cached, and deserialize the data accordingly.
The registry caches schemas locally, minimizing network calls. Schema retrieval by ID is fast because schemas are immutable once registered. This immutability is crucial for data consistency.
Code Example: Producer and Consumer
Here's how this works in practice with the Confluent Schema Registry client for Java:
Producer registering and using a schema:
import org.apache.kafka.clients.producer.*;
import org.apache.avro.Schema;
import org.apache.avro.generic.*;
import io.confluent.kafka.serializers.KafkaAvroSerializer;
// Configure producer with schema registry URL
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("schema.registry.url", "http://localhost:8081");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", KafkaAvroSerializer.class.getName());
KafkaProducer<String, GenericRecord> producer = new KafkaProducer<>(props);
// Define schema (in production, load from file)
String schemaString = """
{
"type": "record",
"name": "User",
"namespace": "com.example",
"fields": [
{"name": "id", "type": "string"},
{"name": "name", "type": "string"},
{"name": "email", "type": "string"},
{"name": "created_at", "type": "long"}
]
}
""";
Schema schema = new Schema.Parser().parse(schemaString);
// Create record - schema is automatically registered on first send
GenericRecord user = new GenericData.Record(schema);
user.put("id", "user123");
user.put("name", "Alice Johnson");
user.put("email", "alice@example.com");
user.put("created_at", System.currentTimeMillis());
// Send message - schema ID is embedded automatically
ProducerRecord<String, GenericRecord> record =
new ProducerRecord<>("users", "user123", user);
producer.send(record);
producer.close();Consumer retrieving and using the schema:
import org.apache.kafka.clients.consumer.*;
import org.apache.avro.generic.GenericRecord;
import io.confluent.kafka.serializers.KafkaAvroDeserializer;
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("schema.registry.url", "http://localhost:8081");
props.put("group.id", "user-processor");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", KafkaAvroDeserializer.class.getName());
props.put("specific.avro.reader", "false"); // Use GenericRecord
KafkaConsumer<String, GenericRecord> consumer = new KafkaConsumer<>(props);
consumer.subscribe(List.of("users"));
while (true) {
ConsumerRecords<String, GenericRecord> records =
consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, GenericRecord> record : records) {
GenericRecord user = record.value();
// Schema is automatically retrieved using embedded schema ID
System.out.println("User ID: " + user.get("id"));
System.out.println("Name: " + user.get("name"));
System.out.println("Email: " + user.get("email"));
}
}The serializer automatically registers the schema on the first message send and caches the schema ID for subsequent messages. The deserializer retrieves the schema using the embedded ID and caches it locally, avoiding repeated registry lookups.
Schema Evolution and Compatibility
Data structures change over time. You add new fields, deprecate old ones, or modify field types. Schema Registry manages these changes through compatibility modes that define allowed evolution patterns.
Compatibility Modes Explained
Schema Registry enforces compatibility through several modes. Understanding which to use depends on your upgrade strategy:
Backward Compatibility (BACKWARD), Most common mode. New schema versions can read data written with older schemas. Consumers upgrade first, then producers.
Example using Avro schema:
// Version 1
{
"type": "record",
"name": "User",
"fields": [
{"name": "name", "type": "string"},
{"name": "email", "type": "string"}
]
}
// Version 2 (Backward Compatible)
{
"type": "record",
"name": "User",
"fields": [
{"name": "name", "type": "string"},
{"name": "email", "type": "string"},
{"name": "phone", "type": ["null", "string"], "default": null}
]
}Consumers using version 2 can process messages written with version 1 by applying the default value for the missing phone field.
Forward Compatibility (FORWARD), Old schema versions can read data written with new schemas. Producers upgrade first, then consumers. Useful when you control producer deployments but not consumer deployments.
Example: Removing an optional field is forward compatible because old consumers simply ignore the missing field.
- Full Compatibility (FULL), Both backward AND forward compatible. The most restrictive mode. Only modifications like adding or removing optional fields with defaults satisfy this requirement. Use this when upgrade order is unpredictable or when you have long-lived messages in topics.
- Backward Transitive (BACKWARD_TRANSITIVE), New schema must be compatible with ALL previous versions, not just the latest. Useful for topics with long retention where consumers might process very old messages.
- Forward Transitive (FORWARD_TRANSITIVE), All previous schemas can read data written with the new schema.
- Full Transitive (FULL_TRANSITIVE), New schema is both backward and forward compatible with all previous versions. The strictest mode, offering maximum flexibility for consumers at different versions.
- None (NONE), Disables validation entirely. Maximum flexibility but zero safety guarantees. Use only during initial development or when you're certain about compatibility.
Choosing a Compatibility Mode
| Mode | When to Use | Upgrade Order |
|---|---|---|
| BACKWARD | Most common; allows adding optional fields | Consumers first |
| FORWARD | When consumers lag behind producers | Producers first |
| FULL | Unpredictable upgrade order | Any order |
| BACKWARD_TRANSITIVE | Long topic retention; process old messages | Consumers first |
| FULL_TRANSITIVE | Multiple schema versions in use simultaneously | Any order |
| NONE | Initial development only | N/A |
Schema Registry in Data Streaming
Schema Registry integrates deeply with streaming platforms. For comprehensive coverage of Apache Kafka fundamentals, see Apache Kafka.
In Kafka ecosystems, the registry works seamlessly with serializers and deserializers. Kafka producers use schema-aware serializers (like Avro, Protobuf, or JSON Schema serializers) that automatically register schemas and embed schema IDs. Consumers use corresponding deserializers that fetch schemas and reconstruct objects.
For stream processing with Apache Flink, schema registry integration enables type-safe transformations. Flink can derive table schemas from registry definitions, ensuring consistency between streaming data and SQL queries. To understand Flink's stateful processing capabilities, see What is Apache Flink: Stateful Stream Processing.
In event-driven architectures, Schema Registry serves as a contract between services. Teams can evolve their event formats independently while maintaining compatibility guarantees. This decoupling enables faster development without coordination overhead. For deeper exploration of event-driven patterns, see Event-Driven Architecture. Conduktor provides visual interfaces for browsing schemas, testing compatibility changes, and managing schema governance policies, helping teams understand schema usage and impact before making changes in production. For detailed guidance on managing schemas with Conduktor, see Conduktor's Schema Registry Management.
Schema Formats and Serialization
Schema Registry supports multiple serialization formats, each with distinct characteristics.
- Apache Avro is the most widely adopted format. It provides compact binary serialization, rich schema evolution features, and strong typing. Avro schemas are defined in JSON, making them human-readable. The combination of schema registry and Avro reduces message size significantly compared to JSON while maintaining flexibility.
- Protocol Buffers (Protobuf) offers efficient serialization and code generation for multiple languages. Protobuf is popular in microservices architectures where type-safe client libraries are valuable. Schema evolution is handled through field numbers rather than names.
- JSON Schema validates JSON documents against defined structures. While JSON is less compact than binary formats, it remains human-readable and widely supported. JSON Schema works well when interoperability and debugging ease outweigh performance concerns.
The choice depends on your requirements. Avro excels in data streaming scenarios with dynamic schemas. Protobuf suits service-to-service communication with strong typing. JSON Schema bridges systems where JSON is already standard. For detailed comparison of these formats including performance benchmarks and evolution capabilities, see Avro vs Protobuf vs JSON Schema.
Schema Registry Implementations
While Confluent Schema Registry pioneered centralized schema management, several implementations now exist for different deployment scenarios and requirements.
- Confluent Schema Registry remains the reference implementation and most widely adopted solution. Originally developed by Confluent, it's open-source (Apache 2.0 license) and uses Kafka itself as the storage backend, providing built-in fault tolerance and scalability. The registry runs as a standalone service with a REST API that producers and consumers use for schema operations. Using Kafka for storage means the registry inherits Kafka's durability guarantees and can be deployed alongside your Kafka cluster. As of 2025, Confluent Platform 7.7+ includes enhanced features like tag-based schema organization and improved schema validation rules beyond basic compatibility checking.
- Apicurio Registry (developed by Red Hat) is a fully open-source alternative that supports multiple storage backends including Kafka, PostgreSQL, and in-memory storage. This flexibility allows teams to choose storage based on their infrastructure. Apicurio provides additional features like content validation rules that go beyond compatibility checking, artifact grouping for organizing schemas by domain or team, and a web UI for schema browsing. It's particularly popular in Red Hat OpenShift environments and supports not just schemas but also API definitions and AsyncAPI specifications.
- AWS Glue Schema Registry integrates natively with AWS services including Amazon MSK (Managed Streaming for Apache Kafka) and Amazon Kinesis Data Streams. Schemas are stored in AWS-managed infrastructure with automatic versioning and encryption at rest. The service provides native SDK integrations for Java, Python, and other languages. For teams already in the AWS ecosystem, Glue Schema Registry eliminates the need to manage separate infrastructure. It supports Avro, JSON Schema, and Protobuf formats.
- Karapace (developed by Aiven) is an open-source, API-compatible alternative to Confluent Schema Registry, written in Python and designed for cloud-native deployments. It provides the same REST API endpoints as Confluent Schema Registry, making it a drop-in replacement. Karapace uses PostgreSQL as its storage backend and includes additional features like schema backup and restore capabilities. It's particularly suited for Kubernetes deployments and teams preferring Python-based tooling.
Unified Schema Management with Conduktor
For organizations using multiple schema registry implementations or managing schemas across different environments, Conduktor provides a unified management interface. Conduktor connects to various schema registry backends (Confluent, Apicurio, AWS Glue) and offers:
- Visual schema editing and browsing with syntax validation
- Interactive compatibility testing before applying changes
- Schema governance workflows with approval processes
- Schema usage tracking showing which applications use which schemas
- Cross-environment schema promotion (dev → staging → production)
- Team collaboration features with role-based access control
This unified approach is especially valuable in multi-cloud or hybrid environments where different teams might use different registry implementations but need consistent governance policies.
Security and Performance Considerations
Security
Schema Registry security involves multiple layers to protect your data contracts:
- Authentication and authorization. Most implementations support authentication via SSL/TLS client certificates, SASL mechanisms (PLAIN, SCRAM, OAUTHBEARER), or integration with identity providers. Authorization controls which users or applications can register new schemas versus only read existing ones. Confluent Platform integrates with LDAP/Active Directory for enterprise authentication.
- Encryption. Protect schemas in transit using HTTPS for REST API calls and SSL/TLS for Kafka connections (where schemas are stored). Enable encryption at rest for the underlying Kafka topics to protect stored schema definitions. For comprehensive security patterns, see Encryption at Rest and in Transit for Kafka.
- Network isolation. Deploy Schema Registry in private networks, accessible only from your application layer. Use network policies or security groups to restrict access. Avoid exposing the registry directly to the public internet.
Performance and Scaling
Schema Registry is designed for high throughput with minimal latency:
- Caching strategy. Both producers and consumers cache schemas locally after first retrieval. Schema IDs are stable, so once cached, applications rarely need to contact the registry. This design scales to millions of messages per second with minimal registry load.
- Registry cluster sizing. For most workloads, 3-5 Schema Registry instances provide sufficient redundancy and capacity. Each instance maintains a full in-memory cache of all schemas. The registry is read-heavy, most operations are schema retrievals by ID, which are served from memory.
- Storage considerations. The
_schemasKafka topic typically remains small (megabytes to low gigabytes) even in large deployments. Each schema version is stored once, regardless of message volume. Configure appropriate retention for this topic (often infinite retention with compaction enabled). - Monitoring. Track key metrics including schema registration rate, retrieval latency, cache hit ratio, and compatibility check duration. High retrieval latency or low cache hit ratios indicate configuration issues. For detailed monitoring patterns, see Consumer Lag Monitoring for related Kafka monitoring approaches.
Schema Management Best Practices
Effective schema management requires organizational discipline and technical guardrails.
- Use semantic versioning principles. Treat schema changes like code changes. Minor versions should be backward compatible, while major versions signal breaking changes. Document what changed and why.
- Establish naming conventions for subjects. In Schema Registry, a "subject" is the identifier for a schema and its version history. Subject names should follow consistent patterns across your organization. The two most common strategies are:
- Topic-based naming:
-key -value users-value,orders-key) - Record-based naming: Fully-qualified class names (e.g.,
com.example.User,com.example.Order)
Topic-based naming couples schemas to Kafka topics, making it easy to find which schema a topic uses. Record-based naming decouples schemas from topics, allowing schema reuse across multiple topics. Choose based on whether you expect schema reuse or prefer tight topic-schema coupling.
- Implement schema validation in CI/CD pipelines. Test schema changes against existing data before deployment. Automated compatibility checks catch issues early. Conduktor enables testing environments where teams can validate changes against production-like conditions.
- Document your schemas. Add descriptions to fields explaining their purpose and valid values. Future maintainers will thank you. Schema documentation becomes your data contract specification. For comprehensive guidance on defining and enforcing data contracts, see Data Contracts for Reliable Pipelines.
- Monitor schema usage. Track which schema versions are actively used. Old versions with no traffic can potentially be deprecated. Understanding schema adoption patterns informs migration planning.
- Control schema registration permissions. Not every application should register schemas directly. Central teams often manage canonical schemas while application teams consume them. This governance prevents schema sprawl and maintains data quality.
- Integrate with data catalogs. Modern data catalogs can discover schemas from Schema Registry and provide additional metadata like business glossary terms, data ownership, and lineage visualization. This integration bridges technical schemas with business context. For comprehensive coverage of catalog capabilities, see What is a Data Catalog: Modern Data Discovery.
- Plan for multi-region deployments. If your Kafka cluster spans multiple regions or data centers, consider schema replication strategies. Confluent Platform 7.0+ introduced Schema Linking for automatic schema replication across clusters. Alternative approaches include CI/CD-based promotion or manual schema synchronization. For disaster recovery strategies, see Disaster Recovery Strategies for Kafka Clusters.
Summary
Schema Registry provides essential infrastructure for managing data structures in distributed systems. It is a centralized repository for schema definitions, enforces compatibility rules during evolution, and enables efficient serialization through schema ID embedding.
The registry integrates naturally with streaming platforms like Kafka and Flink, providing the foundation for type-safe data pipelines. By validating compatibility before accepting new schemas, it prevents breaking changes that would cause consumer failures.
Successful schema management combines technical controls (compatibility modes, validation pipelines) with organizational practices (naming conventions, documentation, governance). Together, these elements create reliable data contracts that enable teams to evolve systems independently while maintaining consistency.
Whether using Avro, Protobuf, or JSON Schema, the principles remain constant: centralized schema storage, versioning, compatibility validation, and efficient serialization. These capabilities turn schema management from a coordination burden into a foundation for agile, decoupled development.
Related Concepts
- Schema Evolution Best Practices - Learn how to safely evolve schemas managed by Schema Registry while maintaining producer-consumer compatibility.
- Message Serialization in Kafka - Understand how Schema Registry integrates with serialization formats like Avro, Protobuf, and JSON Schema.
- Data Contracts for Reliable Pipelines - Discover how Schema Registry enforces data contracts between producers and consumers in streaming pipelines.
Sources and References
- Confluent Schema Registry Documentation - Official documentation covering architecture, API, and compatibility modes: https://docs.confluent.io/platform/current/schema-registry/index.html
- Kleppmann, Martin. "Designing Data-Intensive Applications" (Chapter 4: Encoding and Evolution) - Comprehensive coverage of schema evolution patterns and serialization formats
- Apache Avro Documentation - Specification and best practices for Avro schema design: https://avro.apache.org/docs/current/
- Confluent Blog: "Yes, Virginia, You Really Do Need a Schema Registry" - Practical insights on schema registry benefits and use cases: https://www.confluent.io/blog/schema-registry-kafka-stream-processing-yes-virginia-you-really-need-one/
- AWS Glue Schema Registry Documentation - Alternative implementation showing schema registry in cloud environments: https://docs.aws.amazon.com/glue/latest/dg/schema-registry.html