Conduktor Insights
Stop Firefighting. Start Predicting.
Your Kafka monitoring shows what's happening now. Insights shows what's about to break.
Trusted by














The Hidden Cost: You Can't Fix What You Can't See
Most organizations discover Kafka problems during incidents. By then, the damage is done.
Silent Data Loss Risks
RF=1 with active consumers means zero redundancy on data people depend on. One broker failure, and it's gone.
Zombie Resources
100GB of storage with zero consumers. You're paying for data nobody reads.
Partition Problems
Too few partitions and you can't scale. Too many and you're wasting resources and slowing consumers.
Unknown VIPs
Which topics are business-critical? Without visibility, every topic gets the same treatment - or neglect.
Five Pillars of Kafka Intelligence
Conduktor Insights analyzes every topic across five dimensions to surface exactly where to focus.
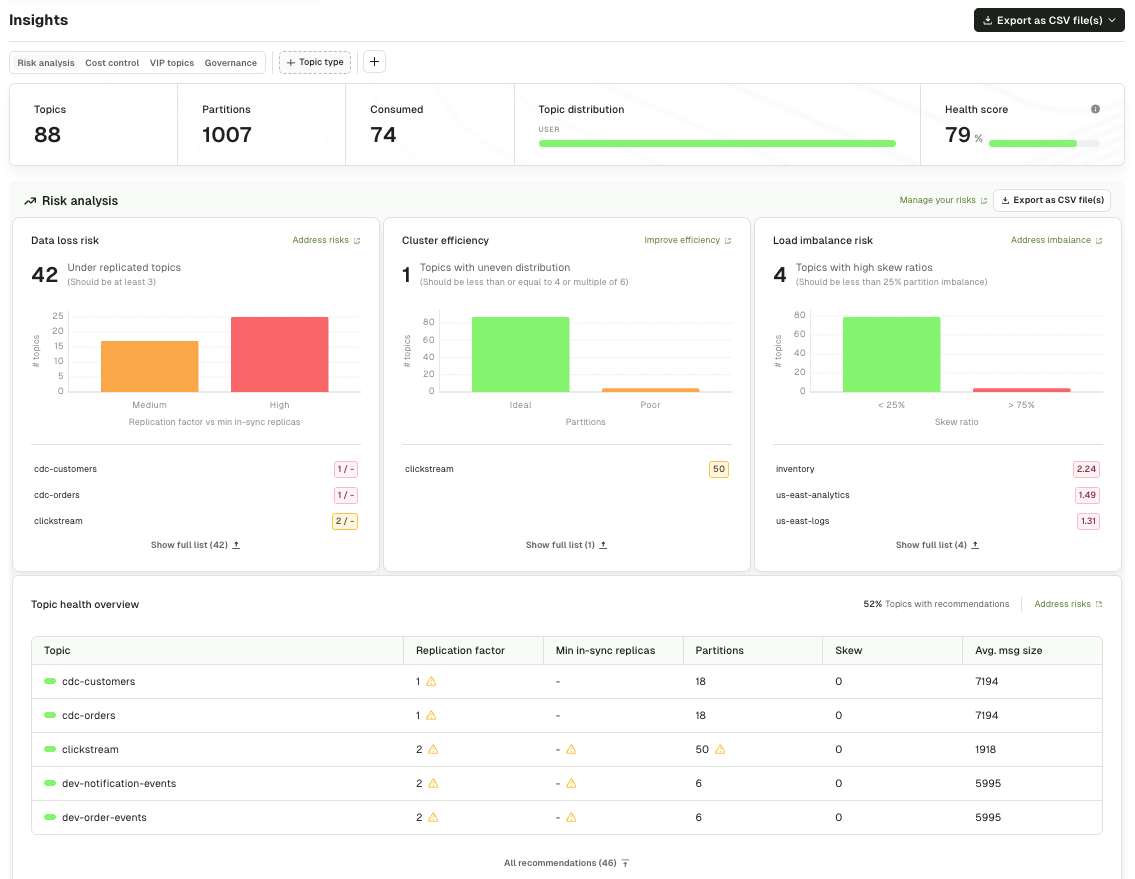
Risk Analysis
Identify Risks Before They Become Incidents
Find topics that could cause data loss, performance degradation, or service disruptions. Insights correlates replication, volume, and consumer activity to surface risks that simple threshold alerts miss.
- Low replication factor detection: Find single-replica topics instantly
- Partition skew analysis: Identify uneven data distribution
- Single partition bottlenecks: Spot topics that can't scale
- Actionable remediation recommendations
Cost Control
Eliminate Waste, Optimize Resources
Find topics burning storage that nobody uses. Empty topics, stale data, and tiny topics clutter your cluster and waste resources.
- Empty topics: Abandoned topics cluttering your namespace and adding metadata overhead
- Stale topics: No activity for configurable time periods
- Tiny topics: Minimal data that could be consolidated
- Resource utilization insights and cleanup recommendations
VIP Topics
Identify High-Impact Topics Automatically
Automatically identify your most critical topics based on consumer activity, message throughput, and fanout patterns. Prioritize what matters most.
- High consumer count: Topics where one failure cascades to dozens of services
- Message volume analysis: Your highest-traffic data streams
- Fanout detection: Topics feeding multiple services
- Optimization recommendations for critical topics
Governance
Ensure Compliance and Standards
Track schema registry adoption, serialization format consistency, and self-service provisioning coverage across your organization. Surface compliance gaps before auditors do.
- Schema coverage metrics: Topics with registered schemas
- Serialization format distribution: Avro, JSON, Protobuf usage
- Self-service coverage: Topics provisioned through proper channels
- Compliance gap detection: PII without masking, retention policies that violate requirements
Topic Health
Actionable Health Recommendations
Get a comprehensive health score for your entire cluster and detailed recommendations for each topic that needs attention.
- Cluster health score: Instant 0-100 assessment
- Per-topic configuration recommendations
- Retention policy optimization suggestions
- Prioritized action items based on impact
Impact
Measurable impact from teams using Conduktor Insights.
Customers regularly find the majority of their topics are stale or abandoned.
Eliminate empty, stale, and tiny topics wasting storage and compute.
Instant visibility without complex setup or configuration.
Every topic analyzed across all five intelligence pillars.
Get Started with Kafka Insights
Move from reactive to predictive Kafka management. Get a personalized walkthrough of Conduktor Insights.
How is Insights different from Prometheus/Grafana?
Monitoring tells you what's happening now. Insights tells you what's about to become a problem. We analyze patterns across topics to surface risks you'd never think to alert on - like partition skew ratios or topics with RF=1 that haven't failed yet.
Do I need a large Kafka deployment to benefit?
No. Even small deployments accumulate hidden problems - empty topics, stale resources, configuration drift. Insights surfaces issues regardless of cluster size.
How does Insights integrate with my existing setup?
Insights connects read-only to your Kafka clusters. No agents to install, no code changes required. Works with Confluent, AWS MSK, Redpanda, and self-managed Kafka. See the integration guide.