Data Mesh Explained: Decentralized Data Ownership for Scalable Organizations
Data mesh decentralizes ownership for agility and scale. Learn core principles, architecture, and how Kafka + Conduktor enable domain-driven data products.


Data mesh decentralizes data ownership to increase agility, autonomy, and scalability in large organizations. Zhamak Dehghani, a software architect at ThoughtWorks, first proposed the concept in May 2019. Since then, data and technology leaders have adopted it to escape the limitations of centralized data management.
Data mesh shares DNA with domain-driven design (DDD) and microservices. All three prioritize team autonomy and modular systems. The paradigm shift is clear: move away from centralized data warehouses or lakes managed by a single team. Instead, treat data as a product owned, governed, and delivered by domain teams across the organization.
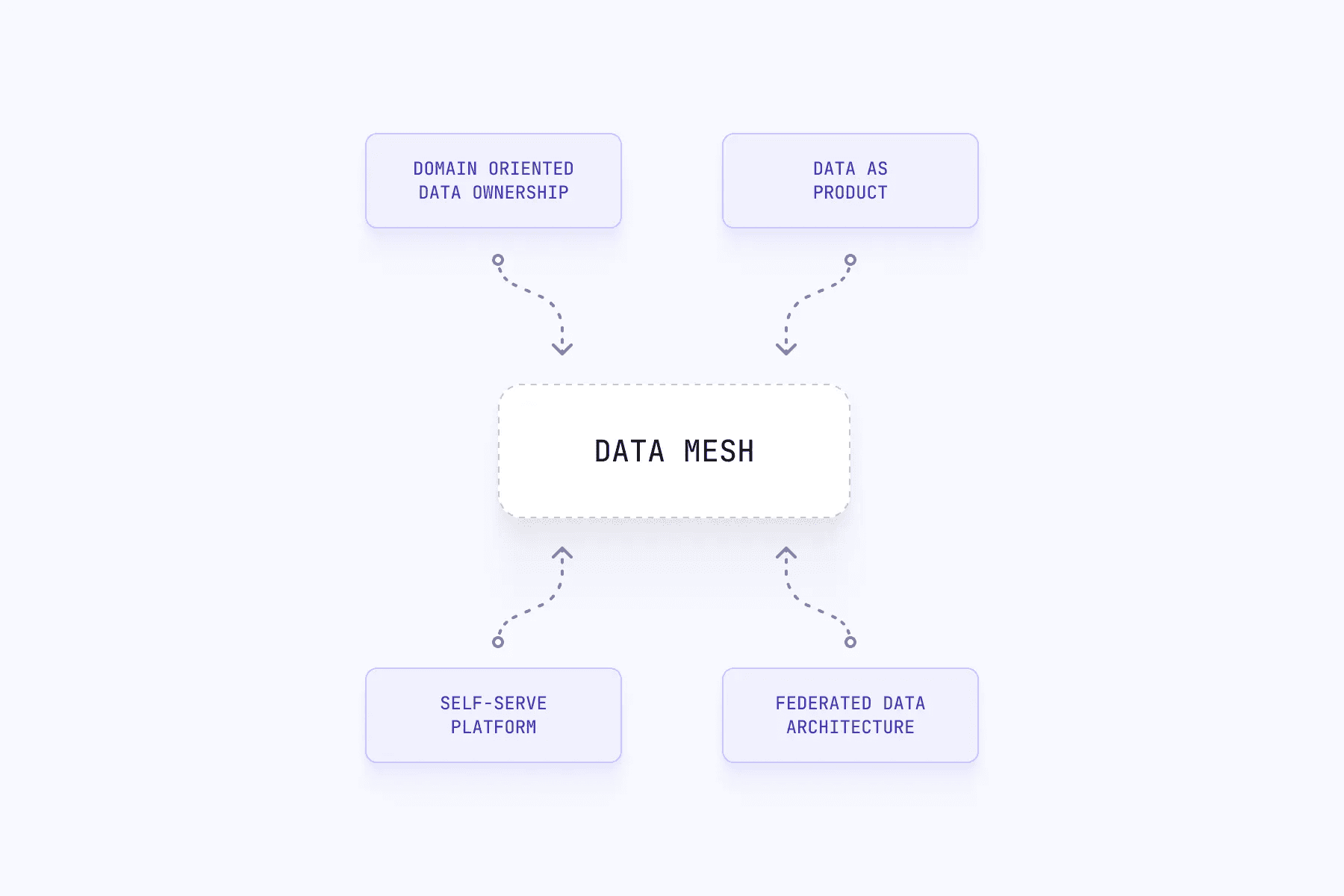
The Four Core Principles of Data Mesh
Domain-oriented decentralized data ownership. Data belongs to the domain experts who understand it best, not a central data team. This creates accountability and keeps data accurate, relevant, and current.
Data as a product. Domain teams design, develop, and maintain data products focused on delivering value to internal and external customers. This fosters experimentation, iteration, and continuous improvement.
Federated data architecture. Data products are discoverable, reusable, and composable. Teams can collaborate and share data without central bottlenecks.
Self-serve data infrastructure. Teams access infrastructure to discover, access, and process data independently. No waiting on centralized teams for basic needs.
How Data Mesh Architecture Works
Data mesh consists of four main components:
Domain-Oriented Teams: Responsible for developing and maintaining data products within their domain. Each team understands its business context and makes autonomous decisions about their data products.
Data Products: Self-contained, modular pieces of data infrastructure. Each solves a specific business problem and owns its data quality, governance, and delivery.
Platform Services: Centrally managed infrastructure for storage, compute, and security. Provides consistency across domains without centralizing data ownership.
Data Mesh Bus: A shared communication layer enabling data products to communicate with each other and external systems. Allows composition and orchestration for complex business problems.
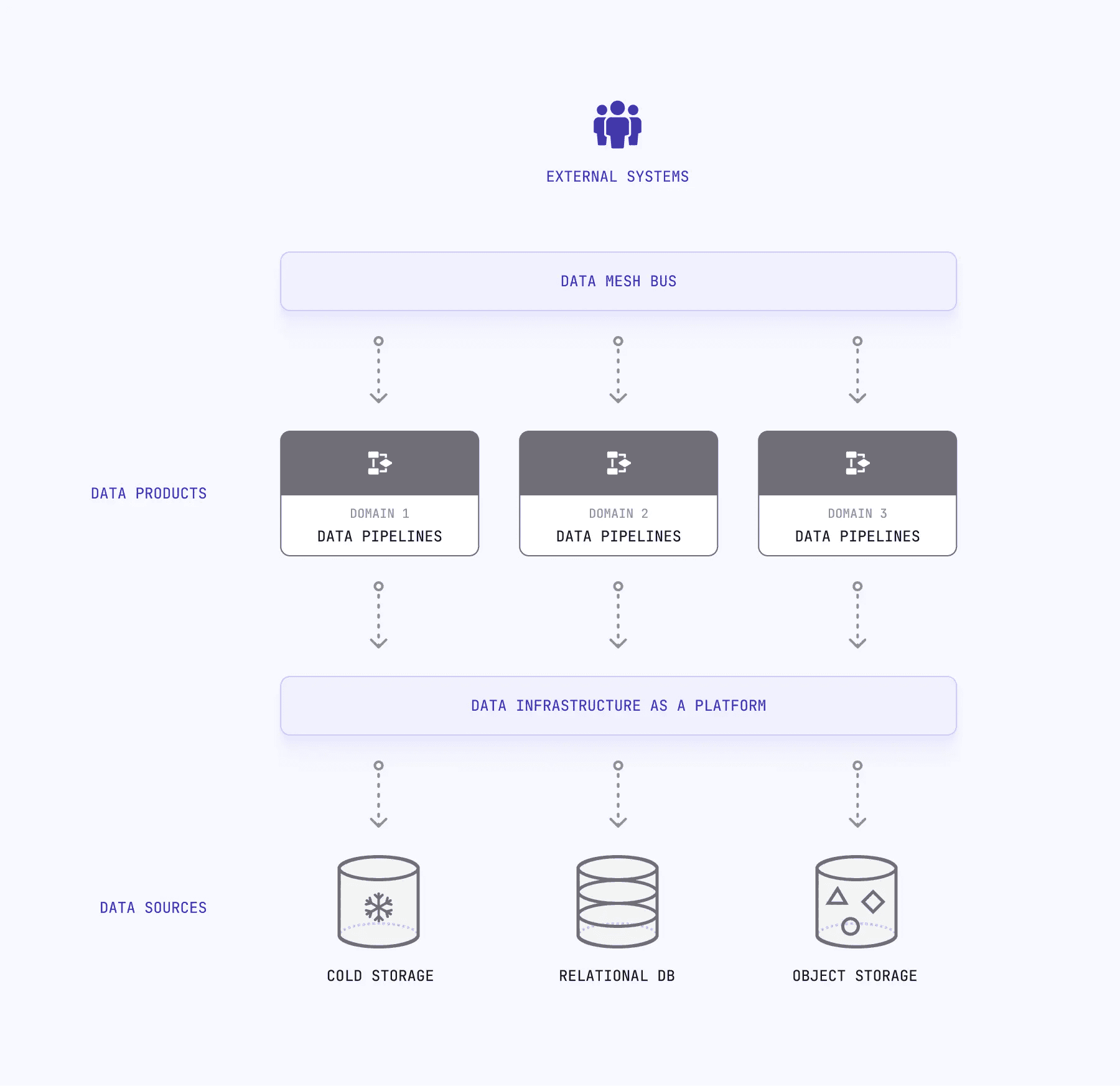
The architecture is inherently distributed. Domain teams develop data products aligned with business needs and deliver value faster. Platform services provide infrastructure support. The data mesh bus enables composition across products.
Domain-Oriented Ownership Replaces Central Data Teams
A domain represents people with a common business function: sales, marketing, customer service. Domain-oriented ownership means data experts own their data, not a distant central team.
Domain teams develop data products for specific business needs. They think like product managers: delivering value to customers, iterating based on feedback.
Data pipelines support this model. They move data from source to destination. Domain teams build and manage their own pipelines, eliminating dependencies on central teams.
Why Centralized Data Architecture Fails at Scale
Traditional data platforms center on a data warehouse maintained by a small team of specialists. As data volume grows, these teams drown in requests.
Centralized architecture adapts slowly to business changes. Data teams manage infrastructure and develop products, creating bottlenecks. Development cycles stretch. Time-to-market slows. Organizations cannot respond to shifting requirements.
Siloed data compounds the problem. Departments duplicate effort, data becomes inconsistent, and collaboration suffers.
Data mesh fixes this by distributing ownership. Domain teams collaborate and share knowledge. Reusable data products spread across the organization.
When Your Organization Needs Data Mesh
Data mesh fits organizations that value autonomy, operate in fast-paced environments, and have:
Organizational structure alignment. Data mesh requires domain teams with strong data expertise and a culture of collaboration. If your structure cannot support autonomous teams, data mesh will struggle.
Technical capability. Implementation requires data engineering, data science, and DevOps skills. Cloud computing and big data infrastructure must be in place or planned.
Data governance maturity. Strong governance practices ensure quality, consistency, and security. Without existing policies, processes, and tools, data mesh amplifies chaos rather than reducing it.
Change management capacity. Adopting data mesh changes how everyone works with data. Training and communication determine success.
Data Observability Ensures Quality Across Distributed Teams
Data observability means measuring, monitoring, and understanding data behavior in real-time. With distributed ownership, observability becomes critical.
Domain teams monitor their data products in real-time. Issues surface and get fixed before they cascade. Products stay consistent with governance policies.
Observability creates transparency. Teams share information about their data products. Trust builds. Collaboration improves.
Performance optimization follows naturally. Real-time monitoring reveals bottlenecks and inefficiencies. Teams optimize pipelines based on actual behavior.
Concrete Benefits of Data Mesh
Faster adaptation. Domain teams independently develop and iterate on data products without waiting for central approval.
Better data quality. Owners understand their data. They keep it accurate and relevant.
Shorter time-to-market. Teams ship data products quickly.
Easier scaling. Federated architecture enables sharing and reuse across the organization.
Cross-functional collaboration. Domain teams share knowledge instead of protecting silos.
Distributed governance. Each domain manages data securely and compliantly within its context.
Kafka and Conduktor Enable Data Mesh Implementation
Apache Kafka fits data mesh architecture naturally. It provides a scalable, distributed, fault-tolerant platform for streaming data. As the backbone of the data mesh bus, Kafka enables flexible, decentralized architecture where domain teams own their data products while keeping data available across the organization.
Conduktor provides enterprise tooling for Kafka: monitoring, managing, and developing Kafka-based applications. Teams get a centralized platform for Kafka tasks, including real-time cluster monitoring, schema management, and workflow tools. Domain teams still own their data products. Conduktor adds infrastructure and governance for quality and security.
Conduktor's Topic as a Service (TaaS) crystallizes this: developers from individual teams create, update, share, and promote Kafka resources with automated approval from the central platform team.