Data Product Governance: Building Trustworthy Data Assets
As organizations shift from centralized data platforms to distributed data architectures, the concept of data products has become a fundamental building block. Treating data as a product isn't just about technology — it requires a governance framework that ensures data products are discoverable, trustworthy, and valuable to their consumers. This article covers how to establish governance practices that turn raw data streams into reliable, well-managed data products.
For an overview of data products in practice, see Building and Managing Data Products. For organizational structures and responsibilities, refer to Data Governance Framework: Roles and Responsibilities. 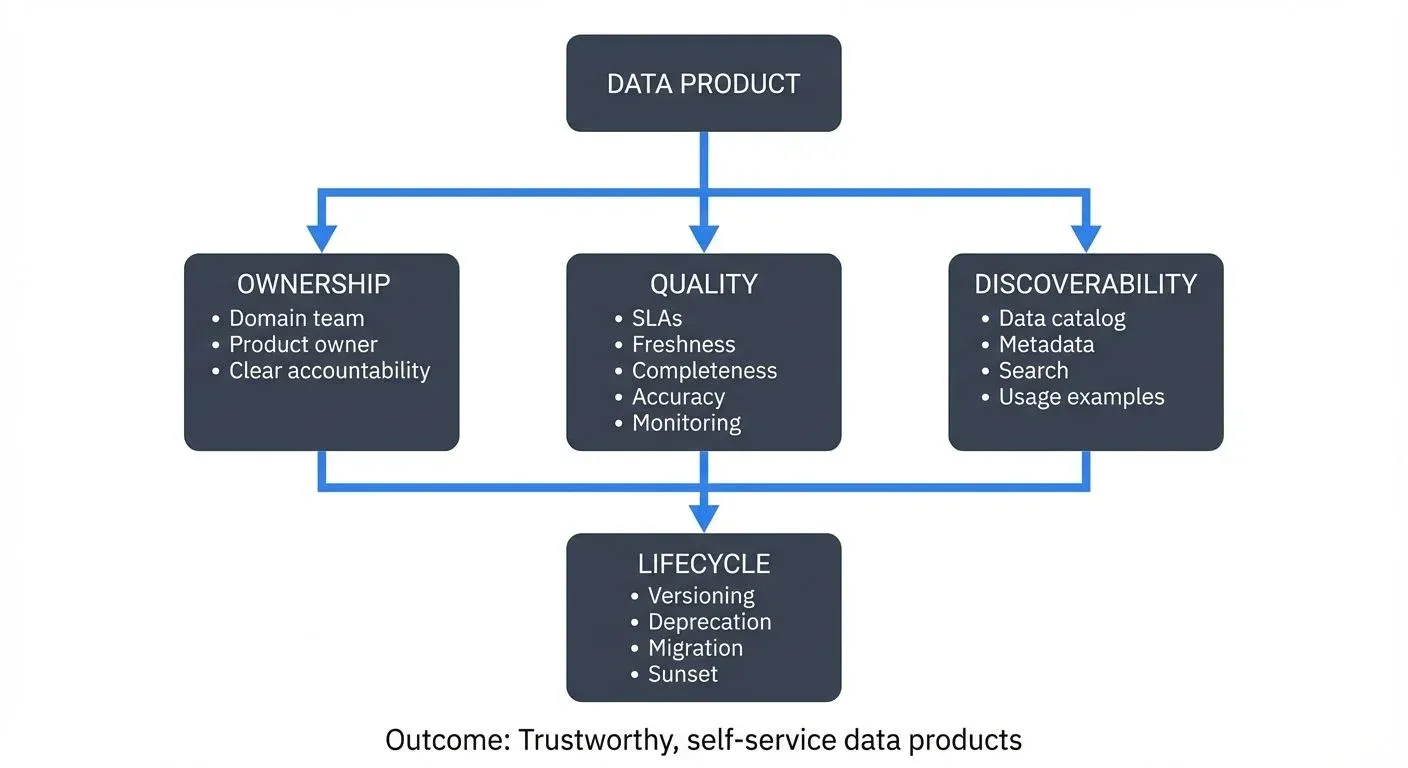
Understanding Data Products
A data product is more than just a dataset or a collection of raw data. It's a self-contained, intentionally designed data asset that serves a specific analytical or operational purpose. While raw data might be the unprocessed events flowing through your Kafka topics, and a dataset might be a static snapshot extracted for analysis, a data product is:
- Purposefully designed with specific consumer needs in mind
- Self-describing with comprehensive metadata and documentation
- Quality-assured with explicit guarantees about freshness, completeness, and accuracy
- Actively maintained with clear ownership and SLAs
- Discoverable through catalogs and standardized interfaces
For example, a "Customer 360 Profile" data product aggregates customer interactions, purchases, and preferences into a unified view with guaranteed freshness within 5 minutes, far more valuable than raw clickstream events or isolated transactional datasets.
Core Data Product Principles
Effective data product governance rests on several foundational principles:
- Ownership: Every data product must have a designated owner, typically a domain team that understands the business context and can make decisions about the product's evolution. This isn't just a name in a spreadsheet; owners are accountable for the product's quality, availability, and support.
- Documentation: Data products require comprehensive documentation covering schema definitions, business logic, known limitations, usage examples, and support contacts. Documentation should be living and version-controlled alongside the product itself.
- Service Level Agreements (SLAs): Data products must declare explicit guarantees about latency, freshness, availability, and quality. A real-time fraud detection stream might guarantee 99.9% availability with sub-second latency, while a daily marketing report might guarantee delivery by 6 AM with 99.5% completeness.
- Discoverability: Consumers should be able to find relevant data products through searchable catalogs with business-friendly terminology, not just technical identifiers.
Governance Dimensions
Comprehensive data product governance spans multiple dimensions:
Quality Governance
Quality governance establishes standards and monitors adherence to data quality requirements. This includes:
- Freshness SLAs: Maximum acceptable data age (e.g., "customer events processed within 2 minutes")
- Completeness guarantees: Expected volume ranges and missing data thresholds
- Accuracy contracts: Validation rules, acceptable error rates, and reconciliation processes
- Schema compliance: Enforcement of data contracts and compatibility rules
For deep dives into quality dimensions, see Data Quality Dimensions: Accuracy, Completeness, and Consistency. For contract implementation, refer to Data Contracts for Reliable Pipelines.
Access Governance
Access governance balances self-service enablement with necessary controls:
- Authentication and authorization: Who can discover, view, and consume each data product
- Privacy and compliance: PII handling, data residency, retention policies
- Self-service with guardrails: Enabling consumption without requiring central approvals while preventing misuse
- Audit trails: Tracking who accesses what data for compliance and security
Lineage Governance
Understanding data flow and transformations is critical for trust and debugging:
- Source tracking: Where does the data originate?
- Transformation documentation: What business logic has been applied?
- Dependency mapping: What downstream products or systems rely on this data?
- Impact analysis: What breaks if this product changes or becomes unavailable?
For detailed lineage tracking approaches, see Data Lineage Tracking: Data from Source to Consumption.
Lifecycle Governance
Data products evolve over time, requiring structured lifecycle management:
- Versioning strategies: Semantic versioning for schemas and contracts
- Deprecation policies: How long old versions are supported, migration paths
- Change notification: Alerting consumers to upcoming changes
- Sunset procedures: Safe decommissioning of retired products
Ownership Models
Successful data product governance distributes responsibility appropriately:
- Domain Teams own the data products generated within their business domain. The marketing team owns customer engagement metrics; the logistics team owns shipment tracking data. This domain ownership ensures those closest to the business context make decisions about data quality and evolution.
- Data Product Owners within each domain team serve as the primary point of contact. They define SLAs, approve schema changes, prioritize enhancements, and coordinate with consumers.
- Data Stewards provide governance oversight, ensuring consistency across products, maintaining the data catalog, and enforcing organizational policies without dictating domain-specific decisions.
- Platform Teams provide the infrastructure and tooling that makes governance scalable, data catalogs, quality monitoring, access controls, and lineage tracking.
Quality Contracts and SLAs
The most critical governance element is the explicit quality contract each data product commits to. For streaming data products, this typically includes:
- Freshness SLAs: "Order events appear in the stream within 30 seconds of transaction completion" creates a measurable commitment that can be monitored and alerted on.
- Completeness Guarantees: "During business hours, order volume should be 800-1200 events/minute; alerts trigger if outside this range" helps consumers trust the data or know when something is wrong.
- Accuracy Standards: "Product prices reconcile with the source system within $0.01" provides confidence in downstream analytics.
- Availability Commitments: "99.9% uptime during 6 AM - 11 PM EST" sets expectations for when the product can be reliably consumed.
These contracts should be codified, monitored automatically, and violations should trigger alerts to both owners and consumers. Modern governance platforms like Conduktor provide comprehensive policy enforcement, including data quality validation, schema governance, access controls, and SLA monitoring across Kafka topics (see Conduktor Governance Insights for real-time visibility into policy compliance). Conduktor Gateway (2025+), a Kafka proxy, enables advanced governance patterns like chaos testing, data masking, and topic-level policy enforcement without modifying application code.
Discoverability and Self-Service Access
A data product that can't be found can't be used. Effective discoverability requires:
- Business Glossaries: Mapping technical data product names to business terms ("order_events_v2" is "Real-time Order Stream")
- Rich Metadata: Schema documentation, sample queries, known use cases, performance characteristics, and contact information, all searchable and centralized
- Data Catalogs: Centralized registries where teams can browse available products, understand their purpose, and request access
- Usage Analytics: Showing which products are popular, who's using them, and for what purposes helps teams discover battle-tested products
Self-service access means consumers can start using a data product without lengthy approval processes, provided they have appropriate authorization and understand the quality contracts. Access requests should be automated, audit trails maintained, and onboarding documentation readily available.
Implementing Data Contracts with Modern Tools
- Data contracts formalize the agreement between data product producers and consumers. In 2025, several frameworks enable codified, testable contracts:
- Soda Core (2025) enables declarative data quality checks:
# Product: customer_orders_stream
# Contract: data-contract.yml
checks for orders:
- freshness(event_time) < 5m
- row_count between 100 and 5000
- missing_count(customer_id) = 0
- invalid_percent(order_total) < 0.1%
- schema:
fail:
when required column missing: [order_id, customer_id, order_total]
when wrong column typeGreat Expectations 1.x provides programmatic expectations:
# Data product contract validator
import great_expectations as gx
context = gx.get_context()
# Define expectations for customer_orders product
expectation_suite = context.add_expectation_suite("customer_orders_v2")
validator = context.get_validator(
batch_request=customer_orders_batch,
expectation_suite_name="customer_orders_v2"
)
# Freshness SLA
validator.expect_column_max_to_be_between(
column="event_timestamp",
min_value=datetime.now() - timedelta(minutes=5),
max_value=datetime.now()
)
# Completeness guarantee
validator.expect_column_values_to_not_be_null(column="customer_id")
# Schema enforcement
validator.expect_table_columns_to_match_ordered_list(
column_list=["order_id", "customer_id", "order_total", "event_timestamp"]
)
# Run validation
results = validator.validate()For comprehensive data quality frameworks, see Building a Data Quality Framework.
Policy-as-Code with OpenPolicyAgent (OPA) enables governance automation:
# Data product access policy
package data_product.access
default allow = false
# Allow access if user has required role and data classification matches
allow {
input.user.roles[_] == "data_analyst"
input.data_product.classification == "internal"
input.purpose in ["analytics", "reporting"]
}
# Sensitive data requires additional approval
allow {
input.user.roles[_] == "data_scientist"
input.data_product.classification == "sensitive"
input.approval.status == "approved"
time.now_ns() < input.approval.expires_at
}Modern data catalogs like OpenMetadata and DataHub (2025) provide centralized governance:
- Automated metadata extraction from streaming sources
- AI-powered business glossary mapping
- Lineage tracking with column-level granularity
- Embedded data quality monitoring
- Self-service access request workflows
For metadata strategies, see Metadata Management: Technical vs Business Metadata and What is a Data Catalog: Modern Data Discovery.
Lifecycle Management in Streaming Environments
Streaming data products present unique lifecycle challenges:
Schema Evolution: As business requirements change, schemas must evolve. Governance requires compatibility rules and version management:
- Forward compatibility: New schema can read old data (safe for consumers)
- Backward compatibility: Old schema can read new data (safe for producers)
- Full compatibility: Both forward and backward compatible (safest for all parties)
Breaking changes require coordinated migrations with sufficient notice to consumers. For detailed schema evolution strategies, see Schema Evolution Best Practices.
- Continuous Deployment: Unlike batch datasets with discrete versions, streaming products continuously produce data. Changes must be deployed without disruption, often requiring dual-write periods or feature flags.
- Deprecation Windows: When retiring a data product or version, provide sufficient migration time. A typical policy might be: 30 days notice for minor changes, 90 days for major changes, 6 months for deprecation.
- Migration Support: Provide migration guides, backward compatibility periods, and direct support to high-value consumers during transitions.
- Version Transparency: Consumers should always know which version they're consuming and when it will be deprecated. This metadata should be discoverable in the data catalog and potentially embedded in the data stream itself.
Measuring Data Product Health
Effective governance requires measuring both product health and governance adherence:
Product Health Metrics:
- SLA compliance rates (freshness, completeness, accuracy)
- Availability percentages
- Consumer count and growth trends
- Query/consumption volumes
- Support ticket volumes and resolution times
Governance Adherence Metrics:
- Percentage of products with complete documentation
- Percentage with active owners and up-to-date SLAs
- Time-to-discovery for new products
- Access request fulfillment time
- Schema change policy violations
Adoption Indicators:
- Number of unique consumers per product
- Diversity of use cases
- Reduction in duplicate data efforts
- Self-service access rate vs. manual requests
Teams should regularly review these metrics in data product reviews, celebrating successes and addressing problem areas. Products consistently failing SLAs or lacking consumers may need investment or retirement.
Connection to Data Mesh Principles
Data product governance operationalizes several data mesh principles:
- Domain Ownership aligns with domain-oriented decentralization, where teams own their data products rather than centralizing all data into a monolith.
- Data as a Product thinking requires governance frameworks that ensure products meet consumer needs with quality guarantees.
- Self-Service Data Infrastructure depends on governance providing the guardrails that make self-service safe and compliant.
- Federated Computational Governance balances centralized standards with domain autonomy, global policies enforced locally.
Even if you're not implementing a full data mesh architecture, these governance practices create more trustworthy, discoverable, and valuable data products in any distributed data environment. For comprehensive coverage of data mesh implementation, see Data Mesh Principles and Implementation.
Conclusion
Data product governance turns raw data streams into reliable, trustworthy assets. By establishing clear ownership, documenting quality contracts, enabling discoverability, and managing lifecycles thoughtfully, organizations can build data products that consumers trust and adopt widely.
Effective governance isn't about control — it's about enablement. It gives domain teams the structure to move quickly while keeping data products reliable, compliant, and valuable.
Related Concepts
- Data Governance Framework: Roles and Responsibilities - Organizational structures and roles that support effective data product governance
- Data Contracts for Reliable Pipelines - Formalized agreements that define quality guarantees and SLAs for data products
- Metadata Management: Technical vs Business Metadata - Understanding the different types of metadata critical for data product discoverability and governance