What is a Data Catalog? Modern Data Discovery
In today's data-driven organizations, data assets are scattered across databases, data lakes, cloud storage, and streaming platforms. Teams struggle to answer basic questions: What data do we have? Where is it? Can I trust it? Who owns it? This is where a data catalog becomes essential — a searchable inventory of all your organization's data assets. 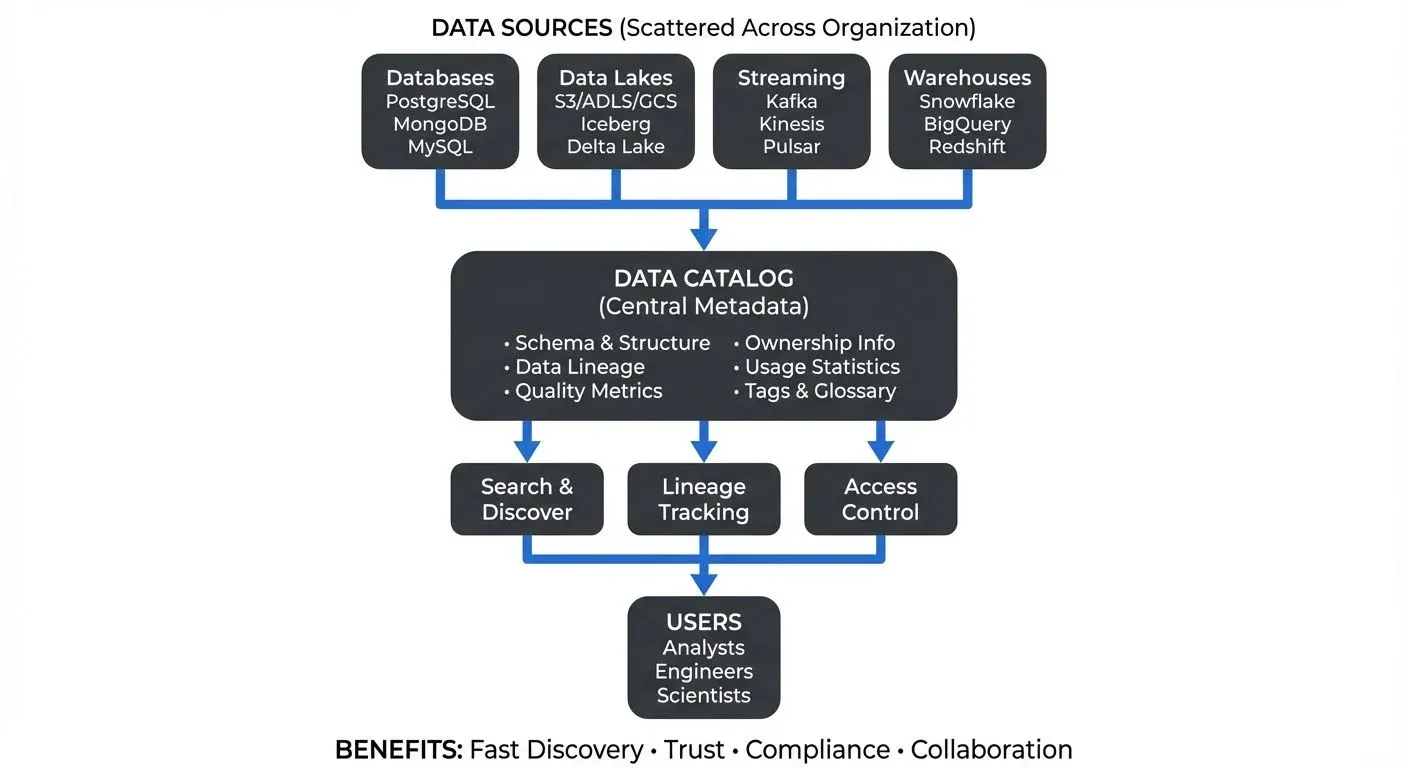
Understanding Data Catalogs
A data catalog is a centralized metadata repository that helps organizations discover, understand, and manage their data assets. Think of it like a library catalog, but instead of books, it indexes datasets, tables, streams, dashboards, and other data resources.
At its core, a data catalog collects and organizes metadata, the data about your data. This includes:
- Technical metadata: Schema definitions, data types, column names, file formats (e.g., "customer_id: BIGINT NOT NULL, email: VARCHAR(255), created_at: TIMESTAMP")
- Operational metadata: Data lineage, refresh schedules, data quality metrics, usage statistics (e.g., "Refreshed daily at 2 AM UTC, 99.8% completeness score, queried 847 times last month")
- Business metadata: Descriptions, glossary terms, data classifications, ownership information (e.g., "Contains PII, owned by Customer Analytics team, relates to 'Customer Lifetime Value' business metric")
For comprehensive coverage of metadata types and management strategies, see Metadata Management: Technical vs Business Metadata.
Unlike traditional data dictionaries that simply list tables and columns, modern data catalogs are intelligent systems that automatically discover data sources, track how data flows through your systems, and provide collaborative features for teams to share knowledge.
Why Data Discovery Matters
As organizations scale, data sprawl becomes inevitable. A typical enterprise might have hundreds of databases, thousands of tables, and millions of data assets distributed across on-premises systems, cloud platforms, and SaaS applications.
Without a data catalog, teams face several challenges:
- Wasted Time: Data analysts spend up to 80% of their time just finding and preparing data rather than analyzing it. They ping colleagues on Slack, dig through wikis, or reverse-engineer SQL queries to understand what data exists.
- Duplicate Efforts: Different teams often create redundant datasets because they don't know that another team has already solved the same problem. This wastes storage, compute resources, and engineering time.
- Compliance Risks: Data governance officers struggle to identify where sensitive data resides, making it difficult to comply with regulations like GDPR or CCPA. Without visibility, you can't protect what you can't find.
- Trust Issues: When data engineers can't trace where data comes from or how it's transformed, they lose confidence in analytics and reports. Bad decisions follow from untrusted data.
A data catalog solves these problems by making data discovery fast, reliable, and collaborative.
Key Features of Modern Data Catalogs
Automated Discovery and Scanning
Modern catalogs automatically connect to your data sources, databases, warehouses, lakes, and streaming platforms, to discover and index metadata. They scan schemas, sample data, and extract technical details without manual input.
Intelligent Search
Users can search for datasets using natural language, keywords, or filters. Advanced catalogs use machine learning to rank results by relevance, popularity, and data quality scores, helping users find the right data faster. For example, searching "customer churn" might return tables like customer_lifetime_value, subscription_cancellations, and user_activity_logs, ranked by usage frequency and quality scores.
Data Lineage
Lineage visualizations show how data flows from source systems through transformations to final consumption points. This helps teams understand dependencies, trace errors upstream, and assess the impact of changes before making them. For example, if a dashboard shows incorrect revenue figures, lineage traces the problem back through the flow: Revenue Dashboard → Aggregation Table → ETL Job → Raw Transactions Database, helping you pinpoint where the calculation went wrong. For detailed exploration of lineage concepts, see Data Lineage Tracking: Data from Source to Consumption.
Collaboration and Knowledge Sharing
Catalogs enable teams to document datasets with descriptions, add tags, rate data quality, and link to business glossary terms. Users can see who else is using a dataset, fostering collaboration and preventing duplicate work.
Data Governance and Access Control
Integration with access management systems lets governance officers see who has access to what data. Catalogs can classify data (e.g., PII, financial, public) and track compliance with data retention policies. For comprehensive governance strategies, see Data Governance Framework: Roles and Responsibilities and Building a Business Glossary for Data Governance.
Streaming Integration: Beyond Batch Data
Traditional data catalogs focused on static data sources like databases and files. However, modern architectures increasingly rely on streaming data from platforms like Apache Kafka, which powers real-time applications. For more on streaming fundamentals, see What is Real-Time Data Streaming.
Streaming introduces unique challenges for data discovery:
- Dynamic schemas: Stream topics may have evolving schemas that change over time, requiring version tracking
- Event-based metadata: Understanding message formats, event types, and payload structures across multiple schema formats (Avro, Protobuf, JSON Schema)
- Real-time lineage: Tracking how events flow through stream processors and downstream consumers using standards like OpenLineage
- Access patterns: Identifying which applications produce and consume specific topics, including consumer group tracking
- Async API documentation: Modern catalogs in 2025 increasingly support AsyncAPI specifications for documenting event-driven APIs, similar to how OpenAPI documents REST APIs
Modern data catalogs must extend beyond batch data to catalog streaming assets. This means discovering Kafka topics, capturing schema registry metadata (supporting Avro, Protobuf, and JSON Schema), and providing visibility into real-time data pipelines. For deeper coverage of schema management strategies, see Schema Registry and Schema Management.
In 2025, leading open-source catalogs like OpenMetadata and DataHub have added native support for Kafka topic discovery, schema evolution tracking, and consumer group monitoring. These tools integrate with OpenLineage to provide end-to-end visibility from streaming sources through transformations to final consumption.
For organizations using Kafka, tools like Conduktor provide specialized capabilities for managing and discovering streaming data. Conduktor helps teams visualize topic schemas, monitor consumer groups, and understand how data flows through Kafka clusters, bridging the gap between traditional data catalogs and streaming infrastructure. By integrating streaming metadata into your broader data discovery strategy, you ensure that both batch and real-time data assets are findable and understandable. For comprehensive Kafka coverage, see Apache Kafka.
Getting Started with a Data Catalog
Assess Your Data Landscape
Start by inventorying your critical data sources. Which databases, warehouses, and streaming platforms contain your most important data? Prioritize sources that are frequently accessed or contain sensitive information.
Choose the Right Tool
Evaluate data catalog solutions based on your needs. Consider factors like supported data sources (especially streaming platforms if relevant), automation capabilities, ease of use, and integration with your existing data stack. Open-source options like Apache Atlas, DataHub, OpenMetadata, and Amundsen provide strong foundations. For organizations using Kafka, Conduktor offers commercial capabilities that integrate data discovery with streaming platform management, providing unified visibility across both batch and real-time data assets.
Start Small, Iterate Often
Don't try to catalog everything at once. Begin with a pilot project focused on one department or use case. Automate metadata collection where possible, but invest time in adding business context, descriptions, ownership, and glossary terms, that makes datasets truly understandable.
Foster a Data Culture
Technology alone won't solve data discovery problems. Encourage teams to document their datasets, participate in data governance, and share knowledge through the catalog. Make the catalog part of everyday workflows by integrating it with tools teams already use.
Modern Data Discovery in 2025
Data catalogs have evolved from passive inventories to active intelligence layers. As of 2025, leading platforms provide:
- AI-powered insights: Tools like OpenMetadata use LLMs to automatically generate dataset descriptions, suggest business glossary terms, and detect quality anomalies. Some catalogs now offer conversational interfaces where users can ask "Show me all customer datasets updated in the last week" in natural language.
- Active metadata: Modern catalogs track real-time usage patterns to surface popular datasets, identify stale or unused data consuming storage costs, and recommend relevant datasets based on user roles and past queries. For insights on monitoring data freshness, see Data Freshness Monitoring & SLA Management.
- Data mesh integration: Catalogs now support federated architectures where domain teams own their data products while maintaining centralized discoverability. For more on data mesh patterns, see Data Mesh Principles and Implementation and Building and Managing Data Products.
- Observability integration: Leading catalogs integrate with data observability platforms to surface quality metrics, incident history, and reliability scores directly in search results. This helps users assess data trustworthiness before use. See What is Data Observability: The Five Pillars for comprehensive coverage.
As organizations embrace hybrid architectures combining batch, streaming, and real-time analytics, comprehensive data catalogs that span all modalities have become essential infrastructure rather than optional tooling.
Conclusion
A data catalog is no longer optional — it's essential infrastructure for modern data teams. By providing a single source of truth for data discovery, catalogs reduce time-to-insight, improve data quality, and enable better governance.
Whether you're a data analyst searching for customer segments, a governance officer ensuring compliance, or a data engineer building pipelines, a well-implemented data catalog helps you find, understand, and trust your organization's data assets, including the growing universe of streaming data that powers real-time applications.
Related Concepts
- Data Lineage: Tracking Data from Source to Consumption - Essential lineage capabilities that modern data catalogs provide for understanding data flow
- Metadata Management: Technical vs Business Metadata - Different types of metadata that catalogs collect and organize for effective data discovery
- Schema Registry and Schema Management - Schema registries complement data catalogs by providing technical schema metadata for streaming data assets
Sources and References
- DataHub Project Documentation. LinkedIn/DataHub Community. https://datahubproject.io/docs/ - Open-source data catalog platform documentation covering metadata management, discovery, and lineage tracking.
- Apache Atlas Documentation. Apache Software Foundation. https://atlas.apache.org/ - Reference architecture for data governance and metadata management across Hadoop and streaming ecosystems.
- Amundsen Documentation. Lyft/LF AI & Data Foundation. https://www.amundsen.io/amundsen/ - Open-source data discovery and metadata platform with focus on user experience and collaboration features.
- "The Enterprise Data Catalog: Improve Data Discovery, Ensure Data Governance, and Enable Innovation." O'Reilly Media, 2020. https://www.oreilly.com/library/view/the-enterprise-data/9781492054252/ - Comprehensive guide to data catalog implementation and governance strategies.
- Apache Kafka Schema Registry Documentation. Apache Software Foundation. https://kafka.apache.org/documentation/#schemaregistry - Official documentation on schema management and metadata integration for Kafka environments, essential for cataloging streaming data assets.
- OpenMetadata Documentation. OpenMetadata Contributors, 2025. https://docs.open-metadata.org/ - Modern open-source data catalog with AI-powered metadata generation, lineage tracking, and data quality integration.
- OpenLineage Specification. LF AI & Data Foundation, 2025. https://openlineage.io/ - Open standard for lineage metadata collection across batch and streaming data pipelines, enabling cross-platform lineage tracking.