Fine-Grained Access Control for Kafka
Kafka's native ACLs operate at the topic level: a principal can read or write an entire topic, or they cannot. But real-world security requirements rarely align with topic boundaries. A single topic might contain customer records where the analytics team should see purchase history but not payment card numbers, where EU analysts should access only EU customer data, and where PII fields must be masked for third-party integrations.
This is the gap between coarse-grained and fine-grained access control. Organizations discover that topic-level permissions are just the starting point. True fine-grained control means enforcing access at the record or field level — without duplicating data across dozens of filtered topics.
The Granularity Spectrum
Access control in streaming platforms operates across multiple levels, each with different implementation complexity and operational overhead.
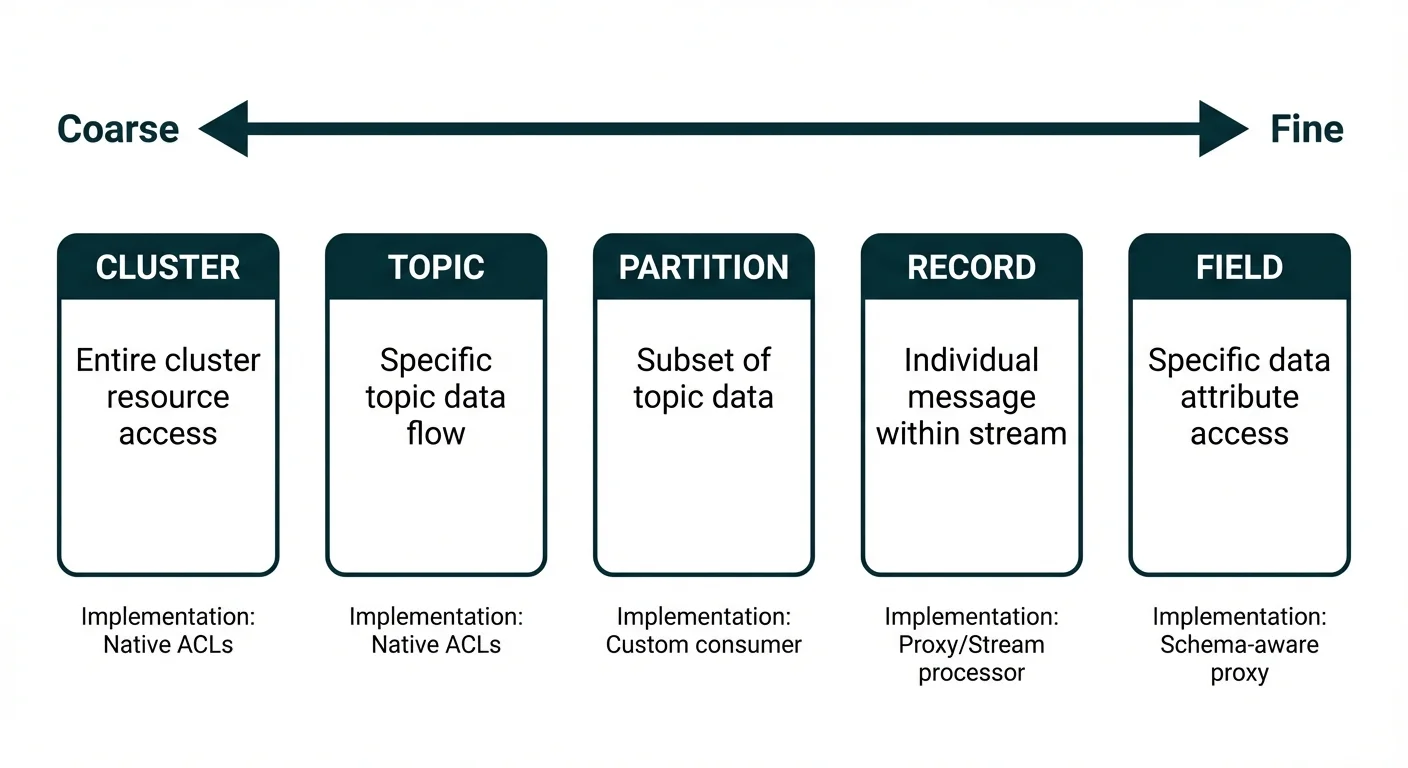
- Cluster level: Superusers with full administrative access. Binary: either you manage everything or nothing.
- Topic level: Standard Kafka ACLs. A principal can Read from
ordersor Write topayments. No visibility into what's inside the topic. - Partition level: Rarely used for security. Consumer groups can be assigned specific partitions, but this isn't access control: any consumer in the group can poll any partition.
- Record level: Filter records based on key, headers, or payload attributes. The analytics-eu consumer only receives records where
region=EU. Requires a filtering layer above Kafka. - Field level: The finest granularity. Mask credit card numbers, redact PII fields, or transform values based on the consumer's clearance. A single record might look different to different consumers.
Most organizations implement cluster and topic-level controls through native ACLs, then discover they need record or field-level filtering for compliance, multi-tenancy, or data sharing scenarios.
Why Topic-Level ACLs Aren't Enough
Three common scenarios expose the limitations of coarse-grained access:
- Mixed-sensitivity topics: A
customer-eventstopic contains registration, login, purchase, and support events. The analytics team needs purchase patterns but shouldn't access support tickets containing complaint details. Creating separate topics fragments the customer timeline and complicates event ordering. - Regulatory compliance: GDPR requires data minimization: consumers should receive only the data they need. A downstream system processing shipping labels doesn't need customer email addresses or phone numbers, even if it needs their shipping address from the same record.
- Multi-tenant analytics: A SaaS platform streams usage events from all tenants through a single topic. Each tenant's analytics dashboard should see only their own data, but replicating to per-tenant topics creates operational overhead proportional to tenant count.
Native Kafka ACLs cannot solve these problems. You either grant Read on the topic (exposing everything) or deny it (exposing nothing). The workarounds — creating filtered topic copies, client-side filtering, or trusting consumers to ignore unauthorized data — all have significant drawbacks.
Achieving Field-Level Access Control
Field-level access control requires intercepting data between Kafka and consumers, then transforming or filtering based on policy. Several approaches exist, each with different trade-offs.
Schema-Aware Filtering
When topics use Schema Registry (Avro, Protobuf, or JSON Schema), the schema defines which fields exist. A policy engine can reference schema field names to determine what to mask or remove:
# Policy: mask PII for analytics-consumer
policies:
- principal: "analytics-consumer"
topic: "customer-events"
fields:
- name: "email"
action: mask # alice@company.com → a***@c*****.com
- name: "phone"
action: redact # removed entirely
- name: "ssn"
action: deny # consumer cannot access records with this field populatedThe filtering layer deserializes records using the schema, applies field transformations, and re-serializes before delivering to consumers. This requires CPU overhead but preserves schema evolution:when new fields are added, policies can specify default actions.
Virtual Topics and Views
Rather than modifying data in-flight, virtual topics present a filtered view of an underlying physical topic. Consumers connect to customer-events-analytics which internally reads from customer-events and applies transformations.
This pattern mirrors database views. The underlying data remains unchanged, but different consumers see different projections. Virtual topics can also:
- Filter records by key pattern or header values
- Route subsets of data (EU records to one virtual topic, US to another)
- Apply rate limiting per virtual topic
Conduktor Gateway implements virtual topics through its Virtual Clusters and aliasing features, enabling field-level transformations without modifying producer or consumer code.
Proxy-Based Enforcement
A Kafka proxy sits between clients and brokers, inspecting every request and response. For Produce requests, it can reject messages containing unauthorized fields. For Fetch responses, it can filter or transform records before returning them to consumers.
Proxy architecture enables:
- Transparent enforcement: Consumers use standard Kafka clients. They don't know filtering is happening.
- Centralized policy: One policy engine governs all access, simplifying audit and compliance.
- Protocol-level control: Block specific API calls (like DescribeConfigs) for certain principals.
The trade-off is latency. Every message passes through an additional network hop and deserialization cycle. For high-throughput clusters (100K+ messages/second), proxy overhead must be carefully measured.
Context-Aware and Dynamic Policies
Static policies ("analytics-consumer can read customer-events with email masked") cover many use cases but miss context-dependent requirements.
- Time-based access: Production data access allowed only during business hours. On-call engineers can access sensitive topics outside hours.
- Purpose-based access: The ML training pipeline can access full customer records. The real-time dashboard sees only aggregates.
- Location-based access: EU-based consumers can access EU customer data. Cross-region access requires additional authorization.
These scenarios require evaluating attributes beyond principal identity. Open Policy Agent (OPA) and AWS Cedar provide policy languages for attribute-based decisions:
# OPA policy: time-based production access
package kafka.authz
import future.keywords.if
allow if {
input.topic == "production.orders"
input.operation == "Read"
is_business_hours
}
allow if {
input.topic == "production.orders"
input.operation == "Read"
input.principal.on_call == true
}
is_business_hours if {
hour := time.clock(time.now_ns())[0]
hour >= 9
hour < 18
}Dynamic policies require a policy engine evaluating each request. For Kafka, this means either a custom authorizer (for topic-level decisions) or a proxy layer (for record/field-level decisions).
Implementation Patterns for Kafka
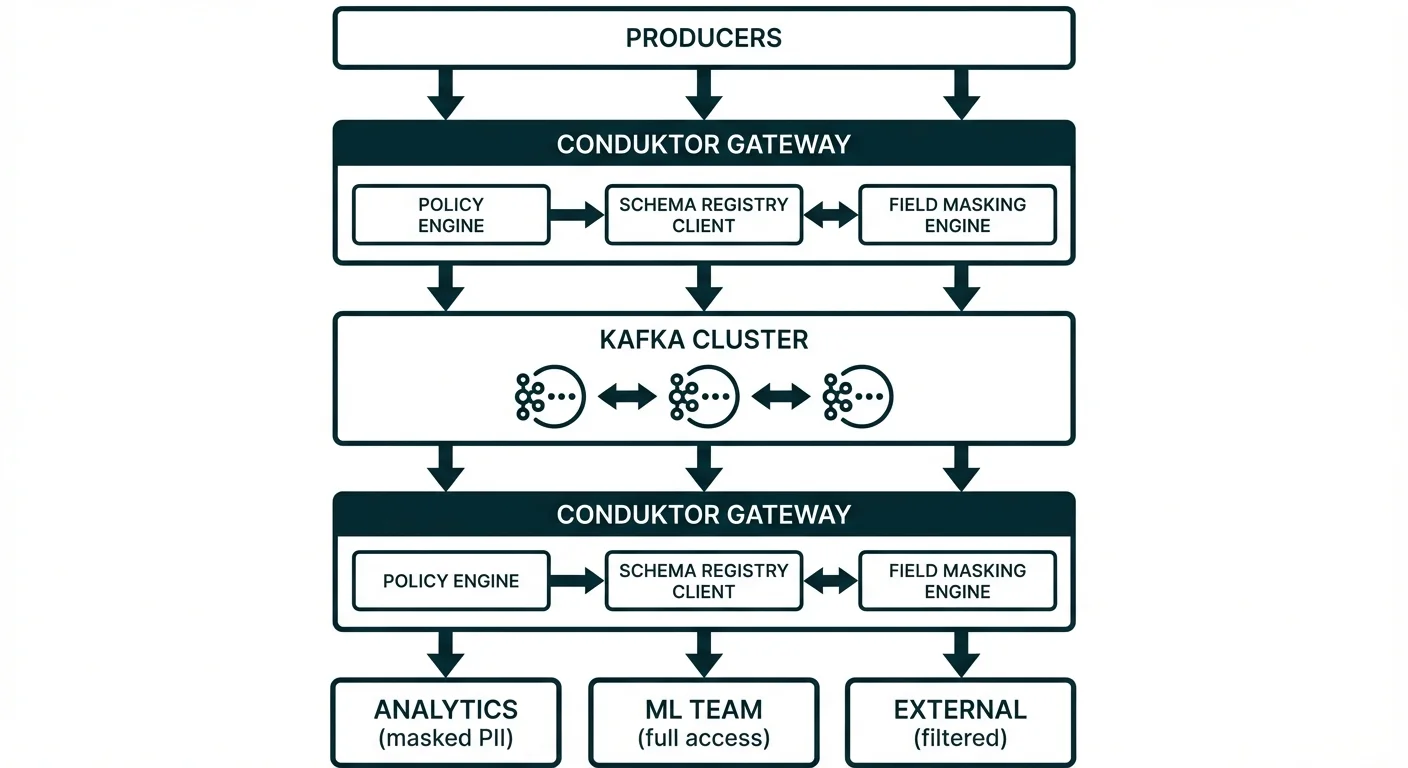
Pattern 1: Proxy with Field-Level Encryption and Masking
Conduktor Gateway provides multiple mechanisms for fine-grained data protection:
- Field-level encryption: Encrypt sensitive fields at produce time. Data is encrypted before reaching Kafka, so even brokers and administrators cannot read protected fields.
- Contextual decryption: Only virtual clusters with the DecryptPlugin configured receive decrypted values. Others see encrypted ciphertext. The same physical topic serves multiple consumers with different views based on which virtual cluster they connect through.
- Data masking: Transform field values (partial masking, redaction) based on policy. Unlike encryption, masking is lossy: the original value cannot be recovered.
# Encrypt PII fields on produce (scoped to passthrough vCluster)
pluginClass: io.conduktor.gateway.interceptor.EncryptPlugin
config:
recordValue:
fields:
- fieldName: email
keySecretId: vault-kms://vault:8200/transit/keys/pii-key
- fieldName: payment.cardNumber
keySecretId: vault-kms://vault:8200/transit/keys/payment-key
---
# Decrypt for ml-training vCluster only
pluginClass: io.conduktor.gateway.interceptor.DecryptPlugin
scope:
vCluster: ml-training
---
# Mask for analytics vCluster
pluginClass: io.conduktor.gateway.interceptor.FieldLevelDataMaskingPlugin
scope:
vCluster: analytics
config:
policies:
- name: mask-email
rule: { type: MASK_ALL }
fields: [email]
- name: mask-card
rule: { type: MASK_LAST_N, numberOfChars: 12 }
fields: [payment.cardNumber]Full configuration details: Conduktor Gateway Data Security Reference
This layered approach means:
- ML training pipelines (via
ml-trainingvCluster) receive fully decrypted data - Analytics consumers (via
analyticsvCluster) receive masked data - Other consumers see encrypted ciphertext (no decryption interceptor configured)
Pattern 2: Stream Processing Transformation
Use Kafka Streams or Flink to create filtered derivative topics:
// Kafka Streams: create analytics-safe topic
StreamsBuilder builder = new StreamsBuilder();
builder.stream("customer-events", Consumed.with(stringSerde, customerEventSerde))
.mapValues(event -> {
// Mask PII fields
event.setEmail(mask(event.getEmail()));
event.setPhone(null);
return event;
})
.to("customer-events-analytics", Produced.with(stringSerde, customerEventSerde));This creates a separate topic with transformed data. Advantages: no proxy overhead for reads. Disadvantages: data duplication, additional infrastructure, potential consistency issues between topics.
Pattern 3: Consumer-Side Filtering with Policy Enforcement
Trust consumers to enforce policies, but verify through audit logging and periodic compliance checks. This works for internal teams with strong governance but fails for external data sharing where you cannot trust the consumer.
Implement via Schema Registry validation: schemas include field-level annotations marking sensitivity, and consumers must demonstrate compliance through code review or automated scanning.
Operational Considerations
- Performance overhead: Field-level filtering requires deserializing every record. For JSON or Avro, this adds 0.1-1ms per record depending on schema complexity. At 100K records/second, a proxy-based approach needs significant CPU resources. Benchmark with production-representative loads before deploying.
- Audit requirements: Fine-grained access control is only valuable if you can prove it's working. Log every access decision, every transformation applied, and every policy change. Conduktor provides audit logging for tracking who accessed what data with which transformations.
- Policy drift: Policies written today may not match tomorrow's requirements. Schema evolution adds fields that policies don't cover. New consumer applications may not be assigned appropriate policies. Implement policy-as-code with version control and review processes.
- Testing access policies: How do you verify that analytics-consumer actually receives masked data? Build integration tests that consume as each principal and validate field values. Conduktor Gateway supports testing interceptors in isolation before deploying to production.
Summary
Fine-grained access control extends Kafka security beyond topic-level ACLs to record and field-level enforcement. While native Kafka cannot filter by field, proxy-based architectures enable schema-aware masking, virtual topics, and dynamic policy evaluation without modifying producers or consumers.
Organizations typically start with topic-level ACLs, then add fine-grained controls when compliance requirements, multi-tenancy, or data sharing scenarios demand more precision. The implementation choice — proxy, stream processing, or trusted consumers — depends on latency tolerance, operational complexity, and trust boundaries.
Conduktor Gateway provides a production-ready approach to fine-grained control through field-level encryption, contextual decryption, and data masking — serving multiple consumers with different data views from the same topics without data duplication.
Related Concepts
- Kafka ACLs and Authorization Patterns: Foundation for topic-level access control that fine-grained policies extend
- Data Access Control: RBAC and ABAC: Role and attribute-based models that inform fine-grained policy design
- Data Masking and Anonymization for Streaming: Techniques for protecting sensitive fields within records
Sources and References
- Apache Kafka Documentation - Authorization and ACLs - Native Kafka authorization model and its granularity limitations.
- NIST SP 800-162: Guide to Attribute Based Access Control - Framework for fine-grained, attribute-based authorization policies.
- Open Policy Agent - Kafka Authorization - Policy engine integration for dynamic access decisions.
- Conduktor Gateway Documentation - Proxy-based implementation of field-level access control and virtual clusters.
Written by Stéphane Derosiaux · Last updated May 12, 2026