Data Masking and Anonymization for Streaming
As organizations increasingly rely on real-time data pipelines to power applications, analytics, and machine learning, protecting sensitive information in streaming systems has become critical. Unlike batch processing where data can be transformed before storage, streaming data moves continuously through pipelines, requiring protection mechanisms that work at scale and in real time.
Data masking and anonymization are two complementary approaches to protecting sensitive information. They share the goal of preventing unauthorized access to personal or confidential data, but differ in purpose and technique. Knowing how to apply these methods in streaming architectures is important for compliance, security, and trust.
Understanding Masking and Anonymization
- Data masking replaces sensitive data with realistic but fictitious values, preserving the format and type of the original data. The goal is to create a version of the data that can be used for development, testing, or analytics without exposing actual sensitive information. Masked data is reversible in some implementations (like tokenization), allowing authorized systems to retrieve the original values when necessary.
- Anonymization goes further by removing or transforming data in a way that makes it impossible or extremely difficult to identify individuals. Anonymized data is typically irreversible and aims to meet strict privacy regulations like GDPR, which requires that personal data be processed in a way that prevents identification.
In streaming systems, both techniques must be applied while data is in motion, adding complexity around performance, consistency, and maintaining referential integrity across multiple data streams.
The Business Case for Data Protection in Streaming
Several factors drive the need for data protection in streaming architectures:
- Compliance requirements like GDPR, CCPA, and HIPAA mandate specific handling of personal data. GDPR Article 32 requires "pseudonymization and encryption of personal data," and violations can result in fines up to 4% of global revenue. Streaming systems that handle customer data, financial transactions, or health records must implement protection mechanisms to avoid legal and financial consequences. For comprehensive GDPR implementation guidance, see GDPR Compliance for Data Teams.
- Security and access control become more complex in streaming environments where data flows through multiple systems and teams. Development teams need realistic data for testing, analytics teams require access to aggregated insights, and production systems need full fidelity. Each use case requires different levels of data protection. For strategies on implementing role-based and attribute-based access controls, see Access Control for Streaming and Kafka ACLs and Authorization Patterns.
- Data sharing and partnerships often involve sending data to third parties or across organizational boundaries. Masking and anonymization enable safer data sharing by reducing the risk of exposing sensitive information while maintaining the utility of the data for its intended purpose.
The real-time nature of streaming systems means that protection mechanisms must be applied with minimal latency, making the choice of technique and implementation approach critical.
Data Masking Techniques for Streaming
Several masking techniques can be applied to streaming data, each with different characteristics:
- Static masking involves creating a masked copy of data before it enters the stream. This approach is simple and performant but doesn't handle new or updated records dynamically. It's best suited for datasets that change infrequently.
- Dynamic masking applies transformations in real-time as data flows through the pipeline. This ensures all data is protected regardless of when it enters the system. Common dynamic masking methods include:
- Substitution: Replacing real values with fake but realistic data (e.g., replacing "John Doe" with "Jane Smith")
- Shuffling: Randomly redistributing values within a column to break associations with other attributes
- Nulling or redaction: Removing sensitive fields entirely or replacing them with asterisks
- Encryption: Transforming data using cryptographic algorithms, making it unreadable without the decryption key. For end-to-end encryption strategies, see Encryption at Rest and in Transit for Kafka
- Format-preserving encryption (FPE) is particularly useful in streaming contexts because it maintains the data type and format. For example, a 16-digit credit card number remains a 16-digit number after encryption, ensuring downstream systems continue to function without modification.
- Tokenization replaces sensitive data with randomly generated tokens stored in a secure vault. The streaming system works with tokens while the actual values remain protected. This is reversible and maintains referential integrity across streams.
Here's an example of how customer data might be masked in a Kafka stream:
// Original message
{
"customerId": "CUST12345",
"email": "john.doe@example.com",
"ssn": "123-45-6789",
"purchaseAmount": 299.99,
"timestamp": "2025-03-15T10:30:00Z"
}
// Masked version for analytics team
{
"customerId": "CUST12345",
"email": "j***@example.com",
"ssn": "***-**-6789",
"purchaseAmount": 299.99,
"timestamp": "2025-03-15T10:30:00Z"
}The customerId is preserved for analytics, while email and SSN are partially masked, and the purchase amount remains unchanged for business analysis.
Anonymization Strategies for Streaming
Anonymization techniques aim to prevent re-identification while preserving data utility:
- Pseudonymization replaces identifying fields with pseudonyms. While technically reversible (unlike true anonymization), it provides strong protection when the mapping between pseudonyms and real identities is securely stored separately.
- Aggregation and generalization reduce precision to prevent identification. For streaming location data, instead of transmitting precise GPS coordinates (37.7749° N, 122.4194° W), the system might generalize to city level (San Francisco, CA) or zip code (94102).
- K-anonymity ensures that any individual's data cannot be distinguished from at least k-1 other individuals. In a stream processing context, this might involve buffering records and only releasing them once the anonymity threshold is met. For example, a Flink job could aggregate user events by generalizing age to ranges (20-30, 30-40) and locations to regions until each group contains at least 5 individuals.
- Differential privacy adds carefully calibrated noise to data to prevent identification while preserving statistical properties. This is particularly useful for real-time analytics streams where aggregate metrics (counts, averages) need to be computed without exposing individual records.
The challenge in streaming systems is applying these techniques while maintaining low latency and handling the continuous nature of the data.
Implementation in Streaming Platforms
Implementing data protection in streaming architectures requires deciding where to apply transformations in the pipeline:
- At the producer level: Applications can mask or anonymize data before publishing to Kafka topics. This ensures sensitive data never enters the streaming platform. However, it requires modifying every producer application and doesn't provide flexibility for different consumer needs.
- At the broker or platform level: Kafka brokers can be configured with stream processors that apply transformations. This centralizes the logic and doesn't require changing applications. Platforms like Confluent Schema Registry can enforce data contracts, and tools like Conduktor provide data masking capabilities at the platform level, allowing teams to define and enforce masking policies centrally without modifying individual applications.
- Within stream processors: Apache Flink, Kafka Streams, or ksqlDB can apply transformations as data flows through processing topologies. This approach offers flexibility to create multiple views of the same data for different purposes.
- At the consumer level: Consumers can apply transformations when reading data. This provides maximum flexibility but requires implementing protection logic in every consumer and doesn't prevent unauthorized consumers from accessing unprotected data.
A common pattern is to use topic-based access control combined with stream processors that publish different versions of data: 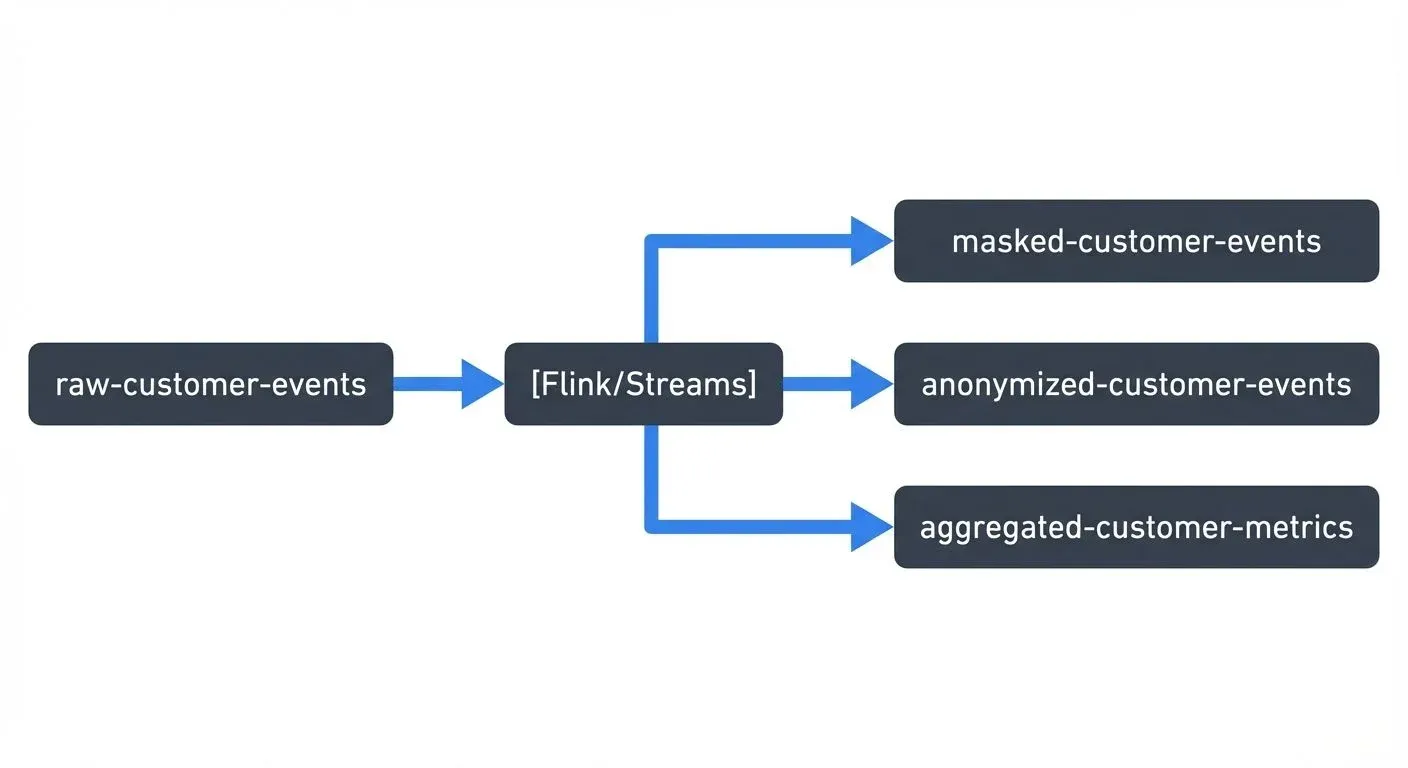
Production systems read from raw topics, analytics teams use masked versions, and public dashboards consume aggregated metrics.
Modern Tools and 2025 Capabilities
Several tools and platform capabilities have changed how teams approach data masking in 2025:
- Kafka 4.0+ with KRaft brings improved security foundations that enhance masking implementations. With ZooKeeper removed, the simplified architecture makes it easier to implement consistent security policies across the cluster. KRaft's metadata management provides better audit trails for tracking which transformations are applied to which topics. For comprehensive audit logging strategies, see Audit Logging for Streaming Platforms.
- Conduktor Gateway offers proxy-level data masking that sits between producers/consumers and Kafka brokers. This approach allows teams to define masking policies centrally without modifying application code. Gateway can apply different masking rules based on the consumer's identity, enabling a single topic to serve multiple teams with different data access levels. For example:
# Conduktor Gateway masking policy
interceptors:
- type: dataMasking
config:
rules:
- field: $.email
maskingType: EMAIL_DOMAIN
consumerGroup: analytics-team
- field: $.ssn
maskingType: HASH_SHA256
consumerGroup: ml-training
- field: $.creditCard
maskingType: REDACT
consumerGroup: support-teamApache Flink 1.18+ introduced enhanced Python APIs and improved state backends that make implementing custom masking functions more accessible. The new hybrid state backend optimizes performance for stateful masking operations like k-anonymity buffering:
# Flink 1.18+ Python API for masking
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.datastream.functions import MapFunction
class MaskSensitiveData(MapFunction):
def map(self, event):
event['email'] = self.mask_email(event['email'])
event['ssn'] = self.hash_ssn(event['ssn'])
return event
def mask_email(self, email):
username, domain = email.split('@')
return f"{username[0]}***@{domain}"
def hash_ssn(self, ssn):
import hashlib
return hashlib.sha256(ssn.encode()).hexdigest()[:16]
env = StreamExecutionEnvironment.get_execution_environment()
stream = env.from_source(kafka_source, watermark_strategy, "customer-events")
masked_stream = stream.map(MaskSensitiveData())Kafka Connect Single Message Transforms (SMTs) provide a lightweight approach for masking data in transit. The MaskField and ReplaceField transformations can be chained to protect sensitive data without writing custom code. For more details on SMT patterns, see Kafka Connect Single Message Transforms:
{
"name": "customer-events-connector",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSourceConnector",
"transforms": "maskEmail,hashSSN",
"transforms.maskEmail.type": "org.apache.kafka.connect.transforms.MaskField$Value",
"transforms.maskEmail.fields": "email",
"transforms.maskEmail.replacement": "***MASKED***",
"transforms.hashSSN.type": "org.apache.kafka.connect.transforms.HoistField$Value",
"transforms.hashSSN.field": "ssn"
}
}Kafka Streams with stateful masking enables more sophisticated anonymization patterns. The Processor API allows implementing k-anonymity by buffering records until the anonymity threshold is met:
// Kafka Streams k-anonymity processor (Kafka 3.6+)
public class KAnonymityProcessor implements Processor<String, CustomerEvent, String, CustomerEvent> {
private KeyValueStore<String, List<CustomerEvent>> buffer;
private final int k = 5;
@Override
public void process(Record<String, CustomerEvent> record) {
String generalizedKey = generalize(record.value());
List<CustomerEvent> group = buffer.get(generalizedKey);
if (group == null) group = new ArrayList<>();
group.add(record.value());
if (group.size() >= k) {
// Release anonymized group
group.forEach(event -> context().forward(
new Record<>(generalizedKey, anonymize(event), record.timestamp())
));
buffer.delete(generalizedKey);
} else {
buffer.put(generalizedKey, group);
}
}
}Schema Registry integration has improved with better support for tracking masked fields through schema metadata. Using Avro or Protobuf with Schema Registry allows teams to mark fields as sensitive and enforce masking at the serialization layer. For comprehensive schema management patterns, see Schema Registry and Schema Management.
For PII-specific handling patterns and detection techniques, see PII Detection and Handling in Event Streams.
Challenges and Trade-offs
Implementing data protection in streaming systems involves several challenges:
- Performance impact: Encryption, tokenization, and anonymization operations add processing overhead. Format-preserving encryption can be computationally expensive, and techniques like k-anonymity may require buffering data, increasing latency.
- Referential integrity: When the same entity appears in multiple streams (e.g., customer data in order events and support tickets), applying consistent masking is critical. A tokenization service must return the same token for the same input to maintain relationships across topics.
- Join operations: Anonymization that generalizes or adds noise can make joining streams difficult or impossible. If one stream generalizes age to ranges and another keeps exact ages, correlating records becomes problematic.
- Key handling: For techniques that use encryption or tokenization, securely managing and rotating keys in a distributed streaming environment requires careful architecture. Keys must be accessible to authorized processors while remaining protected from unauthorized access.
- Compliance complexity: Different regulations have different requirements. GDPR's "right to be forgotten" requires the ability to delete or anonymize specific individuals' data, which is challenging in append-only systems like Kafka where historical data is immutable. For strategies on enforcing data policies, see Policy Enforcement in Streaming.
- State management: Stream processors applying anonymization techniques like k-anonymity need to maintain state about which records have been processed and released, adding operational complexity.
Teams must balance protection requirements with performance, functionality, and operational overhead based on their specific compliance needs and use cases.
Summary
Data masking and anonymization protect sensitive information in streaming systems. Masking preserves data format while hiding actual values, making it suitable for non-production environments and analytics. Anonymization removes identifying information to prevent re-identification and meets stricter compliance requirements.
Streaming systems add complexity because data is in constant motion, performance is critical, and different consumers often need different levels of access. Implementation approaches range from producer-side transformation to platform-level enforcement to stream processor-based filtering, each with different trade-offs.
Key considerations: choosing the right technique (masking for flexibility vs. anonymization for compliance), deciding where in the pipeline to apply transformations (closer to producers for security, closer to consumers for flexibility), managing performance impact, and maintaining referential integrity across streams.
Related Concepts
- PII Detection and Handling in Event Streams - Detecting PII in streams before applying masking and anonymization techniques.
- GDPR Compliance for Data Teams - How masking and anonymization support GDPR requirements like pseudonymization and data minimization.
- Data Classification and Tagging Strategies - Classifying data sensitivity to determine appropriate masking and anonymization approaches.
Sources and References
- European Union General Data Protection Regulation (GDPR) - Official regulation text covering requirements for personal data protection, pseudonymization, and the right to erasure. Available at: https://gdpr-info.eu/
- Apache Kafka Security Documentation - Comprehensive guide to authentication, authorization, and encryption in Kafka. Available at: https://kafka.apache.org/documentation/#security
- NIST Special Publication 800-188: De-Identifying Government Datasets - Technical guidance on de-identification techniques, risk assessment, and best practices from the National Institute of Standards and Technology. Available at: https://csrc.nist.gov/publications/detail/sp/800-188/final
- Differential Privacy: A Survey of Results (Cynthia Dwork, 2008) - Foundational academic paper on differential privacy theory and applications in data release and analysis.
- Apache Flink Documentation - Official documentation for Apache Flink stream processing including state management and masking patterns. Available at: https://flink.apache.org/
- Conduktor Documentation - Platform guides for data masking, governance, and security in Kafka environments. Available at: https://docs.conduktor.io/
Written by Stéphane Derosiaux · Last updated April 29, 2026