How Conduktor Gateway Reduces Kafka DR from Hours to Minutes
Kafka disaster recovery fails not because of replication, but coordination. In the previous post, we broke down why updating dozens of services during an outage is the real bottleneck.
Here's what changes with Conduktor Gateway, a Kafka proxy, in front of Kafka:
| Phase | Without Conduktor Gateway | With Conduktor Gateway |
|---|---|---|
| Detection | 5-15 min | 5-15 min |
| Replication catch-up | 0-30 min | 0-30 min |
| Coordination | 10-30 min | ~0 (one team, one call) |
| Execution | 30-120 min | <1 min |
| Total | 45-195 min | 6-46 min |
Conduktor Gateway doesn't solve detection or replication. It eliminates coordination overhead and makes execution near-instant.
Now, the details.
Conduktor Gateway as a Kafka proxy
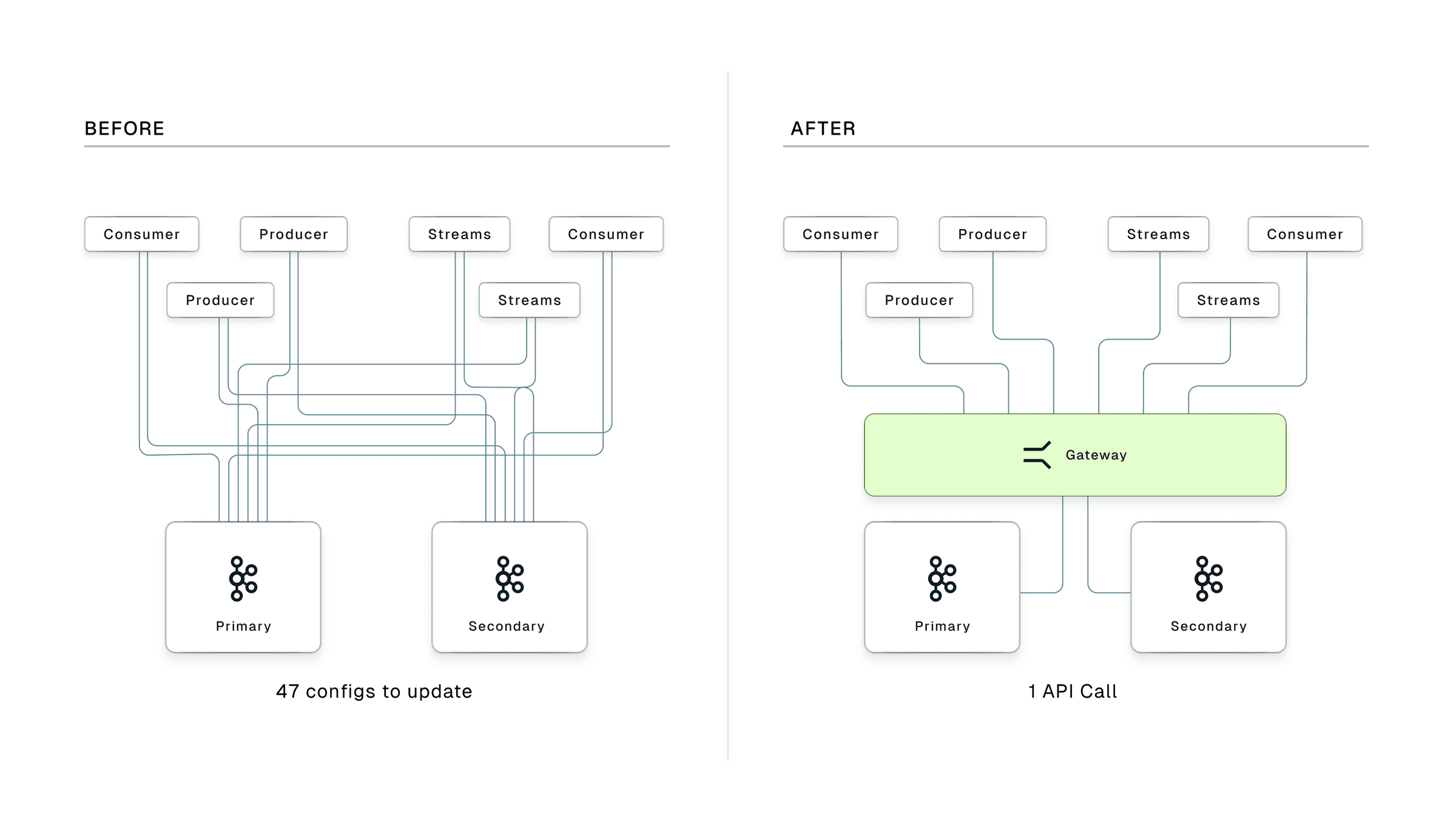
Your Kafka clients connect to Conduktor Gateway instead of connecting directly to Kafka brokers. Gateway speaks the Kafka protocol natively, so clients don't need any code changes or special SDKs.
Conduktor Gateway is configured with both your primary and secondary Kafka clusters. In normal operation, it routes all traffic to the primary. When you trigger a failover, it switches to the secondary.
config:
main:
bootstrap.servers: kafka-primary.example.com:9092
security.protocol: SASL_SSL
sasl.mechanism: PLAIN
sasl.jaas.config: org.apache.kafka.common.security.plain.PlainLoginModule required username="<primary-api-key>" password="<primary-api-secret>";
failover:
bootstrap.servers: kafka-secondary.example.com:9092
security.protocol: SASL_SSL
sasl.mechanism: PLAIN
sasl.jaas.config: org.apache.kafka.common.security.plain.PlainLoginModule required username="<secondary-api-key>" password="<secondary-api-secret>";
gateway.roles: failoverClients only know the Conduktor Gateway endpoint. They authenticate to Conduktor Gateway, not directly to Kafka. Conduktor Gateway handles credentials for both clusters independently: different API keys, different secrets, even different auth mechanisms if needed.
Single endpoint, one API call
Single endpoint for all clients. Instead of each service having its own bootstrap servers pointing to Kafka, they all point to Conduktor Gateway. When you need to switch clusters, you change one thing, not dozens.
Centralized switch via API. Triggering failover is one HTTP call:
curl -X POST 'http://gateway:8888/admin/pclusters/v1/pcluster/main/switch?to=failover' \
--user 'admin:conduktor'Forces client reconnection. After the switch, Conduktor Gateway closes all existing TCP connections. Clients detect the disconnect and reconnect. When they do, Conduktor Gateway routes them to the new cluster.
Works with any Kafka-compatible system. Conduktor Gateway speaks the Kafka protocol. It works with self-hosted Kafka, AWS MSK, Confluent Cloud, Aiven, Redpanda, WarpStream, and others.
No client code changes. Your applications connect to Conduktor Gateway like they would connect to any Kafka cluster. No special SDK.
What Conduktor Gateway doesn't do
Does not detect failures automatically. Conduktor Gateway doesn't monitor your Kafka cluster and trigger failover on its own. Someone (or something) has to call the API. If you want automatic failover, you need to build detection logic separately.
Does not replicate data. Conduktor Gateway routes traffic. It doesn't copy data between clusters. You still need MirrorMaker 2, Confluent Replicator, or Cluster Linking to replicate topics and consumer offsets.
Does not guarantee zero data loss. If your primary cluster dies with unreplicated data, that data is gone. Cross-cluster replication (MirrorMaker 2, Replicator, Cluster Linking) is asynchronous. Even Cluster Linking's "sync" mode has replication lag bounded by network latency, not zero. Near-synchronous configurations across distant datacenters reduce throughput significantly.
Does not eliminate RTO. You still need to detect the failure and decide to trigger failover. Conduktor Gateway reduces execution time to seconds, but detection and decision-making are on you.
Does not support per-topic failover (yet). Current cluster switching is all-or-nothing. If you have topics with different DR requirements (some critical, some not) you can't fail over selectively. This is a known gap. For now, if only some topics need DR replication, you'll pay the replication cost for all of them during failover, or accept that non-replicated topics lose data.
mTLS, in-flight requests, and client versions
mTLS
If your current setup uses mTLS with end-client identity, putting a proxy in front of Kafka seems to break your security model. The proxy terminates TLS, so how do you preserve client identity?
Conduktor Gateway supports mTLS on both sides:
- Client to Gateway: Clients authenticate with certificates. Conduktor Gateway extracts the principal from the certificate subject using SSL principal mapping, the same mechanism Kafka uses.
- Gateway to Kafka: Conduktor Gateway authenticates to the backing cluster with its own credentials (SASL, mTLS, or whatever your cluster requires).
Conduktor Gateway doesn't forward client credentials to Kafka. Instead, it manages two separate trust boundaries: clients trust Gateway, Gateway trusts Kafka. This actually simplifies credential management during failover. Clients don't need credentials for the secondary cluster, only Conduktor Gateway does.
If you need to preserve the original client identity for audit logging or ACL enforcement, Conduktor Gateway tracks the authenticated principal and can pass it through its interceptor chain.
In-flight requests
During the switch:
- Producers with requests in flight will get errors and retry (assuming
retries > 0, which is the default). Messages may be duplicated if the producer retries after the primary actually persisted but before acknowledging. - Consumers with uncommitted batches will re-fetch those messages from the secondary cluster. Design for at-least-once processing.
- Transactional producers (EOS) will have open transactions aborted. The transaction coordinator state doesn't transfer between clusters.
Recommendation: Use idempotent producers (enable.idempotence=true) and design consumers to handle duplicates.
Client versions
Kafka 3.8 introduced client-side rebootstrap (KIP-899). This matters for failover.
Before 3.8: Kafka clients "forget" their bootstrap servers after receiving initial metadata. If all known brokers become unreachable, the client is stuck. It won't retry the original bootstrap servers. You need to restart the client.
3.8 and later: Clients can fall back to bootstrap servers when all discovered brokers fail. Recovery is automatic.
| Scenario | Client < 3.8 | Client 3.8+ |
|---|---|---|
| Kafka down, Conduktor Gateway UP | ✅ Works (Gateway kicks + client retries) | ✅ Works |
| Kafka + Conduktor Gateway both down | ❌ Client restart required | ✅ Auto-reconnect when Gateway returns |
If you're still on Kafka clients < 3.8, consider upgrading. If you can't upgrade, ensure your Conduktor Gateway deployment is highly available.
Why not DNS or load balancers?
Doesn't this just move the problem?
Fair question. If Conduktor Gateway goes down, aren't you in the same situation?
The difference: Conduktor Gateway is stateless. It doesn't store data, just routes it. You can run multiple Conduktor Gateway instances behind a load balancer. If one dies, clients reconnect to another. No coordination needed.
Compare this to Kafka brokers, which are stateful and require partition reassignment and leader election when one fails.
Conduktor Gateway HA is a simpler problem than Kafka HA.
DNS and load balancer pitfalls
DNS and load balancers seem like obvious solutions. They're not. Here's why.
The DNS TTL trap
If your DNS has a 300-second TTL (5 minutes), clients continue resolving to the old gateways for 5 minutes after failover. During that window: timeouts, errors, lost messages.
But it's worse than TTL. The JVM caches DNS aggressively. The networkaddress.cache.ttl defaults to 30 seconds with a security manager, but infinite without one. Many Java services never re-resolve DNS without a restart. Your DNS change propagated globally, but your Java services are still talking to the dead cluster.
And existing TCP connections aren't affected by DNS changes at all. Changing DNS doesn't close open connections. Clients with established connections stay connected until something forces a disconnect.
Load balancer blind spots
A load balancer checking Conduktor Gateway health sees Conduktor Gateway as UP even when the backend Kafka is dead. The Conduktor Gateway HTTP health check returns 200. The LB keeps routing traffic. Your service is down, but your infrastructure thinks everything is fine.
The non-atomic failover window
Between the moment you:
- Call
/switchon all gateways - Update DNS/LB
- Wait for clients to re-resolve DNS
- Wait for clients to reconnect
You have a window where some clients are on primary, others on secondary. Producers writing to different clusters. Consumers with inconsistent offsets. Split-brain without calling it split-brain.
The dangerous assumptions
| Assumption | Reality |
|---|---|
| DNS propagates instantly | No. TTL + intermediate caches + client caching |
| LB can detect Kafka failure | No. It sees Gateway UP/DOWN, not Kafka |
| Clients respect DNS TTL | No. JVM caches aggressively |
| One team controls everything | No. DNS is infra, LB is ops, Conduktor Gateway is platform |
What Conduktor Gateway does differently
Conduktor Gateway forces client disconnection during cluster switching. All active TCP connections are closed. Clients are forced to reconnect, and when they do, they're routed to the new cluster.
This bypasses the DNS caching problem entirely. You don't wait for TTL. You don't hope clients re-resolve. You force the reconnection.
Client-side failover libraries: Some teams build custom wrappers, but they're inconsistent across languages and don't solve the coordination problem. You still need to configure every client with both clusters.
Native cloud solutions (MSK multi-region, Confluent geo-replication): These handle replication but still require client-side changes to switch clusters. The coordination problem remains.
Conduktor Gateway's value is the single control point. One switch instead of dozens. And forced reconnection instead of hoping DNS behaves.
Running a failover
Before and during failover
Data replication must be in place. Configure MirrorMaker 2, Confluent Replicator, or Cluster Linking between clusters. Enable consumer group offset synchronization (sync.group.offsets.enabled=true in MirrorMaker 2). Note: offset sync is checkpoint-based with a 60-second default interval. After failover, consumers may reprocess up to 60 seconds of messages.
Know your client topology. Understand which services produce to and consume from which topics. This lets you coordinate migration order and identify applications that need special handling.
Version requirements. Gateway 3.3.0+, Kafka 2.8.2+.
Client timeouts should be generous. Default delivery.timeout.ms is 2 minutes. If your team takes 10 minutes to detect and trigger failover, set it higher.
For planned failover (DR drills):
- Pause producers and wait for replication to catch up (check consumer lag on the replication consumer group)
- If using Cluster Linking, promote the mirror topics
- Call the switching API on your Conduktor Gateway instances
- Resume producers
For unplanned failover (primary is dead):
- Verify your secondary cluster is healthy
- Check replication lag (this is your data loss window)
- If using Cluster Linking, promote the mirror topics
- Call the switching API on your Conduktor Gateway instances
In disaster scenarios, there's no "migrate consumers first". The primary is already gone. Accept the replication lag as data loss and cut over.
For more details, see the Conduktor Gateway failover documentation.
Wrapping up
Conduktor Gateway doesn't make Kafka DR automatic. The hard parts are still hard: detecting failures, replicating data, deciding when to pull the trigger.
What Conduktor Gateway eliminates is the scramble. One endpoint. One switch. Clients reconnect on their own.
For the complete DR strategy this post fits into (six technical areas, chaos testing methodology, compliance mapping, and a step-by-step failover runbook), read Kafka Disaster Recovery Beyond Replication.
Ready to simplify your Kafka DR? Read the Conduktor Gateway failover documentation or book a demo to see it in action.