AI Discovery and Monitoring: Tracking AI Assets Across the Enterprise
In the rush to implement AI solutions, many organizations have created a sprawling landscape of models, pipelines, and data flows that operate in silos across departments and teams. A data science team might deploy a fraud detection model, marketing launches a recommendation engine, and operations builds a predictive maintenance system, all without centralized visibility or coordination.
This AI sprawl creates significant risks. Models trained on outdated data continue making predictions. Redundant systems waste compute resources. Compliance teams struggle to audit what AI is being used and how. Security vulnerabilities lurk in forgotten endpoints. The very innovations meant to drive business value become sources of operational debt and regulatory exposure.
AI discovery and monitoring address this by building systematic visibility into every AI asset across the enterprise. Discovery answers "what AI do we have?", while monitoring answers "how is it performing?" Together, they form the foundation of AI governance.
What is AI Discovery?
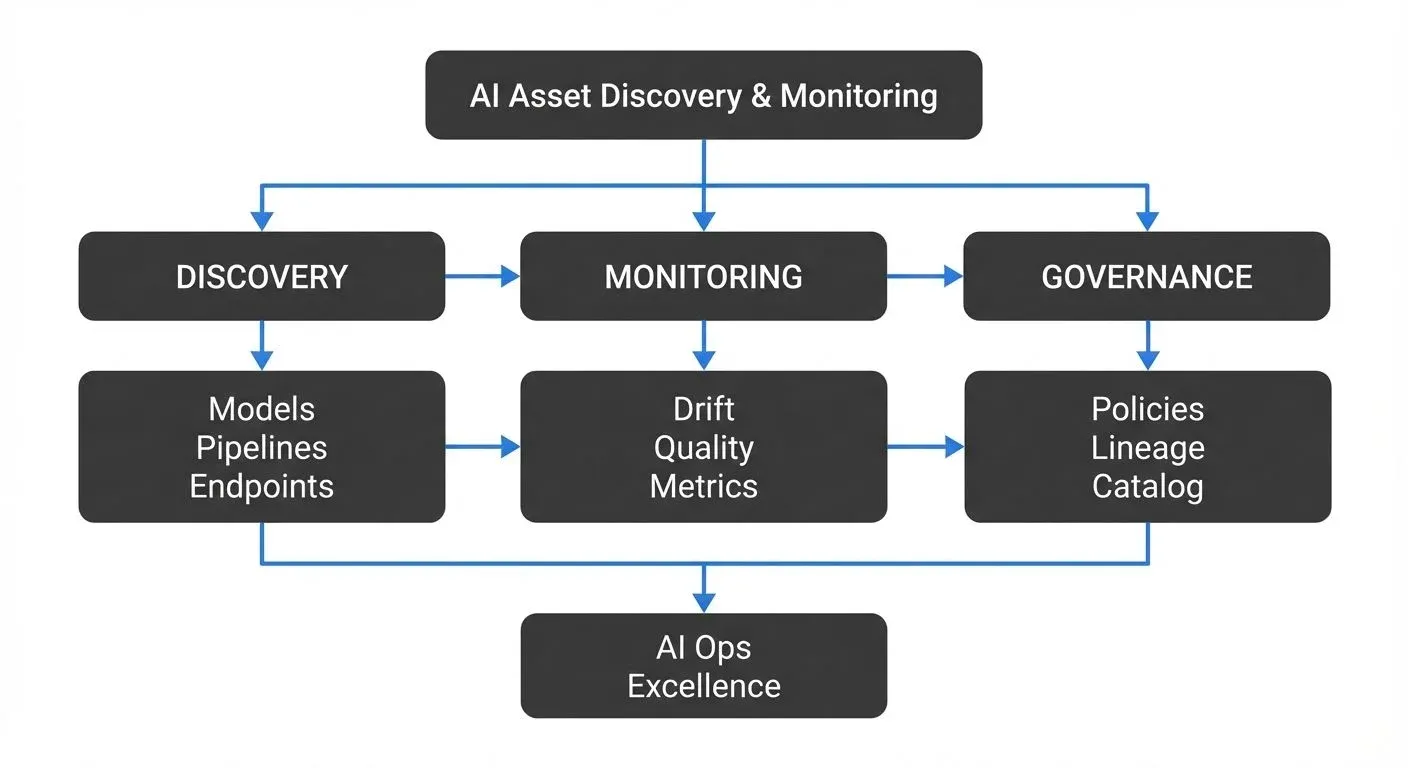
AI discovery is the process of identifying, cataloging, and maintaining an inventory of all AI-related assets within an organization. These assets span a diverse landscape:
- Models: Machine learning models in development, staging, and production environments (including traditional ML, deep learning, and foundation models)
- LLM Assets: Foundation models, fine-tuned variants, prompt templates, embeddings, vector databases, and retrieval systems for RAG (Retrieval-Augmented Generation) applications
- Training pipelines: Data processing workflows that prepare training datasets
- Feature pipelines: Systems that compute and serve features for real-time inference
- Endpoints: APIs and services that expose model predictions
- Training data: Datasets used to build and validate models
- Inference data: Real-time and batch data flowing through prediction systems
Discovery extends across the entire AI lifecycle, from experimental notebooks in data science workstations to production-grade services handling millions of requests. It's not a one-time activity but a continuous process that keeps pace with rapid development cycles and evolving infrastructure.
While discovery focuses on what exists, monitoring focuses on how it behaves. These practices are complementary: you can't effectively monitor what you haven't discovered, and discovery without monitoring leaves blind spots in operational performance.
Why AI Discovery Matters
The business case for AI discovery spans four critical dimensions:
- Compliance and Regulatory Requirements: Regulations like GDPR, CCPA, the EU AI Act (enforced 2025), and US AI Executive Order requirements mandate organizations document what personal data their AI systems process, maintain AI Bill of Materials (AIBOM) for model transparency, provide Model Cards detailing model characteristics and limitations, and demonstrate measures protecting against bias and discrimination. Without comprehensive discovery, compliance teams can't even identify which systems fall under regulatory scope, let alone audit them effectively.
- Risk Management and Security: Undocumented AI systems are security vulnerabilities waiting to be exploited. Shadow AI, models deployed by teams without IT oversight or central governance, may lack proper authentication, expose sensitive data, or make critical decisions without adequate testing. Discovery enables security teams to implement consistent policies, patch vulnerabilities, and ensure models meet organizational standards before reaching production.
- Cost Optimization: AI workloads consume significant compute resources. Discovery reveals redundant models solving the same problem, underutilized systems that could be decommissioned, and opportunities to consolidate infrastructure. Organizations routinely find 20-30% cost savings by identifying and eliminating AI waste after implementing comprehensive discovery.
- Technical Debt Reduction: Every organization has AI systems that outlived their usefulness but continue running because no one knows if they're still needed. Discovery provides the visibility to safely decommission obsolete models, reducing operational complexity and freeing teams to focus on high-value initiatives rather than maintaining legacy systems.
Building an AI Asset Inventory
A complete AI asset inventory is the single source of truth for your organization's AI landscape. The core components include:
- Models and Versions: Each model entry should capture the algorithm type, version history, training date, accuracy metrics, owner, and deployment status. Version control is critical, production systems may depend on specific model versions, and rollbacks require knowing exactly what was deployed when.
- Training Data Lineage: Document the datasets used to train each model, including data sources, transformation logic, and temporal snapshots. This enables reproducibility, helps diagnose performance issues, and supports compliance requirements around data usage and retention. For comprehensive lineage tracking practices, see Data Lineage Tracking: Data from Source to Consumption.
- Features and Engineering: Feature stores, centralized repositories where ML features are stored, managed, and served to models, are becoming central to modern ML architectures. Your inventory should track feature definitions, computation logic, dependencies, and which models consume which features. This prevents duplicate feature engineering and enables feature reuse across teams. For detailed coverage of feature store patterns, see Feature Stores for Machine Learning.
- Endpoints and APIs: Production models are typically accessed through APIs. Catalog each endpoint's URL, authentication method, rate limits, SLA commitments, and consuming applications. This mapping is essential for impact analysis when changes are planned.
- Model registries play a crucial role in maintaining this inventory. Tools like MLflow, Weights & Biases, and Neptune provide structured repositories where data scientists register models with standardized metadata. However, model registries alone aren't sufficient, they typically don't capture the broader context of data pipelines, feature engineering, and downstream consumers. Integration with data catalogs (like DataHub, Collibra, or Atlan) provides end-to-end visibility by connecting model metadata with the data assets they depend on and produce.
Here's an example of registering a model with MLflow during training, automatically capturing parameters, metrics, and custom metadata:
import mlflow
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
# Start MLflow run
with mlflow.start_run(run_name="fraud_detection_v1"):
# Train model
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# Log parameters
mlflow.log_params({
"n_estimators": 100,
"max_depth": 10,
"training_data_version": "2025-12-01"
})
# Log metrics
predictions = model.predict(X_test)
accuracy = accuracy_score(y_test, predictions)
mlflow.log_metric("accuracy", accuracy)
# Log model with metadata
mlflow.sklearn.log_model(
model,
"model",
registered_model_name="fraud_detection",
metadata={
"owner": "data-science-team",
"business_unit": "payments",
"compliance_reviewed": True,
"deployment_tier": "production"
}
)Discovery Methods and Techniques
Organizations employ multiple strategies to discover and catalog AI assets:
- Metadata Scanning: Automated tools scan infrastructure to identify AI workloads based on signatures like TensorFlow or PyTorch libraries, GPU usage patterns, or specific API frameworks. This passive approach catches systems that weren't formally registered but has limited insight into business context.
- API Monitoring: Network analysis tools observe API traffic to identify machine learning inference endpoints based on request patterns, response structures, and performance characteristics. This reveals shadow AI deployed without proper documentation but requires sophisticated pattern recognition to distinguish ML APIs from other services.
- Lineage Tracing: Following data flows backward from business applications reveals the models and pipelines that support them. Lineage tools track how data moves from sources through transformations to final consumption, mapping the complete chain from raw data to AI-driven decisions. This approach provides rich context but requires instrumentation of data pipelines.
- Declarative Registration: The most reliable approach is requiring teams to explicitly register AI assets in centralized systems, ideally integrated into CI/CD pipelines so registration happens automatically during deployment. This provides high-quality metadata but only works with organizational discipline and enforcement.
Most mature organizations combine these methods: automated discovery catches undocumented systems, while declarative registration ensures new systems are properly cataloged from the start.
Here's an example of automated discovery using metadata scanning. This script scans AWS SageMaker to find all deployed models and endpoints, automatically building an inventory:
import boto3
import json
def discover_sagemaker_models(region='us-east-1'):
"""
Scan AWS SageMaker to discover deployed models and endpoints
"""
sagemaker = boto3.client('sagemaker', region_name=region)
# Discover all endpoints
endpoints = sagemaker.list_endpoints()['Endpoints']
inventory = []
for endpoint in endpoints:
endpoint_name = endpoint['EndpointName']
# Get endpoint details
endpoint_config = sagemaker.describe_endpoint(
EndpointName=endpoint_name
)
# Get model details
model_name = endpoint_config['EndpointConfigName']
# Collect metadata
asset = {
'asset_id': endpoint_name,
'asset_type': 'ml_endpoint',
'status': endpoint_config['EndpointStatus'],
'creation_time': str(endpoint_config['CreationTime']),
'last_modified': str(endpoint_config['LastModifiedTime']),
'instance_type': endpoint_config['ProductionVariants'][0]['InstanceType'],
'model_name': model_name,
'region': region
}
# Extract tags for ownership and metadata
tags = sagemaker.list_tags(ResourceArn=endpoint_config['EndpointArn'])
asset['tags'] = {tag['Key']: tag['Value'] for tag in tags['Tags']}
inventory.append(asset)
return inventory
# Run discovery
discovered_assets = discover_sagemaker_models()
print(f"Discovered {len(discovered_assets)} ML endpoints")Monitoring Dimensions
Once AI assets are discovered, continuous monitoring tracks their health and performance across multiple dimensions:
- Performance Metrics: Track prediction latency, throughput, error rates, and resource utilization. Compare actual performance against SLA commitments. Set alerts for degradation that impacts user experience or breaches service agreements.
- Model Drift: Monitor statistical properties of input data and model predictions to detect drift, when the data distribution shifts from what the model was trained on, degrading accuracy. Drift detection is crucial because models don't explicitly fail; they just become gradually less effective, often invisibly to users. For in-depth coverage of drift patterns and mitigation strategies, see Model Drift in Streaming.
- Data Quality: Track completeness, validity, and freshness of features fed to models. Missing values, schema changes, or stale data can silently corrupt predictions. Quality monitoring catches these issues before they cascade into business impact. For understanding quality dimensions, see Data Quality Dimensions: Accuracy, Completeness, and Consistency.
- Usage Patterns: Understand who uses each model, how often, and for what purposes. Usage tracking identifies models ready for decommissioning (no users) or requiring scaling (growing demand). It also supports chargeback models where consumers pay for the AI services they use.
- Cost Tracking: Attribute infrastructure costs to specific models and teams. This enables ROI analysis (is this model worth what it costs?), budget accountability, and optimization efforts focused on the most expensive systems.
Modern observability platforms like Arize, Fiddler, and WhyLabs specialize in AI-specific monitoring, providing purpose-built capabilities for drift detection, explainability, and fairness metrics that general-purpose monitoring tools lack.
LLM-Specific Monitoring (2025+): For Large Language Model systems, additional monitoring dimensions include prompt effectiveness, token usage and costs, embedding quality, retrieval accuracy in RAG systems, context relevance, and hallucination detection. Tools like LangSmith, Weights & Biases Weave, and the open-source Evidently AI provide specialized observability for GenAI applications, tracking prompt-response patterns, semantic drift in embeddings, and retrieval performance in vector databases.
Here's an example of implementing drift detection. For production use, consider specialized libraries like Evidently AI or NannyML that provide comprehensive drift detection, but this example demonstrates the core concept:
import numpy as np
from scipy import stats
from datetime import datetime, timedelta
class DriftDetector:
"""
Monitor model input distributions for drift using statistical tests
"""
def __init__(self, reference_data, threshold=0.05):
self.reference_data = reference_data
self.threshold = threshold
self.drift_history = []
def detect_drift(self, current_data, feature_name):
"""
Use Kolmogorov-Smirnov test to detect distribution drift
"""
# Perform KS test
statistic, p_value = stats.ks_2samp(
self.reference_data[feature_name],
current_data[feature_name]
)
drift_detected = p_value < self.threshold
result = {
'timestamp': datetime.now(),
'feature': feature_name,
'statistic': statistic,
'p_value': p_value,
'drift_detected': drift_detected,
'severity': 'high' if p_value < 0.01 else 'medium' if p_value < self.threshold else 'none'
}
self.drift_history.append(result)
if drift_detected:
print(f"⚠️ Drift detected in {feature_name}: p-value={p_value:.4f}")
return result
def monitor_all_features(self, current_data):
"""
Monitor all numeric features for drift
"""
results = {}
for feature in self.reference_data.select_dtypes(include=[np.number]).columns:
results[feature] = self.detect_drift(current_data, feature)
return results
# Usage example
detector = DriftDetector(reference_data=training_data)
drift_results = detector.monitor_all_features(current_production_data)Streaming-Specific Challenges
AI systems built on streaming architectures present unique discovery and monitoring challenges:
- Real-time Model Serving: Models that process event streams (fraud detection on payment events, personalization on clickstreams) operate in a fundamentally different paradigm than batch systems. Discovery must track event schemas, topic subscriptions, and the temporal dependencies between events and predictions. For building end-to-end streaming ML systems, see Real-Time ML Pipelines.
- Feature Pipelines: Real-time feature engineering often involves complex streaming aggregations, windowed calculations, joins across multiple event streams, and stateful transformations. These pipelines are difficult to discover because the logic is distributed across stream processors, and the lineage is implicit in event flows rather than explicit in code.
- Event-Driven Architectures: In platforms like Kafka, models consume events from topics and produce predictions to other topics, creating intricate graphs of dependencies. Discovery requires understanding these topic-level relationships and tracing data lineage through asynchronous event flows. For Kafka infrastructure monitoring, see Kafka Cluster Monitoring and Metrics.
Governance platforms provide streaming-native capabilities to address these challenges, enabling teams to discover data products flowing through Kafka, enforce quality policies on event streams, and maintain visibility into the complex topologies that connect producers, stream processors, and consumers, including AI models and feature pipelines. This streaming-focused approach complements traditional model registries by capturing the real-time data context that batch-oriented tools miss.
Here's an example of monitoring a real-time ML model consuming from Kafka. This example works with Kafka 4.0+ running in KRaft mode (the modern architecture that replaced ZooKeeper in 2025):
from kafka import KafkaConsumer, KafkaProducer
import json
import time
from datetime import datetime
class StreamingModelMonitor:
"""
Monitor real-time ML model performance in streaming environment
"""
def __init__(self, model, input_topic, output_topic):
self.model = model
self.consumer = KafkaConsumer(
input_topic,
bootstrap_servers=['localhost:9092'],
value_deserializer=lambda m: json.loads(m.decode('utf-8'))
)
self.producer = KafkaProducer(
bootstrap_servers=['localhost:9092'],
value_serializer=lambda v: json.dumps(v).encode('utf-8')
)
self.output_topic = output_topic
self.metrics = {
'predictions_count': 0,
'total_latency': 0,
'error_count': 0
}
def process_stream(self):
"""
Consume events, make predictions, monitor performance
"""
for message in self.consumer:
start_time = time.time()
try:
# Extract features from event
event = message.value
features = self.extract_features(event)
# Make prediction
prediction = self.model.predict([features])[0]
# Calculate latency
latency_ms = (time.time() - start_time) * 1000
# Update metrics
self.metrics['predictions_count'] += 1
self.metrics['total_latency'] += latency_ms
# Publish prediction with metadata
result = {
'event_id': event.get('id'),
'prediction': float(prediction),
'timestamp': datetime.now().isoformat(),
'latency_ms': latency_ms,
'model_version': '1.2.0'
}
self.producer.send(self.output_topic, result)
# Alert on high latency
if latency_ms > 100:
print(f"High latency warning: {latency_ms:.2f}ms")
except Exception as e:
self.metrics['error_count'] += 1
print(f"Prediction error: {e}")
# Periodic metrics reporting
if self.metrics['predictions_count'] % 1000 == 0:
self.report_metrics()
def extract_features(self, event):
"""Extract feature vector from Kafka event"""
return [event.get('feature1'), event.get('feature2'), event.get('feature3')]
def report_metrics(self):
"""Report aggregated metrics"""
avg_latency = self.metrics['total_latency'] / self.metrics['predictions_count']
error_rate = self.metrics['error_count'] / self.metrics['predictions_count']
print(f"Metrics - Count: {self.metrics['predictions_count']}, "
f"Avg Latency: {avg_latency:.2f}ms, Error Rate: {error_rate:.2%}")Governance Workflows
Discovery and monitoring enable proactive governance workflows throughout the AI lifecycle:
- Approval and Certification: Before deployment, new models pass through review gates where architecture boards assess risk, security teams verify data protection, and compliance teams confirm regulatory alignment. Discovery systems integrate with these workflows, preventing uncertified models from reaching production.
- Lifecycle Management: Formal processes govern model transitions between development, staging, and production environments. Each transition triggers validation checks, documentation requirements, and stakeholder notifications tracked in the inventory system.
- Retirement and Deprecation: When models become obsolete, governance workflows ensure safe decommissioning. The inventory reveals all downstream consumers, enabling impact analysis and migration planning. Formal sunset processes notify stakeholders, archive artifacts for compliance, and prevent accidental re-deployment.
- Audit Trails: Every change to model configuration, training data, or deployment status is logged with timestamps and responsible parties. These audit trails support compliance reporting, incident investigations, and continuous improvement of AI operations.
Mature organizations encode these workflows in their discovery and monitoring platforms, automating routine checks and providing clear handoffs between teams. For broader governance practices, see Data Governance Framework: Roles and Responsibilities.
Building an AI Operations Center
Leading organizations are establishing centralized AI Operations Centers that consolidate visibility and coordination:
- Centralized Dashboards: Executive dashboards provide at-a-glance views of the entire AI estate, how many models in production, performance trends, cost trajectories, and compliance posture. These visualizations make AI operations tangible to leadership and enable data-driven investment decisions.
- Integration with MLOps and DataOps: AI operations don't exist in isolation. The operations center integrates model lifecycle management (MLOps) with data pipeline orchestration (DataOps), providing unified visibility into the dependencies between data and models. This integration enables end-to-end impact analysis: "if we change this dataset, which models are affected?"
- Team Collaboration: The operations center is a collaboration hub where data scientists, ML engineers, data engineers, and platform teams coordinate. Shared visibility into the AI landscape reduces duplicate work, enables knowledge sharing, and clarifies ownership boundaries.
- Incident Response: When models degrade or fail, the operations center provides the context for rapid troubleshooting, recent changes, dependency mapping, historical performance baselines, and contact information for responsible teams. This dramatically reduces mean time to resolution.
Building an operations center is as much organizational as technical. It requires executive sponsorship, cross-functional collaboration, and cultural acceptance that AI governance enables rather than inhibits innovation.
Summary
AI discovery and monitoring are not compliance burdens — they're operational necessities. Organizations with visibility into their AI assets can move faster and scale more reliably than those operating without it.
The path to mature AI operations begins with discovery: cataloging what exists, understanding dependencies, and establishing baseline monitoring. From there, teams build governance workflows, optimize resource allocation, and create the transparency that regulators and business stakeholders need.
As AI becomes standard infrastructure, discovery and monitoring will integrate with broader observability, security, and governance platforms rather than existing as separate disciplines.
Related Concepts
- Data Governance Framework: Roles and Responsibilities - Establish governance for AI assets
- Streaming Data Pipeline - Monitor pipelines feeding AI models
- Schema Registry and Schema Management - Track schemas for AI data flows
Sources and References
- MLflow Documentation - MLflow Model Registry and Tracking: https://mlflow.org/docs/latest/model-registry.html - Comprehensive guide to model versioning, lifecycle management, and metadata tracking.
- Google Cloud - Best Practices for ML Engineering: https://cloud.google.com/architecture/mlops-continuous-delivery-and-automation-pipelines-in-machine-learning - Industry best practices for MLOps, including model monitoring and governance frameworks.
- Arize AI - ML Observability Guide: https://arize.com/blog/ml-observability/ - Detailed overview of model monitoring, drift detection, and observability patterns for production ML systems.
- AWS - Machine Learning Governance: https://docs.aws.amazon.com/sagemaker/latest/dg/governance.html - Practices for governing ML workflows, including model discovery, lineage tracking, and compliance.
- DataHub Project - Metadata Architecture: https://datahubproject.io/docs/metadata-model/ - Open-source framework for building comprehensive data and ML asset catalogs with lineage tracking.
Written by Stéphane Derosiaux · Last updated April 29, 2026