Model Drift in Streaming: When ML Models Degrade in Real-Time
Machine learning models powering real-time applications face a unique challenge: the world they model never stops changing. A fraud detection model trained on last quarter's patterns may miss today's attack vectors. A recommendation engine optimized for pre-holiday shopping behavior struggles when consumer preferences shift. This phenomenon, model drift, is the silent degradation of ML performance over time.
In streaming architectures, where models consume continuously flowing data and make split-second predictions, drift isn't just a concern, it's inevitable. The question isn't whether your models will drift, but when, how fast, and whether you'll detect it before it impacts your business. 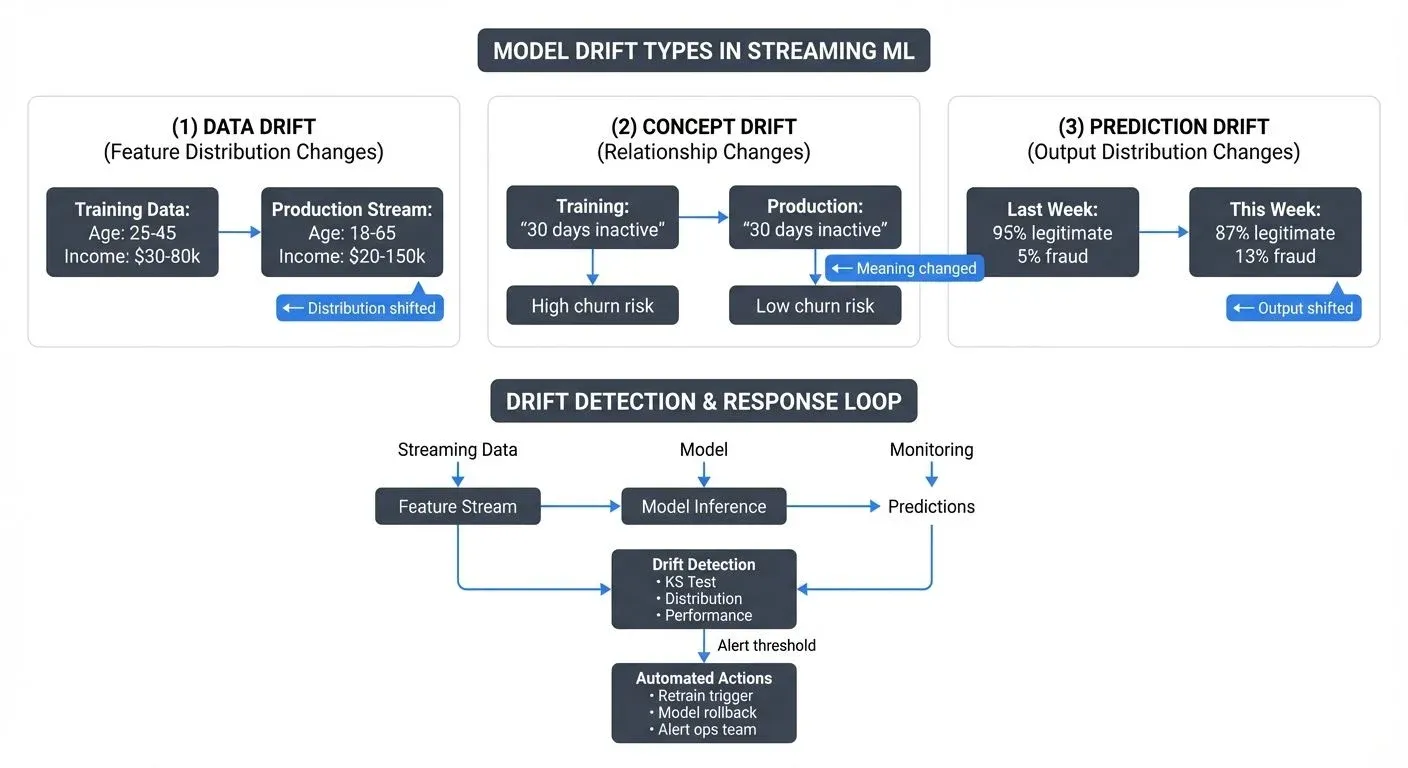
Understanding the Types of Model Drift
Model drift manifests in three distinct but often overlapping forms, each with different root causes and detection strategies.
- Data drift occurs when the statistical properties of input features change. Your fraud model was trained on transactions averaging $50, but suddenly sees a stream dominated by high-value purchases. The distribution has shifted, even though the underlying relationship between features and fraud hasn't changed. In streaming systems, data drift can emerge from upstream schema changes, new data sources joining a stream, or gradual shifts in user behavior. For deeper coverage of data drift detection and monitoring strategies, see Data Drift in Streaming.
- Concept drift represents a more fundamental problem: the relationship between features and outcomes has changed. A customer churn model learned that "30-day inactivity" strongly predicts cancellation, but after a product redesign, engaged users now check in less frequently. The features are the same, but their meaning has evolved. Streaming amplifies this challenge because business logic, user interfaces, and operational processes continuously evolve, often without triggering model retraining.
- Prediction drift focuses on the model's output distribution. Even when inputs seem stable, the predictions themselves may shift, 95% of transactions were classified as legitimate last week, but this week it's 87%. This can signal either data drift, concept drift, or emerging model issues, making it a valuable early warning signal in production systems.
Why Streaming Amplifies Model Drift
Batch ML pipelines retrain on a schedule, weekly, monthly, or when performance degrades beyond a threshold. Streaming models don't have this luxury. They operate in continuous time, consuming events as they arrive, with no natural breakpoint for evaluation and retraining.
Several streaming-specific factors accelerate drift:
- Continuous feature updates mean your model sees the latest data immediately. A recommendation model using "trending_topics" as a feature will reflect breaking news within minutes, potentially destabilizing predictions if those topics fall outside the training distribution.
- Upstream schema evolution is constant in event-driven architectures. When a producer adds a new field, changes an enum value, or subtly alters a timestamp format, downstream models may receive unexpected inputs. Without governance, these changes propagate silently through topics until they surface as prediction anomalies.
- Seasonal and temporal patterns create cyclical drift. An e-commerce model trained in January will underperform during Black Friday surges unless explicitly designed for seasonality. Streaming's real-time nature means you encounter these patterns as they happen, with no buffering period to prepare.
- Business logic changes deploy faster than model updates. A product team launches a new feature, marketing runs a campaign, or pricing strategy shifts, all generating event patterns the model has never seen. The model keeps predicting with outdated assumptions while the business has moved on.
Detection Strategies: Catching Drift Early
Effective drift detection in streaming requires continuous monitoring, not periodic batch analysis. Several statistical and operational approaches provide early warning signals.
- Statistical hypothesis testing compares current data distributions against a reference window from training. The Kolmogorov-Smirnov (KS) test, a non-parametric test measuring the maximum difference between cumulative distributions, detects changes in continuous feature distributions, while chi-square tests catch shifts in categorical features. In a streaming context, these tests run on sliding windows, comparing the last hour's events against baseline statistics. When divergence exceeds a threshold, alerts fire.
- Prediction monitoring tracks the distribution and confidence of model outputs. A sudden shift in the proportion of positive classifications, a narrowing of confidence scores, or an increase in predictions near decision boundaries all signal potential drift. For models with ground truth labels (the actual correct outcomes, as opposed to model predictions) available after a delay (like fraud detection confirmed after manual investigation), tracking prediction accuracy over time provides direct drift measurement.
- Feature drift detection monitors individual input features for distribution shifts. In streaming, this means maintaining summary statistics (mean, variance, percentiles) for each feature and comparing recent windows against training baselines. Advanced approaches use embeddings or dimensionality reduction to detect drift in high-dimensional feature spaces.
- Performance degradation monitoring remains the ultimate drift indicator. If your model has access to labels (even delayed), tracking precision, recall, F1, or AUC over time reveals when predictions degrade. The challenge in streaming is the label delay, fraud labels may arrive days after predictions, creating a detection lag.
- Modern drift detection tooling (2025) has matured significantly for streaming ML:
- Evidently AI provides open-source drift detection with pre-built tests for data drift, concept drift, and prediction drift. It integrates with streaming platforms to generate real-time reports comparing current data windows against reference datasets.
- WhyLabs/whylogs offers lightweight data logging that profiles ML inputs and outputs at scale. Its statistical profiles enable drift detection without storing raw data, making it ideal for privacy-sensitive streaming applications.
- NannyML specializes in performance estimation without ground truth labels, critical for streaming scenarios where labels arrive with significant delay. It estimates model performance metrics in real-time using confidence-based estimation.
- Alibi Detect (from Seldon) provides algorithms specifically designed for online drift detection in streaming environments, including outlier detection and adversarial detection for ML security.
These tools integrate with streaming platforms like Apache Kafka and Apache Flink to provide continuous drift monitoring without disrupting production inference pipelines.
Example: Real-time drift detection with Evidently AI and Kafka
Here's a practical example of monitoring data drift in a streaming ML pipeline:
from evidently.test_suite import TestSuite
from evidently.tests import TestColumnDrift, TestShareOfDriftedColumns
from kafka import KafkaConsumer
import pandas as pd
import json
# Reference data from training period
reference_data = pd.read_parquet('training_data.parquet')
# Initialize Kafka consumer for model input stream
consumer = KafkaConsumer(
'ml-model-inputs',
bootstrap_servers=['localhost:9092'],
value_deserializer=lambda m: json.loads(m.decode('utf-8'))
)
# Configure drift detection suite
drift_suite = TestSuite(tests=[
TestColumnDrift(column_name='transaction_amount'),
TestColumnDrift(column_name='user_age'),
TestShareOfDriftedColumns(threshold=0.3) # Alert if >30% of features drift
])
# Sliding window for current data
current_window = []
window_size = 1000
for message in consumer:
current_window.append(message.value)
# Run drift detection every 1000 events
if len(current_window) >= window_size:
current_data = pd.DataFrame(current_window)
# Compare current window to reference
drift_suite.run(reference_data=reference_data, current_data=current_data)
results = drift_suite.as_dict()
# Check for drift
if not results['summary']['all_passed']:
# Publish drift alert to monitoring topic
alert = {
'timestamp': message.timestamp,
'drifted_columns': [test['column_name']
for test in results['tests']
if test['status'] == 'FAIL'],
'severity': 'high' if results['summary']['failed_count'] > 2 else 'medium'
}
print(f"DRIFT DETECTED: {alert}")
# Trigger retraining pipeline or send alert
# Slide the window
current_window = current_window[500:] # 50% overlapThis pattern processes streaming ML inputs, maintains a sliding window of recent data, and continuously compares statistical distributions against training baselines. When drift exceeds thresholds, it triggers alerts or automated retraining workflows.
Apache Flink for stateful drift detection
For production-scale drift monitoring, Apache Flink provides stateful stream processing with exactly-once semantics. Flink's state backends maintain running statistics (mean, variance, percentiles) for each feature across windows, enabling drift detection without recomputing from raw events. Flink ML (introduced in Flink 1.13+) includes built-in operators for online learning and drift adaptation, allowing models to incrementally update as data distributions shift, a more sophisticated alternative to full retraining.
Prevention Through Data Governance
The most effective drift prevention happens upstream, before degraded data reaches your models. This is where data governance and event streaming intersect.
- Schema contracts define the structure, types, and valid ranges for events in your streams. Governance platforms like Conduktor enforce these contracts at write time through its data quality module, rejecting events that violate expectations. When a producer attempts to send a "user_age" of 500 or omit a required field, the contract blocks it before it corrupts your model's input stream. See Schema Registry and Schema Management for implementation details.
- Schema evolution policies control how event structures can change over time. Requiring backward compatibility ensures new fields are optional and existing fields maintain their semantics. This governance layer prevents the silent schema drift that destabilizes models.
- Data quality rules validate not just schema but business logic. A rule might enforce that "transaction_amount > 0" or "timestamp is within the last 5 minutes." These quality gates filter anomalous events before they become model inputs, reducing noise and preventing drift from data quality issues. For comprehensive data quality strategies, see Building a Data Quality Framework.
- Topic-level governance segregates different data quality tiers. Production models consume from gold-tier topics with strict quality enforcement, while experimental models can read bronze-tier streams with raw, unvalidated data. This separation prevents degraded data from reaching critical production models.
Monitoring and Remediation: Responding to Drift
Detection without remediation is just expensive alerting. Streaming ML systems need automated responses to drift events.
- Drift dashboards provide real-time visibility into model health. Visualizing feature distributions, prediction outputs, and performance metrics over time helps teams distinguish between temporary anomalies and sustained drift. Well-designed dashboards with clear status indicators make it easy to spot issues at a glance.
- Alerting thresholds trigger when drift metrics exceed acceptable bounds. A two-tier system works well: warnings for moderate drift that requires investigation, and critical alerts for severe drift that demands immediate action. Thresholds should be feature-specific, as some inputs naturally vary more than others.
- Automated retraining triggers initiate model updates when drift persists beyond thresholds. In a streaming MLOps pipeline, this means kicking off a training job that pulls recent labeled data, retrains the model, validates performance on holdout sets (separate validation data not used during training), and, if validation passes, deploys the updated model to production. The entire cycle happens without manual intervention.
- Model rollback capabilities provide a safety net when retraining fails or drift proves temporary. If a newly deployed model performs worse than the previous version, automated rollback restores the prior model while teams investigate. This requires maintaining model versions and routing infrastructure to switch between them.
- Feature updates sometimes address drift better than full retraining. If "time_since_last_login" drifts because users now log in less frequently, adding "weekly_active_sessions" as a complementary feature may stabilize predictions. Feature engineering in response to drift is an ongoing process in streaming ML.
MLOps Integration: CI/CD for Drifting Models
Managing drift at scale requires treating models as continuously evolving artifacts, not static deployments. This is the domain of MLOps, DevOps principles applied to machine learning.
- Continuous integration for models means automated testing of every model update against drift scenarios. Does the new model handle recent data distributions? Does it maintain performance on edge cases? Integration tests catch regressions before deployment.
- Continuous deployment automates the path from retraining to production. When a model passes validation, it deploys automatically to staging environments, then production after burn-in periods. Canary deployments (a gradual rollout strategy that routes a small percentage of traffic to the new model version while monitoring for issues) detect problems before full rollout.
- Continuous monitoring closes the loop, feeding drift signals back into the retraining pipeline. This creates a self-correcting system: drift detection triggers retraining, deployment automation updates production, and monitoring validates the fix.
Streaming platforms like Apache Kafka (especially Kafka 4.0+ with KRaft mode for lower-latency metadata operations) and Apache Flink, when paired with governance tools like Conduktor, provide the data infrastructure for this loop. Governed topics ensure clean training data, streaming feature stores provide consistent feature engineering, and event-driven architectures enable real-time monitoring and response.
Kafka 4.0's KRaft architecture eliminates ZooKeeper dependency, reducing operational complexity and improving metadata consistency for ML pipelines. This translates to faster schema updates, more reliable consumer group coordination, and reduced latency in feature serving, all critical for minimizing the window between drift detection and remediation.
Governance as Drift Prevention
Model drift in streaming systems is inevitable, but catastrophic drift is preventable. The key is data governance: enforcing quality at the source, controlling schema evolution, and maintaining contracts between data producers and ML consumers.
Upstream governance combined with downstream monitoring lets models adapt to changing conditions without silently degrading. Your models are only as stable as the data contracts protecting them.
Related Concepts
- Data Quality Dimensions: Accuracy, Completeness, and Consistency - Quality dimensions affecting model drift
- Schema Registry and Schema Management - Prevent schema drift in ML inputs
- Streaming Data Pipeline - Build resilient pipelines for ML models
Sources and References
- Google - ML Engineering Best Practices - Monitoring - Best practices for monitoring machine learning models in production, including drift detection strategies. https://developers.google.com/machine-learning/guides/rules-of-ml
- Evidently AI - Machine Learning Model Monitoring - Comprehensive guide to detecting and managing different types of model drift in production systems. https://www.evidentlyai.com/blog/machine-learning-monitoring-data-and-concept-drift
- AWS - Amazon SageMaker Model Monitor - Documentation on automated drift detection and monitoring for deployed ML models. https://docs.aws.amazon.com/sagemaker/latest/dg/model-monitor.html
- Chip Huyen - Designing Machine Learning Systems - Comprehensive coverage of MLOps practices including drift detection and model retraining strategies. O'Reilly Media, 2022.
- Conduktor - Data Governance for Streaming ML - Best practices for implementing data quality rules, schema enforcement, and topic governance to prevent model drift. https://www.conduktor.io/