Data Versioning in Streaming: Managing Event History
In traditional databases, versioning is straightforward: you have snapshots, backups, and transaction logs. But in streaming systems where millions of events flow continuously, how do you preserve history, enable reproducibility, and maintain governance? Data versioning in streaming contexts is the practice of tracking and managing different versions of your event data, schemas, and derived datasets over time.
This capability is critical for machine learning reproducibility, regulatory compliance, debugging production issues, and maintaining trust in your data pipelines. Let's explore how to implement effective versioning strategies in streaming architectures. 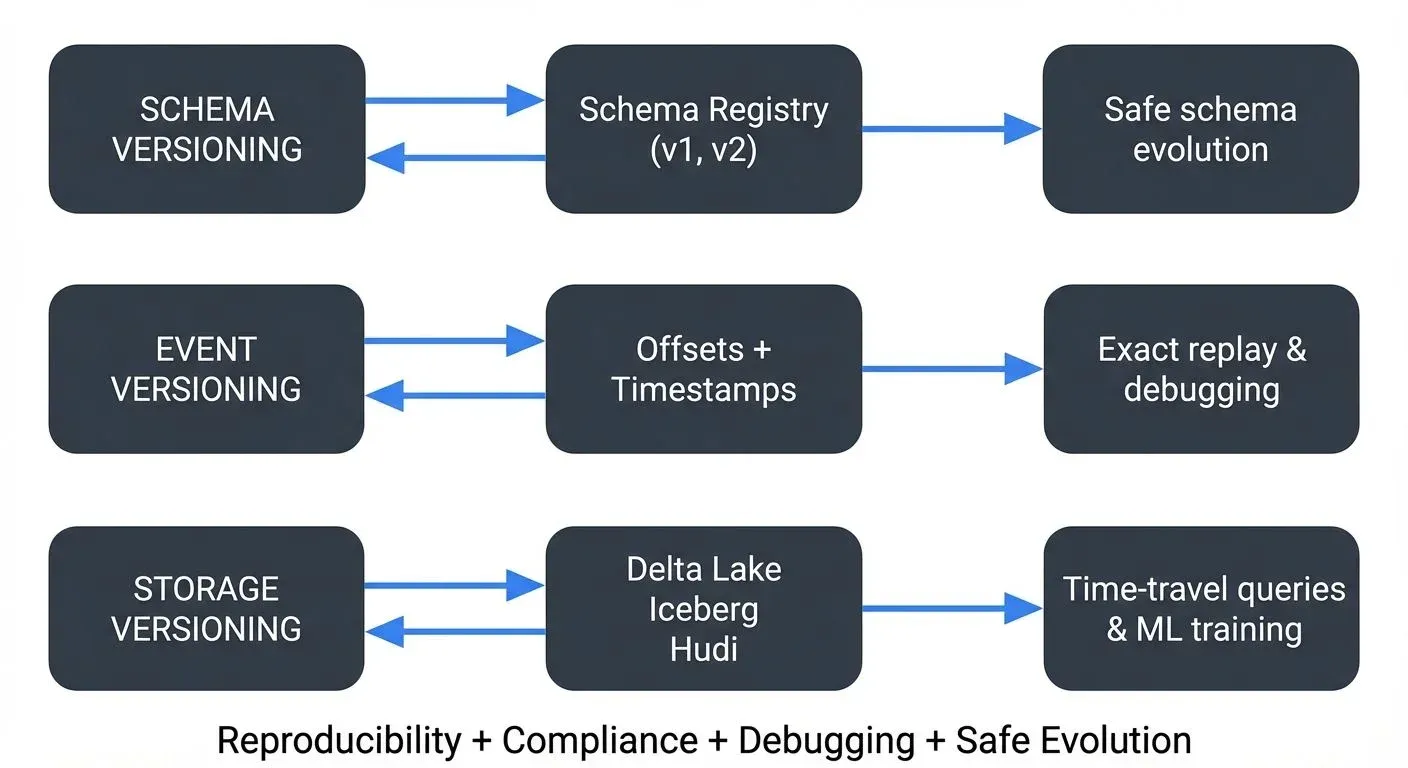
Streaming fundamentals
Before getting into versioning strategies, here are the key concepts:
- Event: A record representing something that happened at a specific time, a user action, sensor reading, database change, or business transaction. Events are immutable facts about the past.
- Stream: A continuous, ordered sequence of events flowing over time. Unlike batch datasets that have a defined beginning and end, streams are unbounded and always evolving.
- Producer: An application or service that writes events to a stream. For example, a web server producing user clickstream events, or a database producing change data capture events.
- Consumer: An application that reads and processes events from a stream. Consumers might aggregate data, trigger actions, update dashboards, or feed machine learning models.
- Offset: A sequential position number assigned to each event within a partition. Think of it like a line number in a log file, it identifies exactly where an event appears in the stream. Offsets enable precise replay and checkpointing.
- Partition: A subdivision of a stream that enables parallel processing. Events with the same key (like customer ID) go to the same partition, maintaining order within that partition while allowing the overall stream to scale horizontally.
- Schema: The structure and data types of an event, its fields, their types, and validation rules. Schemas act as contracts between producers and consumers, ensuring data compatibility.
Understanding these building blocks is essential because versioning in streaming systems operates at multiple levels: versioning the schemas that define event structure, versioning the events themselves through offsets and timestamps, and versioning the derived datasets created from streams.
Why Data Versioning Matters in Streaming
Unlike batch systems that process static datasets, streaming systems handle continuously evolving data. This creates unique challenges and requirements:
- Reproducibility: Machine learning models need to be retrained on the exact same data to validate improvements. Without versioning, you cannot reproduce the training dataset that was used three months ago, making model debugging impossible.
- Auditing and Compliance: Regulatory requirements often demand the ability to reconstruct exactly what happened at any point in time. Financial services, healthcare, and other regulated industries must prove what data was processed and when.
- Debugging Production Issues: When a pipeline produces incorrect results, you need to replay events exactly as they appeared at the time of failure. Versioning enables time-travel debugging to isolate the root cause.
- Safe Evolution: As business requirements change, event schemas evolve. Versioning ensures that consumers can handle both old and new event formats gracefully, preventing breaking changes from cascading through your system.
Schema Versioning: The Foundation
The most fundamental form of versioning in streaming systems is schema versioning. Every event schema should carry a version identifier, typically managed through a Schema Registry.
A Schema Registry is a centralized repository that stores and validates event schemas. When a producer writes an event, it registers the schema (if new) and includes a schema ID in the message. Consumers fetch the schema by ID to deserialize and validate incoming events. This ensures producers and consumers agree on data structure without hardcoding schemas in application code.
Modern Schema Registry Options (2025):
- Open Source: Karapace (Aiven's Kafka Schema Registry), Apicurio Registry (Red Hat), Confluent Schema Registry Community Edition
- Cloud-Native: AWS Glue Schema Registry, Azure Schema Registry, Upstash Schema Registry
- Commercial Platforms: Conduktor Platform provides enterprise-grade schema governance with validation, testing, and policy enforcement across multiple registries
Schema registries support multiple serialization formats: Avro (compact binary, strong typing), Protobuf (efficient, backward/forward compatible), and JSON Schema (human-readable, flexible). Avro remains popular for its schema evolution capabilities, while Protobuf is preferred for polyglot environments.
Consider an e-commerce order event that evolves over time:
// Version 1
{
"orderId": "12345",
"customerId": "c-789",
"amount": 99.99
}
// Version 2 - Added currency field with default
{
"orderId": "12345",
"customerId": "c-789",
"amount": 99.99,
"currency": "USD" // New field with default value
}
// Version 3 - Added payment method
{
"orderId": "12345",
"customerId": "c-789",
"amount": 99.99,
"currency": "USD",
"paymentMethod": "credit_card" // Another new field
}With schema versioning, downstream consumers can detect which version they're processing and apply appropriate transformation logic. The Schema Registry enforces compatibility modes to prevent breaking changes:
- BACKWARD: New schema can read data written with previous schema (most common). You can add optional fields or remove fields with defaults.
- FORWARD: Old schema can read data written with new schema. You can add fields with defaults or remove optional fields.
- FULL: Both backward and forward compatible. Most restrictive but safest for long-running systems.
- NONE: No compatibility checks. Dangerous, use only during prototyping.
A consumer handling multiple versions might look like:
def process_order(event):
schema_version = event.schema_id
if schema_version == 1:
# Handle v1: assume USD if no currency
return Order(
order_id=event['orderId'],
customer_id=event['customerId'],
amount=event['amount'],
currency='USD',
payment_method='unknown'
)
elif schema_version == 2:
# Handle v2: default payment method
return Order(
order_id=event['orderId'],
customer_id=event['customerId'],
amount=event['amount'],
currency=event['currency'],
payment_method='unknown'
)
else: # v3 and beyond
# Handle latest schema
return Order(
order_id=event['orderId'],
customer_id=event['customerId'],
amount=event['amount'],
currency=event['currency'],
payment_method=event['paymentMethod']
)This explicit version handling ensures consumers gracefully adapt to schema evolution without breaking when encountering older events during replay or reprocessing.
For deeper coverage of schema management patterns, see Schema Registry and Schema Management and Schema Evolution Best Practices.
Event-Level Versioning Strategies
Beyond schemas, individual events themselves can carry version metadata. This enables fine-grained control over how different versions are processed:
- Semantic Versioning: Events include version numbers that signal breaking changes (major), new features (minor), or bug fixes (patch). Consumers can route events based on version compatibility.
- Event Type Versioning: Instead of evolving a single event type, create new types for major changes. For example,
OrderCreatedmight evolve intoOrderCreatedV2, allowing both versions to coexist during migration periods. - Timestamp-Based Versioning: Every event carries production and ingestion timestamps. These enable time-travel queries to reconstruct state as it existed at any historical moment.
Time-Based Versioning: Offsets and Watermarks
Apache Kafka 4.0+ (stable in 2025 with KRaft mode, removing ZooKeeper dependency) provides built-in versioning through offsets and timestamps. Each event receives a sequential offset number within its partition, creating an immutable, ordered log.
Offsets enable precise replay: you can restart a consumer from any historical point and reprocess events exactly as they occurred. Combined with timestamp indexing, you can query specific time ranges.
Example: Offset-Based Replay
from kafka import KafkaConsumer, TopicPartition
# Replay events from a specific offset
consumer = KafkaConsumer(bootstrap_servers=['localhost:9092'])
partition = TopicPartition('orders', 0)
consumer.assign([partition])
# Seek to offset 10000 to replay from that point
consumer.seek(partition, 10000)
for message in consumer:
print(f"Offset {message.offset}: {message.value}")
if message.offset >= 15000:
break # Stop at offset 15000Watermarks extend this concept to handle late-arriving data, a common challenge in distributed systems where network delays, clock skew, or batch processing cause events to arrive out of order. For example, an event timestamped 2:00 PM might arrive after an event timestamped 2:05 PM.
Watermarks represent a threshold timestamp where the system considers all earlier events to have arrived. Once a watermark passes time T, the system assumes it has seen all events with timestamps ≤ T. This enables:
- Window Closing: Aggregation windows can be finalized and results emitted
- State Snapshots: Processing state can be checkpointed at specific watermark positions
- Reproducible Processing: Replaying from a watermark recreates identical results
Stream processing frameworks like Apache Flink use watermarks extensively. Versioning watermarks, tracking which watermark position was used for specific computations, lets you snapshot processing state at specific points, enabling reproducible stream processing and time-travel debugging.
For more on watermark mechanics and late data handling, see Event Time and Watermarks in Flink and Handling Late-Arriving Data in Streaming.
Versioning for Machine Learning Workflows
ML pipelines have unique versioning requirements. Training data must be frozen at specific points in time to ensure reproducibility:
- Training Data Snapshots: Periodically materialize streaming features into versioned datasets. "Point-in-time correct" means capturing feature values exactly as they existed at a specific timestamp, avoiding data leakage where future information accidentally influences historical training data.
- Modern Feature Store Options (2025):
- Open Source: Feast (CNCF project), Feathr (LinkedIn)
- Cloud-Native: AWS SageMaker Feature Store, Azure ML Feature Store, Google Vertex AI Feature Store
- Commercial: Tecton, Hopsworks
Feature stores create temporal snapshots, when you request features for timestamp T, you get the latest known values as of time T, never data from the future. This temporal consistency is critical for ML reproducibility.
Feature Versioning: As feature engineering logic evolves, version the transformations themselves. Feature stores track both the data and the code that generated it, enabling model retraining with identical inputs.
# Example: Feast feature retrieval with point-in-time correctness
from feast import FeatureStore
store = FeatureStore(repo_path=".")
# Get features as they existed on 2024-12-01
training_data = store.get_historical_features(
entity_df=orders, # Orders from December 2024
features=[
"customer_profile:total_purchases",
"customer_profile:avg_order_value",
"customer_profile:days_since_last_purchase"
],
event_timestamp_col="order_timestamp"
).to_df()
# This ensures no data leakage—features reflect state at order timeModel Lineage: Connect model versions back to the specific data versions used for training. This creates an audit trail from predictions back through the model to the source events, essential for debugging model drift and regulatory compliance.
For comprehensive coverage of feature store patterns, see Feature Stores for Machine Learning.
Storage-Backed Versioning: Modern Table Formats
Modern data lakes support versioning at the storage layer, treating data like Git treats code. These table formats sit between compute engines (Spark, Flink, Trino) and object storage (S3, ADLS, GCS), providing ACID transactions, schema evolution, and time travel over raw files.
Delta Lake Time Travel (Delta 3.x in 2025) maintains transaction logs that record every change to a table. Queries can specify VERSION AS OF or TIMESTAMP AS OF to read historical snapshots.
-- Query orders table as it existed on December 1st, 2024
SELECT * FROM orders
TIMESTAMP AS OF '2024-12-01 00:00:00'
WHERE customer_id = 'c-789';
-- Query a specific version number (from transaction log)
SELECT * FROM orders
VERSION AS OF 42
WHERE order_date = '2024-12-01';
-- Compare current vs historical data
SELECT
CURRENT.total_amount - historical.total_amount AS amount_diff
FROM orders CURRENT
LEFT JOIN orders TIMESTAMP AS OF '2024-11-01' historical
ON CURRENT.order_id = historical.order_id;- Apache Iceberg provides similar capabilities with hidden partitioning, snapshot isolation, and better handling of schema evolution. Multiple readers can query different versions simultaneously without interference. Iceberg is particularly strong for large-scale analytics workloads.
- Apache Hudi (Hadoop Upserts Deletes and Incrementals) specializes in incremental processing and CDC (Change Data Capture) use cases. It offers "incremental queries" to fetch only changed records between two timestamps.
- Apache Paimon (incubating, 2025) is a newer streaming lake storage format designed specifically for real-time data lakes. It provides streaming reads/writes with low latency while maintaining batch query performance.
- LakeFS creates Git-like branches, commits, and tags for object storage. Data engineers can create experimental branches for testing new pipelines, merge validated changes, and roll back problematic deployments. This brings software engineering practices to data management.
These systems solve the storage cost challenge through snapshot isolation and incremental changes. Only the delta between versions needs storage, not complete copies of entire datasets. Combined with streaming ingestion from Kafka (using Kafka's tiered storage feature in 4.0+ for cost-effective long-term retention), this creates end-to-end versioned data platforms.
For deeper dives into table format internals, see Iceberg Table Architecture: Metadata and Snapshots and Streaming to Lakehouse Tables.
Implementing Versioned Streaming Architectures
A complete versioning strategy combines multiple layers:
- Schema versioning in Schema Registry for event structure
- Offset-based versioning in Kafka for event replay
- Snapshot versioning in feature stores for ML reproducibility
- Storage versioning in data lakes for long-term time travel
Best practices include:
- Immutable Events: Never update events in place. Instead, publish new events that supersede previous ones. This preserves complete history for auditing. For patterns on building systems around immutable event logs, see Event Sourcing Patterns with Kafka.
- Version Metadata: Include schema version, event version, and timestamps in every message. Make versioning explicit rather than implicit.
- Retention Policies: Balance versioning needs against storage costs. Kafka can retain weeks or months of events; data lakes can retain years with tiered storage. For maintaining current state while preserving history, see Kafka Log Compaction Explained and Tiered Storage in Kafka.
- Automated Testing: Validate that consumers handle multiple schema versions correctly. Test backward and forward compatibility before deploying changes.
Data Contracts and Governance
Versioning is inseparable from data governance. Governance platforms enable teams to enforce versioning policies, require schema registration, and validate data contracts across streaming infrastructure.
Data contracts specify not just schema versions but also SLAs, ownership, and evolution rules. A contract might declare:
- Schema compatibility mode (BACKWARD, FORWARD, FULL)
- Required vs. optional fields
- Valid value ranges and constraints
- Deprecation timelines for old versions
- Owner teams and contact information
- Expected throughput and latency SLAs
When a producer wants to introduce a breaking change, governance systems can block the deployment and suggest backward-compatible alternatives.
Conduktor Platform provides enterprise-grade data governance for streaming systems, including:
- Schema Governance: Enforce compatibility rules, validate schemas against contracts with Schema Registry management, and track schema evolution across environments
- Data Quality Rules: Validate event content beyond schema structure (value ranges, business logic, data freshness)
- Self-Service Discovery: Enable data consumers to find datasets, understand versions, and explore topic metadata using topic discovery
- Policy Enforcement: Prevent breaking changes from reaching production, require approvals for schema evolution
This prevents the chaos that emerges when teams evolve events independently without considering downstream impacts. Versioning combined with governance creates a controlled evolution path for streaming architectures, ensuring changes are deliberate, tested, and communicated to affected teams.
For broader governance patterns, see Policy Enforcement in Streaming and Streaming Data Product Asset.
Challenges and Tradeoffs
Data versioning in streaming systems comes with costs:
- Storage Overhead: Retaining historical versions consumes storage. Tiered storage and compaction strategies help, but there's always a tradeoff between retention and cost.
- Complexity: Supporting multiple versions increases code complexity. Transformation logic must handle various schemas, and testing becomes more demanding.
- Performance: Reading historical versions may be slower than querying current state. Indexing and caching strategies are necessary for acceptable query performance.
- Consistency: In distributed streaming systems, determining "what version was active at time T" requires careful timestamp coordination and clock synchronization.
Conclusion
Data versioning transforms streaming systems from ephemeral pipelines into reliable, auditable platforms. Combining schema versioning, offset-based replay, storage time travel, and governance policies gives you reproducibility, compliance, and safe evolution.
The investment pays off in faster debugging, more reliable ML models, and stronger regulatory confidence. Versioning is no longer optional in modern streaming architectures — it's a baseline requirement for production systems.
Related Concepts
- Apache Kafka - Platform providing offset-based versioning and replay capabilities
- Exactly-Once Semantics in Kafka - Processing guarantees essential for reproducible versioning
- Disaster Recovery Strategies for Kafka Clusters - Protecting versioned event history
Sources
- Delta Lake Time Travel Documentation
- Apache Iceberg Table Versioning
- LakeFS Documentation: Git for Data Lakes
- Confluent Schema Registry
- Feast Feature Store Versioning
Written by Stéphane Derosiaux · Last updated April 29, 2026