Disaster Recovery Strategies for Kafka Clusters
Disaster recovery (DR) planning is critical for any production Kafka deployment. As organizations increasingly rely on real-time data streaming for mission-critical applications, the ability to recover from failures — hardware malfunctions, datacenter outages, or catastrophic events — is essential for business continuity.
A solid disaster recovery strategy for Kafka goes beyond basic replication. It requires understanding recovery time objectives (RTO), recovery point objectives (RPO), and the trade-offs between consistency, availability, and cost.
Understanding Kafka's Built-in Replication
Before implementing complex DR strategies, it's important to understand Kafka's native replication capabilities, which form the foundation of any resilience plan.
Kafka replicates data across multiple brokers within a cluster. Each partition has one leader and multiple follower replicas that maintain in-sync replicas (ISR), the set of replicas that have caught up with the leader's log. The replication factor determines how many copies of the data exist. For production workloads, a replication factor of at least 3 is recommended.
Two critical configurations impact data durability:
min.insync.replicas: The minimum number of replicas that must acknowledge a write for it to be considered successful. Setting this to 2 (with a replication factor of 3) provides strong durability guarantees while tolerating one broker failure.acks=all: Producer configuration ensuring messages are acknowledged only after being written to all in-sync replicas.
| Configuration | Durability | Availability | Use Case |
|---|---|---|---|
replication.factor=3, min.insync.replicas=1 | Low | High | Non-critical logs, metrics |
replication.factor=3, min.insync.replicas=2 | High | Medium | Most production workloads |
replication.factor=3, min.insync.replicas=3 | Very High | Low | Critical financial transactions |
replication.factor=3 and min.insync.replicas=2, ensuring that even if one broker fails, data remains available and no transactions are lost. Producer applications should also be configured for durability:
Properties props = new Properties();
props.put("bootstrap.servers", "kafka-cluster:9092");
props.put("acks", "all");
props.put("retries", Integer.MAX_VALUE);
props.put("max.in.flight.requests.per.connection", 5);
props.put("enable.idempotence", true);
props.put("compression.type", "zstd");This configuration ensures messages aren't lost during network failures or broker restarts, with idempotence preventing duplicates during retries.
However, single-cluster replication only protects against individual broker failures, not datacenter-wide disasters.
Multi-Datacenter Replication Patterns
To protect against datacenter failures, organizations implement multi-datacenter replication using several architectural patterns. The choice depends on recovery objectives, budget, and operational complexity tolerance. 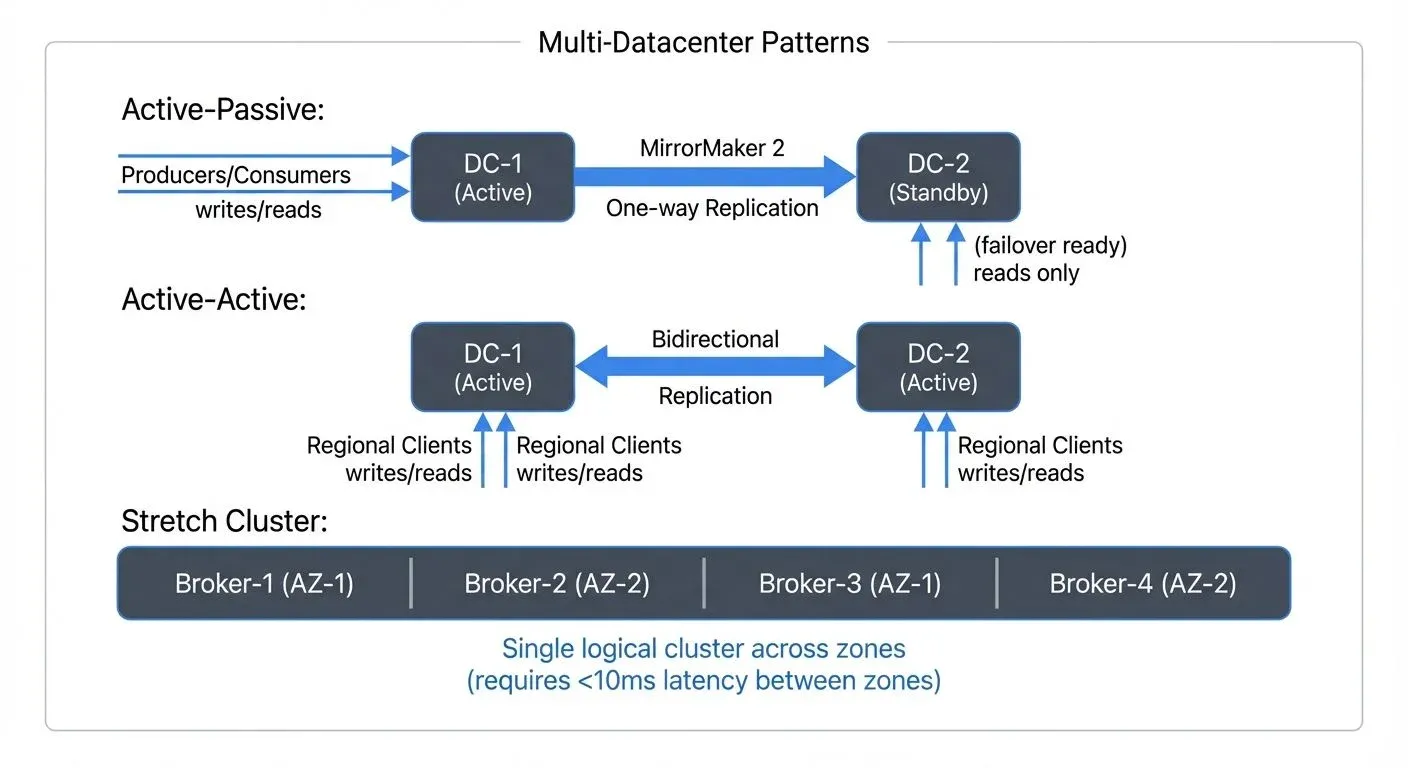
| Pattern | RTO | RPO | Complexity | Cost Efficiency | Best For |
|---|---|---|---|---|---|
| Active-Passive | Minutes-Hours | Seconds-Minutes | Low | Medium (50% idle) | Most enterprises |
| Active-Active | Near-Zero | Seconds | High | High (100% utilized) | Global services |
| Stretch Cluster | Zero (automatic) | Zero | Medium | High | Single-region HA |
Active-Passive (Warm Standby)
In this pattern, one cluster (active) handles all production traffic while a secondary cluster (passive) receives replicated data but doesn't serve client requests. During a disaster, applications failover to the passive cluster.
MirrorMaker 2 (MM2) is the recommended tool for cross-cluster replication. It replicates topics, consumer groups, ACLs, and configurations between clusters while preserving message ordering and offsets through checkpoint synchronization.
# mm2.properties - Active-Passive Configuration
clusters = primary, secondary
primary.bootstrap.servers = primary-kafka:9092
secondary.bootstrap.servers = secondary-kafka:9092
# Enable one-way replication
primary->secondary.enabled = true
primary->secondary.topics = orders.*, inventory.*, customers.*
# Preserve consumer group offsets for seamless failover
sync.group.offsets.enabled = true
sync.group.offsets.interval.seconds = 60
emit.checkpoints.enabled = true
emit.checkpoints.interval.seconds = 60
# Replicate topic configurations
sync.topic.configs.enabled = true
sync.topic.acls.enabled = true
# Ensure durability
replication.factor = 3
checkpoints.topic.replication.factor = 3
offset-syncs.topic.replication.factor = 3This approach provides simpler operational management and clear failover procedures, but results in unused infrastructure capacity during normal operations. The secondary cluster typically runs with 50-70% capacity reserved for failover scenarios.
Active-Active (Multi-Active)
In active-active deployments, multiple clusters in different regions simultaneously serve production traffic. Applications write to their nearest cluster, and data is replicated bidirectionally.
This pattern minimizes latency for globally distributed users and eliminates unused capacity. However, it introduces complexity around conflict resolution and requires careful coordination of schema changes and topic configurations. Applications must implement idempotent processing to handle potential duplicate messages from bidirectional replication.
An e-commerce platform with users across North America and Europe might deploy active-active Kafka clusters in both regions, allowing each region to process orders locally while keeping product catalogs synchronized across regions. Order events flow locally with sub-100ms latency, while cross-region catalog updates can tolerate 1-2 second replication lag.
Stretch Clusters
Some organizations deploy single Kafka clusters across multiple availability zones or nearby datacenters. Brokers are distributed across locations, and rack awareness (configured via broker.rack property) ensures replicas are placed in different zones to maximize resilience.
This provides automatic failover without application changes but requires low-latency (<10ms), high-bandwidth (10Gbps+) connectivity between locations and doesn't protect against region-wide failures.
KRaft Mode Considerations
Modern Kafka deployments use KRaft (Kafka Raft metadata mode) instead of ZooKeeper, which simplifies DR operations. In KRaft mode, metadata is stored in Kafka itself, eliminating the need to replicate and backup a separate ZooKeeper ensemble.
For multi-datacenter KRaft deployments:
- Controller quorum nodes should be distributed across datacenters
- Use an odd number of controllers (typically 3 or 5) for quorum decisions
- Plan controller placement to survive datacenter failures while maintaining quorum
KRaft's unified architecture reduces DR complexity and provides faster controller failover (typically under 1 second) compared to ZooKeeper-based deployments.
Backup and Recovery Mechanisms
While replication provides high availability, backups offer protection against logical failures like accidental topic deletion, application bugs corrupting data, or security incidents. Modern Kafka deployments leverage tiered storage for efficient backup strategies.
Tiered Storage for Long-Term Backup
Kafka 3.6+ includes production-ready tiered storage (KIP-405), which automatically offloads older log segments to object storage while keeping recent data on local disks. This provides cost-effective, long-term data retention for DR scenarios.
# server.properties - Enable Tiered Storage
remote.log.storage.system.enable=true
remote.log.manager.task.interval.ms=30000
# S3 configuration
remote.log.storage.manager.class.name=org.apache.kafka.server.log.remote.storage.RemoteLogManager
rsm.config.remote.storage.type=s3
rsm.config.s3.bucket.name=kafka-dr-backup
rsm.config.s3.region=us-east-1
# Define retention for local vs remote storage
log.retention.hours=168 # 7 days local
log.remote.retention.hours=8760 # 1 year remoteWith tiered storage, organizations can maintain years of historical data for compliance and disaster recovery without expensive local storage, while still supporting topic recovery from any point in the retention window.
Topic Snapshots and Export
For critical topics requiring independent backups beyond tiered storage, organizations export data to object storage using tools like:
- Kafka Connect S3 Sink Connector: Continuously exports topic data to S3/GCS/Azure Blob Storage
- Custom consumers: Purpose-built applications that snapshot specific topics periodically
Consumer Offset Preservation
DR plans must account for consumer offsets to resume processing at the correct position after failover. MirrorMaker 2 automatically replicates consumer group offsets between clusters using offset translation, but organizations should also:
- Periodically backup the
__consumer_offsetstopic using tiered storage or snapshots - Maintain offset mappings in external databases for critical consumer groups
- Document offset reset procedures for scenarios where offset synchronization fails
State Store Backups for Kafka Streams
Applications using Kafka Streams maintain local state stores (RocksDB-backed key-value stores). DR strategies should include:
- Changelog topics: Ensure changelog topics have adequate replication factor (3+) and are included in cross-cluster replication
- State store backup: Configure Kafka Streams to periodically backup state stores to shared storage
- Recovery procedures: Document how to rebuild state stores from changelog topics after datacenter failover
Properties streamsConfig = new Properties();
streamsConfig.put(StreamsConfig.STATE_DIR_CONFIG, "/var/kafka-streams/state");
streamsConfig.put(StreamsConfig.REPLICATION_FACTOR_CONFIG, 3);
// Ensure changelog topics are replicated for DR
streamsConfig.put(StreamsConfig.producerPrefix(ProducerConfig.ACKS_CONFIG), "all");Monitoring and Testing DR Plans
A disaster recovery plan is only valuable if it works when needed. Regular testing and continuous monitoring are essential.
Monitoring Requirements
Key metrics to monitor for DR readiness include:
| Metric | Warning Threshold | Critical Threshold | Impact |
|---|---|---|---|
| MirrorMaker 2 replication lag | >30 seconds | >300 seconds | Increased RPO during failover |
| Under-replicated partitions | >0 for 5 minutes | >5% of partitions | Data durability at risk |
| Consumer lag | >10,000 messages | >100,000 messages | Extended recovery time |
| Broker availability | | Potential data loss | | |
| Disk usage | >80% | >90% | May prevent replication |
| Network throughput to DR site | <50% capacity | <20% capacity | Replication lag increases |
- Real-time replication lag tracking between primary and DR clusters via monitoring dashboards
- Alerting on under-replicated partitions and unhealthy brokers
- Consumer lag monitoring across all consumer groups
- Cluster health dashboards for primary and DR environments through Insights
- Configuration drift detection between environments with risk analysis
Modern observability platforms integrate with Kafka's JMX metrics and support OpenTelemetry for distributed tracing across the entire streaming pipeline.
DR Testing Procedures
Organizations should regularly conduct failover drills, simulating various failure scenarios:
Quarterly Full Failover Tests
- Controlled failover to secondary datacenter with production-like load
- Measure actual RTO (time to restore service) and RPO (data loss)
- Validate MirrorMaker 2 offset synchronization for seamless consumer resumption
- Test DNS/load balancer reconfiguration for client redirection
- Verify application reconnection logic handles cluster endpoint changes
Monthly Partial Tests
- Simulate single broker failures to validate in-sync replica behavior
- Test producer and consumer retry mechanisms
- Verify monitoring alerts trigger correctly
- Practice runbook procedures without full failover
Chaos Engineering with Conduktor Gateway
- Conduktor Gateway acts as a proxy layer for Kafka, enabling controlled fault injection for chaos testing
- Inject network latency between datacenters to test replication lag handling
- Simulate broker failures without actual production impact
- Test partition leader election scenarios
- Validate application behavior under degraded conditions
Documenting each test, measuring actual RTO/RPO achieved, and updating runbooks based on lessons learned ensures DR plans remain effective as systems evolve.
Disaster Recovery in the Data Streaming Ecosystem
Kafka rarely operates in isolation. Modern data streaming architectures include producers, consumers, stream processing frameworks (Kafka Streams, Apache Flink), and downstream systems.
Effective DR strategies must consider the entire streaming pipeline. If Kafka fails over to a secondary cluster, producers must redirect traffic, stream processing applications must reconfigure cluster endpoints, and consumers must switch to the new cluster without data loss or duplication.
Coordinating Pipeline Failover
Service discovery mechanisms and orchestration tools help coordinate these transitions:
DNS-Based Failover
- Use DNS with low TTL (30-60 seconds) for Kafka bootstrap servers
- Update DNS records during failover to point to DR cluster
- Applications automatically reconnect to new cluster after TTL expires
- Simple but introduces TTL delay and requires proper client reconnection logic
Application-Level Configuration
- Store cluster endpoints in centralized configuration (Consul, etcd, Kubernetes ConfigMaps)
- Applications watch for configuration changes and reconnect dynamically
- Provides fine-grained control but requires custom reconnection logic
Load Balancer Abstraction
- Place load balancers in front of Kafka clusters
- Redirect traffic at network layer during failover
- Transparent to applications but adds latency and potential bottleneck
Stream Processing Considerations
Apache Flink Failover Flink applications require careful checkpoint and savepoint management for DR:
- Take savepoints before planned failovers to preserve exactly-once processing state
- Restart Flink jobs with updated Kafka cluster endpoints after failover
- Ensure checkpoint storage (S3, HDFS) is accessible from DR environment
- Configure Flink to tolerate temporary Kafka unavailability during transitions
Kafka Streams Failover Kafka Streams applications benefit from MirrorMaker 2's offset synchronization:
- Changelog topics must be replicated to DR cluster via MirrorMaker 2
- Applications can resume processing from synchronized offsets after failover
- State stores rebuild automatically from changelog topics if local state is lost
Schema Registry DR
Schema registries store message schemas and require their own DR strategy. If using Schema Registry (Confluent Schema Registry, Karapace, or compatible alternatives):
- Karapace is the recommended open-source Schema Registry implementation
- Replicate schema data between primary and DR environments using registry-specific replication
- Some organizations use MirrorMaker 2 to replicate the
_schemastopic between clusters - Maintain schema compatibility rules consistently across environments
Conduktor Platform provides schema registry governance features including:
- Centralized schema management across multiple clusters
- Schema compatibility validation before deployment
- Configuration drift detection between primary and DR schema registries
Recovery Objectives and Trade-offs
Different business requirements demand different DR strategies. Understanding RTO and RPO helps determine the appropriate approach.
Recovery Time Objective (RTO)
RTO defines how quickly systems must be restored after a failure. Different strategies offer different RTO characteristics:
| Strategy | Typical RTO | Automation Level | Factors |
|---|---|---|---|
| Active-Active | <1 minute | Full (automatic routing) | DNS/LB switching, client reconnection |
| Active-Passive (Automated) | 5-15 minutes | High (scripted failover) | MM2 lag, DNS propagation, application startup |
| Active-Passive (Manual) | 30-120 minutes | Low (runbook-based) | Human coordination, validation steps |
| Backup Recovery | 2-24+ hours | Low | Data restoration time, cluster rebuild |
Recovery Point Objective (RPO)
RPO defines the maximum acceptable data loss during a failure:
Within-Cluster RPO (near-zero)
- Synchronous replication using
acks=allandmin.insync.replicas=2+ - Messages acknowledged only after replication to multiple brokers
- Protects against broker failures but not datacenter failures
Cross-Cluster RPO (seconds to minutes)
- MirrorMaker 2 replication is asynchronous by design
- Typical replication lag: 1-30 seconds under normal conditions
- Degraded network or high throughput can increase lag to minutes
- Monitor replication lag continuously to understand actual RPO
Cost-Benefit Analysis
Organizations must balance RTO/RPO requirements against infrastructure costs:
Stock Trading Platform (High-Frequency Trading)
- Requirement: RPO <1 second, RTO <1 minute
- Solution: Active-active across regions with synchronous writes
- Cost: 2x infrastructure + cross-region bandwidth
- Justification: Regulatory compliance, revenue impact of downtime
E-Commerce Order Processing
- Requirement: RPO <30 seconds, RTO <15 minutes
- Solution: Active-passive with automated failover
- Cost: 1.7x infrastructure (70% DR capacity)
- Justification: Balance between availability and cost
Log Aggregation System
- Requirement: RPO <10 minutes, RTO <2 hours
- Solution: Periodic backups to object storage, manual recovery
- Cost: 1.1x infrastructure (backup storage only)
- Justification: Non-critical data, acceptable loss window
Summary
Disaster recovery for Kafka clusters requires a layered approach combining native replication, multi-datacenter architectures, backup mechanisms, and comprehensive testing.
- Foundation: Single-cluster replication with
replication.factor=3,min.insync.replicas=2, andacks=allprotects against individual broker failures and provides the baseline for any DR strategy. - Multi-Datacenter Protection: Organizations choose between active-passive (simple, cost-effective), active-active (zero-RTO, globally distributed), or stretch clusters (automatic failover within regions) based on RTO/RPO requirements and budget constraints.
- Modern Tooling: MirrorMaker 2 handles cross-cluster replication with offset synchronization. Tiered storage (Kafka 3.6+) provides cost-effective long-term backup. KRaft mode simplifies DR by eliminating ZooKeeper dependencies.
- Ecosystem Coordination: Successful DR strategies consider the entire streaming pipeline, producers, consumers, stream processors (Flink, Kafka Streams), schema registries (Karapace), and downstream systems must all be included in failover procedures.
- Monitoring and Testing: Platforms like Conduktor provide centralized visibility across clusters, while Conduktor Gateway enables chaos engineering for realistic DR testing. Regular failover drills ensure procedures work when disasters actually occur.
Matching DR approaches to actual business requirements — RTO, RPO, budget — determines what level of protection makes sense. The patterns here scale from simple backup-and-restore to zero-downtime active-active setups.
Related Concepts
- Kafka MirrorMaker 2 for Cross-Cluster Replication - Deep dive into cross-cluster replication architecture and configuration for multi-region DR strategies.
- Kafka Capacity Planning - Plan DR cluster sizing to handle failover traffic while balancing cost and performance requirements.
- Chaos Engineering for Streaming Systems - Validate DR procedures through controlled failure injection and resilience testing.
Sources and References
- Apache Kafka Documentation - "Replication" - https://kafka.apache.org/documentation/#replication
- Apache Kafka Documentation - "MirrorMaker 2 (Geo-Replication)" - https://kafka.apache.org/documentation/#georeplication
- Apache Kafka Documentation - "KRaft Mode" - https://kafka.apache.org/documentation/#kraft
- KIP-405: Kafka Tiered Storage - https://cwiki.apache.org/confluence/display/KAFKA/KIP-405
- Confluent Documentation - "Multi-Datacenter Architectures" - https://docs.confluent.io/platform/current/multi-dc-deployments/index.html
- Conduktor Platform Documentation - https://www.conduktor.io/
- Karapace Schema Registry - https://github.com/aiven/karapace
- AWS Best Practices - "Disaster Recovery for Apache Kafka" - https://aws.amazon.com/blogs/big-data/