Chaos Engineering for Streaming Systems
Chaos engineering is the discipline of experimenting on a distributed system to build confidence in its ability to withstand turbulent conditions in production. When applied to streaming systems like Apache Kafka, Apache Flink, or Apache Pulsar, chaos engineering becomes essential for ensuring that real-time data pipelines remain resilient under failure conditions.
This article covers how chaos engineering principles apply to streaming architectures, the unique challenges these systems present, and practical approaches for testing resilience in production-like environments.
What is Chaos Engineering?
Chaos engineering originated at Netflix with the creation of Chaos Monkey, a tool that randomly terminates instances in production to ensure that systems can survive unexpected failures. The core principle is simple: proactively inject failures into your system to discover weaknesses before they cause outages.
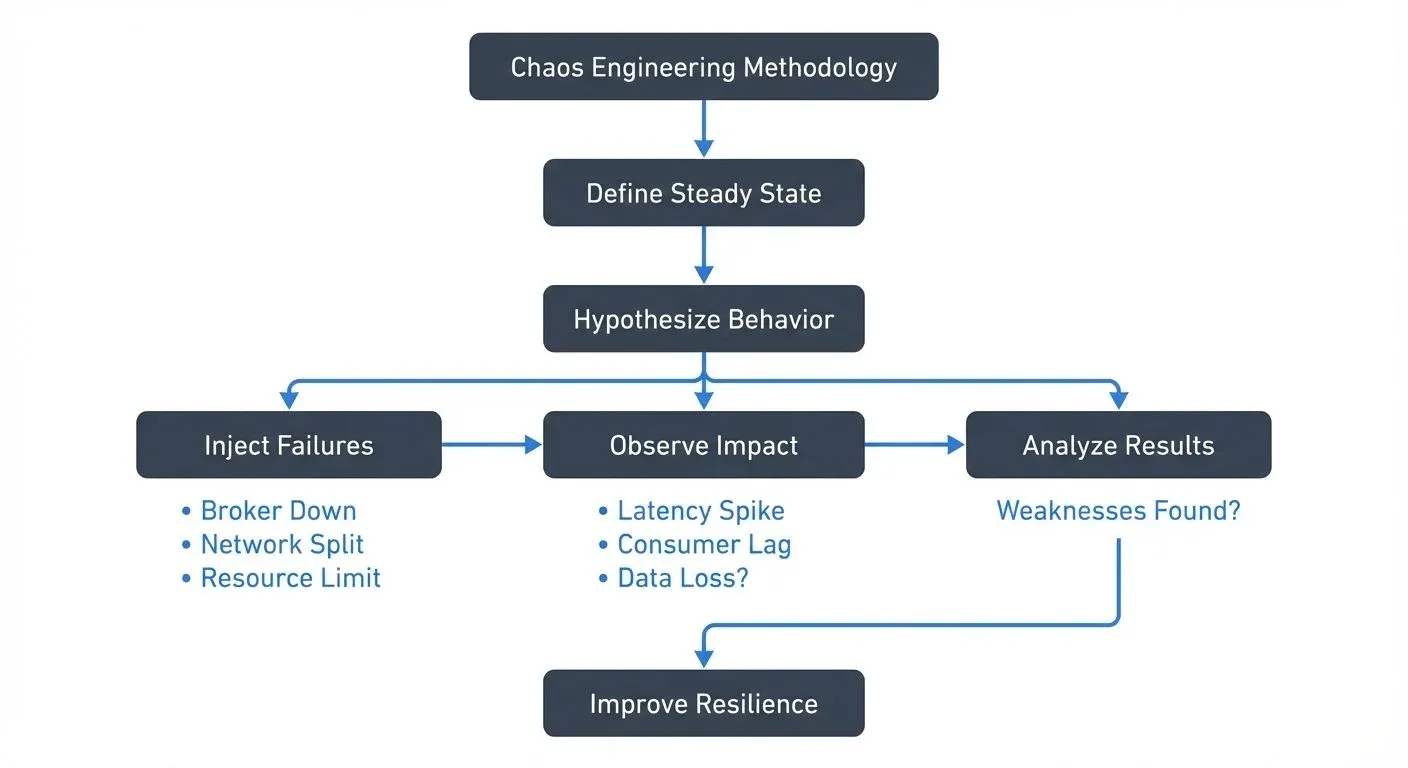
The practice follows a scientific method:
- Define a steady state that represents normal system behavior
- Hypothesize that this steady state will continue in both control and experimental groups
- Introduce variables that reflect real-world events (server failures, network latency, resource exhaustion)
- Observe the differences between control and experimental groups
- Disprove the hypothesis by finding weaknesses, or gain confidence in system resilience
For streaming systems, this methodology is particularly valuable because failures can cascade quickly through distributed pipelines, affecting downstream consumers and business-critical applications.
Why Streaming Systems Need Chaos Engineering
Streaming platforms present unique challenges that make chaos engineering especially important:
- Real-time guarantees: Unlike batch systems where failures can be retried during the next scheduled run, streaming systems must handle failures while maintaining near-real-time data delivery. A broker failure in Kafka, for example, should not cause data loss or significant processing delays.
- Stateful processing: Stream processors like Apache Flink maintain state across millions of events. When failures occur, state must be recovered correctly, or the system may produce incorrect results. Testing state recovery under various failure scenarios is critical.
- Distributed coordination: Streaming systems rely on consensus protocols for coordination. Kafka 4.0+ uses KRaft (the modern Raft-based consensus protocol that replaced ZooKeeper). Network partitions, leader elections, and split-brain scenarios can cause subtle bugs that only appear under specific failure conditions. KRaft's faster metadata operations (milliseconds vs seconds for leader elections) improve failure recovery, making chaos testing even more critical to validate these improvements. For Kafka architecture details, see Apache Kafka.
- Consumer group dynamics: Kafka consumer groups automatically rebalance when consumers join or leave. These rebalances can cause temporary processing pauses. Understanding how your system behaves during rebalances under load is essential for capacity planning.
Common Failure Scenarios in Streaming Systems
Effective chaos engineering requires understanding the failure modes specific to streaming architectures. Here are the most impactful scenarios to test:
- Broker failures: Randomly terminate broker instances to verify that partition replicas take over seamlessly. Monitor metrics like under-replicated partitions and client reconnection times.
- Network partitions: Introduce latency or completely partition network segments to test how producers and consumers handle timeouts. This reveals issues with configuration values like
request.timeout.msandsession.timeout.ms. - Consumer lag injection: Artificially slow down consumers to create lag, then observe how the system recovers. This tests autoscaling policies and lag monitoring alerts.
- Resource exhaustion: Limit CPU, memory, or disk I/O on brokers or stream processors to simulate resource contention. This helps validate performance under degraded conditions.
- State corruption: For stateful stream processors, intentionally corrupt state stores to verify that recovery mechanisms work correctly from checkpoints or snapshots.
Chaos Engineering Practices for Streaming
Implementing chaos engineering for streaming systems requires a structured approach:
Start Small and Build Confidence
Begin experiments in non-production environments that closely mirror production configurations. Use realistic data volumes and traffic patterns. As confidence grows, carefully introduce experiments in production during low-traffic periods with strong monitoring in place.
Define Clear Success Metrics
Before running experiments, establish measurable criteria for success:
- End-to-end latency remains below SLA thresholds
- Zero data loss (verify message counts match)
- Consumer lag recovers within acceptable time windows
- No cascading failures to downstream systems
Use Gradual Rollout
Apply the "blast radius" principle by limiting experiments to specific partitions, topics, or consumer groups. For example, terminate one broker in a three-broker cluster rather than all brokers simultaneously. Gradually increase the scope as you validate resilience.
Automate and Repeat
Manual chaos experiments are valuable for learning, but automated, continuous chaos engineering provides ongoing validation. Tools like Chaos Mesh, Litmus, or custom scripts can inject failures on a schedule, ensuring that resilience is maintained as the system evolves.
Real-World Example: Broker Failure During Peak Load
Consider a streaming pipeline processing financial transactions. The pipeline runs on a Kafka cluster with three brokers, each hosting partition leaders for different topics. The team wants to verify that losing one broker won't cause transaction loss or unacceptable latency.
Experiment setup:
- Define steady state: 99th percentile end-to-end latency < 500ms, zero data loss
- Inject failure: Terminate broker-2 using
kill -9during peak trading hours - Observe behavior: Monitor partition leadership changes, producer retry behavior, consumer lag, and end-to-end latency
Results: The experiment reveals that while Kafka successfully fails over to replica leaders, producer retries cause a 2-second spike in latency because the default retries and retry.backoff.ms settings are too conservative. The team adjusts these configurations and re-runs the experiment, confirming that latency now stays below 600ms even during broker failures.
Observability and Tooling for Chaos Experiments
Successful chaos engineering depends on comprehensive observability. Without visibility into system behavior, it's impossible to determine whether experiments succeed or reveal problems.
Key observability requirements include:
- Metrics collection: Track broker health, partition metrics, consumer lag, throughput, and latency at high resolution
- Distributed tracing: Trace individual messages through the pipeline to identify bottlenecks during failures
- Log aggregation: Centralize logs from all components to correlate failure injection with system responses
Platforms like Conduktor provide centralized visibility into Kafka clusters, making it easier to monitor chaos experiments. Features like real-time consumer lag tracking, cluster health dashboards, and topic inspection help teams quickly identify issues during failure injection. Monitor your chaos experiments and use Conduktor's Insights to track the impact. This observability is essential for understanding the impact of chaos experiments and validating that recovery mechanisms work as expected.
Best Practices and Considerations
When implementing chaos engineering for streaming systems, keep these principles in mind:
- Document runbooks: Create clear runbooks for each experiment, including rollback procedures. This ensures that anyone on the team can safely run or abort experiments.
- Coordinate with stakeholders: Inform downstream teams about planned chaos experiments, especially in production. Unexpected behavior in your streaming pipeline may affect their services.
- Test recovery, not just failure: It's not enough to verify that the system survives a failure. Test how quickly it recovers and whether it returns to the defined steady state.
- Combine with game days: Run coordinated exercises where teams respond to chaos experiments as if they were real incidents. This builds muscle memory for incident response.
- Don't neglect configuration: Many streaming failures result from misconfiguration rather than code bugs. Test configuration changes (like replication factors or retention policies) under failure conditions.
Modern Chaos Engineering Tools (2025)
The chaos engineering tooling landscape has matured significantly:
- Conduktor Gateway: Kafka proxy that enables controlled chaos testing without modifying applications. Inject failures, simulate latency, and test resilience by intercepting and manipulating Kafka traffic at the protocol level. Combines chaos engineering with observability, providing real-time visibility into experiment impact on cluster health and consumer behavior.
- Chaos Mesh: Cloud-native chaos engineering platform for Kubernetes. Supports network chaos, pod failures, I/O chaos, and time chaos. Excellent for testing containerized Kafka and Flink deployments.
- Litmus: CNCF chaos engineering framework with extensive fault injection scenarios. Provides reusable chaos experiments and integrates with CI/CD pipelines for continuous chaos testing.
- AWS Fault Injection Simulator (FIS): Managed service for running chaos experiments on AWS infrastructure. Supports EC2, ECS, EKS, and RDS with built-in experiment templates.
- Azure Chaos Studio: Microsoft's chaos engineering service for Azure resources. Test resilience of AKS clusters, VMs, and managed services with controlled fault injection.
- OpenTelemetry Integration: Modern chaos tools integrate with OpenTelemetry for distributed tracing during experiments, making it easier to understand failure propagation across microservices.
These tools complement custom scripts and provide production-grade chaos experimentation capabilities with safety controls and rollback mechanisms.
Summary
Chaos engineering is essential for building resilient streaming systems. By proactively injecting failures into platforms like Kafka and Flink, teams can discover weaknesses before they cause production outages. Streaming systems are particularly sensitive to failures due to real-time requirements, stateful processing, and distributed coordination.
Start with well-defined experiments in controlled environments, establish clear success metrics, and gradually expand the scope as confidence grows. Combine chaos engineering with strong observability and monitoring to understand system behavior under failure conditions.
Related Concepts
- Testing Strategies for Streaming Applications - Comprehensive testing approaches including chaos testing
- Disaster Recovery Strategies for Kafka Clusters - Planning for and recovering from failures
- Kafka Cluster Monitoring and Metrics - Observability during chaos experiments
Sources and References
- Rosenthal, C., & Hochstein, L. (2017). Chaos Engineering: Building Confidence in System Behavior through Experiments. O'Reilly Media.
- Netflix Technology Blog. (2011). "The Netflix Simian Army." Available at: https://netflixtechblog.com/the-netflix-simian-army-16e57fbab116
- Apache Kafka Documentation. "Kafka Reliability Guarantees." Available at: https://kafka.apache.org/documentation/#design_reliability
- Kreps, J., Narkhede, N., & Rao, J. (2011). "Kafka: A Distributed Messaging System for Log Processing." Proceedings of the NetDB Workshop.
- Garg, N. (2022). "Chaos Engineering for Distributed Systems." Uber Engineering Blog. Available at: https://eng.uber.com/chaos-engineering/