Real-Time ML Inference with Streaming Data
Machine learning inference — the process of making predictions using trained models — traditionally happens in batch mode, processing historical data on fixed schedules. Many modern applications require predictions within milliseconds of receiving new data. Real-time ML inference with streaming data lets organizations act on insights immediately, powering use cases from fraud detection to personalized recommendations. 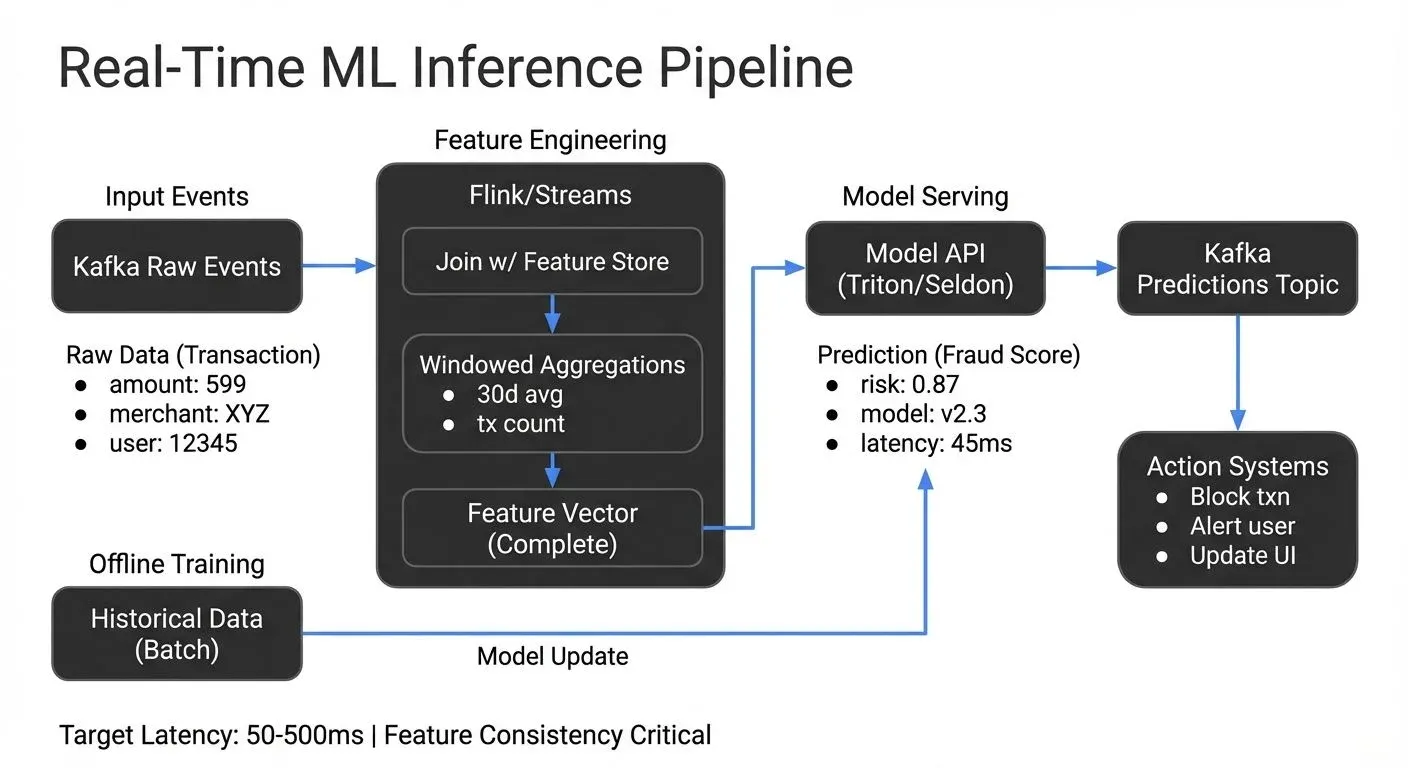
This article explores how streaming platforms enable low-latency ML inference, the architectural patterns that make it possible, and the practical considerations for implementation.
Understanding Real-Time ML Inference
Real-time ML inference means generating predictions as data arrives, rather than waiting to accumulate batches. When a credit card transaction occurs, a fraud detection system must evaluate it instantly, typically within 50-100 milliseconds. When a user clicks on a product, a recommendation engine should update suggestions immediately, usually within 200-500 milliseconds.
The key distinction is latency. Batch inference might process millions of records overnight with latency measured in hours. Real-time inference handles individual events with latency targets ranging from sub-50ms (fraud detection, high-frequency trading) to a few hundred milliseconds (personalized recommendations, dynamic pricing). This shift requires fundamentally different architecture and infrastructure.
For foundational understanding of streaming architectures, see What is Real-Time Data Streaming.
Model inference is separate from model training. Training happens periodically using historical data and significant compute resources. Inference uses the trained model to make predictions on new data with minimal computational overhead. In streaming contexts, inference must be lightweight, fast, and highly available.
Batch vs. Streaming Inference Approaches
Traditional batch inference reads data from databases or data lakes, applies models to large datasets, and writes predictions back to storage. This works well for non-time-sensitive use cases like monthly churn prediction or daily inventory forecasting.
Streaming inference processes events as they flow through a message broker like Apache Kafka. Each event triggers model evaluation, and predictions are published back to the stream for downstream consumers. This approach reduces latency from hours to milliseconds but introduces complexity in state management, fault tolerance, and scalability.
The choice between batch and streaming depends on business requirements. If predictions guide immediate actions, blocking fraudulent transactions, serving personalized content, adjusting prices dynamically, streaming inference is essential. If predictions inform strategic decisions with longer time horizons, batch processing may suffice.
Streaming Architecture for ML Inference
Apache Kafka is the backbone for streaming ML inference. Input events (transactions, clicks, sensor readings) flow into Kafka topics. Inference services consume these events, apply ML models, and publish predictions to output topics. This decoupled architecture allows independent scaling of data ingestion, model serving, and downstream applications. Modern Kafka deployments (2025) use KRaft mode for simplified operations and improved performance, see Understanding KRaft Mode in Kafka for details on the latest architecture.
For comprehensive coverage of Apache Kafka fundamentals, see Apache Kafka.
Apache Flink excels at stateful stream processing, which is crucial for feature engineering. Many ML models require aggregated features, a user's average purchase amount over 30 days, or the standard deviation of sensor readings in the last hour. Flink can compute these features in real-time using windowing and state management, joining streaming data with reference tables to create complete feature vectors for inference. For deep dive into Flink's capabilities, see What is Apache Flink: Stateful Stream Processing. Feature enrichment patterns are covered extensively in Stream Joins and Enrichment Patterns.
Feature stores bridge the gap between offline training and online inference. Systems like Feast, Tecton, Feathr, Featureform, and Hopsworks store pre-computed features that can be retrieved with low latency during inference. Features calculated during training must match those available at inference time, a challenge known as train-serve skew. For example, if you train a fraud model using the last 90 days of transaction history but only compute 30-day aggregates at inference time, your predictions will be inconsistent and less accurate. Feature stores help enforce consistency by serving the exact same feature definitions for both training and inference.
Data quality matters enormously in streaming contexts. Schema validation ensures events match expected formats before inference. Tools like Conduktor can validate schemas, monitor data quality, and alert on anomalies in Kafka streams, preventing corrupted data from reaching ML models and producing unreliable predictions. For schema management best practices, see Schema Registry and Schema Management. To understand the relationship between data quality and observability, see Data Quality vs Data Observability: Key Differences.
Implementation Patterns and Frameworks
There are three primary patterns for deploying ML models in streaming environments:
- Embedded models: The model is deployed directly within the stream processing application (Flink job, Kafka Streams app). This minimizes network latency but couples model updates to application deployments. It works well for lightweight models like decision trees or linear regressions.
- Model serving platforms: Dedicated inference services host models behind APIs. Stream processors call these services over HTTP or gRPC. This separates model lifecycle management from stream processing but adds network overhead. It's ideal for complex models like deep neural networks that require specialized hardware (GPUs).
Popular 2025 serving platforms include:
- NVIDIA Triton Inference Server: Multi-framework support (TensorFlow, PyTorch, ONNX) with GPU optimization
- Ray Serve: Python-native serving with horizontal scaling and composition
- BentoML: ML model serving with built-in deployment automation
- TensorFlow Serving: TensorFlow-specific serving with production-grade features
- Seldon Core/KServe: Kubernetes-native ML deployment with advanced features
- vLLM: High-performance LLM inference engine optimized for throughput
For GPU-intensive models, consider GPU scheduling strategies to maximize utilization. Batch multiple inference requests together for efficiency, or use dynamic batching features available in Triton and vLLM.
- Stream-native ML frameworks: Libraries like Apache Flink ML or River enable training and inference within stream processing frameworks. This approach is emerging for online learning scenarios where models continuously adapt to new data.
- Model Optimization for Inference
Before deploying models in production, optimize them for latency and throughput:
- Quantization: Reduce model precision (FP32 → FP16/INT8) for 2-4x speedup with minimal accuracy loss
- ONNX Runtime: Convert models to ONNX format for cross-framework optimization
- TensorRT: NVIDIA's high-performance deep learning inference optimizer
- Model distillation: Train smaller models that mimic larger ones
- Edge inference: Deploy lightweight models directly on IoT devices for sub-10ms latency
Practical Implementation Example
Here's a Flink job that consumes transaction events from Kafka, enriches them with features, calls a fraud detection model API, and publishes predictions:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// Consume from Kafka
FlinkKafkaConsumer<Transaction> consumer = new FlinkKafkaConsumer<>(
"transactions",
new TransactionDeserializationSchema(),
kafkaProps
);
DataStream<Transaction> transactions = env.addSource(consumer);
// Enrich with features from state or external lookups
DataStream<FeatureVector> enrichedTransactions = transactions
.keyBy(Transaction::getUserId)
.map(new FeatureEnrichmentFunction());
// Call model serving endpoint
DataStream<Prediction> predictions = AsyncDataStream.unorderedWait(
enrichedTransactions,
new AsyncModelInferenceFunction("http://model-service:8080/predict"),
1000, // timeout in milliseconds
TimeUnit.MILLISECONDS,
100 // max concurrent requests
);
// Publish predictions back to Kafka
FlinkKafkaProducer<Prediction> producer = new FlinkKafkaProducer<>(
"predictions",
new PredictionSerializationSchema(),
kafkaProps
);
predictions.addSink(producer);
env.execute("Real-Time Fraud Detection");// Async inference function with error handling
public class AsyncModelInferenceFunction extends RichAsyncFunction<FeatureVector, Prediction> {
private transient HttpClient httpClient;
private final String modelEndpoint;
@Override
public void open(Configuration parameters) {
// Initialize HTTP client with connection pooling
httpClient = HttpClient.newBuilder()
.connectTimeout(Duration.ofMillis(500))
.build();
}
@Override
public void asyncInvoke(FeatureVector features, ResultFuture<Prediction> resultFuture) {
CompletableFuture.supplyAsync(() -> {
try {
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create(modelEndpoint))
.header("Content-Type", "application/json")
.POST(HttpRequest.BodyPublishers.ofString(features.toJson()))
.build();
HttpResponse<String> response = httpClient.send(request,
HttpResponse.BodyHandlers.ofString());
return new Prediction(features.getTransactionId(),
parseResponse(response.body()),
System.currentTimeMillis());
} catch (Exception e) {
// Circuit breaker pattern: after N failures, stop calling service temporarily
// Return default prediction or route to dead letter queue
return new Prediction(features.getTransactionId(), 0.0,
System.currentTimeMillis(), true);
}
}).thenAccept(prediction -> resultFuture.complete(Collections.singleton(prediction)));
}
}Error handling is critical, timeouts, retries, and circuit breakers (which temporarily stop calling failing services after a threshold) prevent cascading failures when model services are slow or unavailable. For testing streaming resilience, see Chaos Engineering for Streaming Systems.
Challenges and Considerations
- Latency requirements drive every architectural decision. Sub-100ms latency demands co-located compute and optimized model formats. Second-scale latency permits more complex features and models. Measuring end-to-end latency, from event arrival to prediction availability, requires comprehensive observability.
- Model versioning and deployment become complex in production. Multiple model versions may run simultaneously for A/B testing or gradual rollouts. Prediction results should include model version metadata for debugging and analysis. Canary deployments (where new models receive 5-10% of traffic initially before full rollout) test models in production with limited risk. Include model version, timestamp, and confidence scores in prediction payloads:
{
"transaction_id": "txn_12345",
"fraud_probability": 0.87,
"model_version": "fraud-detector-v2.3.1",
"inference_timestamp_ms": 1735689600000,
"features_used": ["amount", "merchant_category", "30d_avg_amount"]
}- Feature engineering in real-time is challenging. Some features require historical context (moving averages, trend calculations) that must be computed incrementally. Others need joins with slowly-changing dimension tables. Flink's stateful operators and exactly-once processing guarantees make this feasible but require careful design.
- Monitoring and debugging streaming ML pipelines requires visibility into multiple layers: data quality, feature accuracy, model performance, and system health. Essential metrics include:
- Latency metrics: P50, P95, P99 inference latency (track outliers that impact user experience)
- Throughput: Predictions per second, request queue depth
- Error rates: Timeouts, model failures, malformed input
- Model performance: Prediction distribution, confidence score distribution, accuracy drift
- Model staleness: Time since last model update or training
Tools for observability:
- Prometheus + Grafana: Metrics collection and visualization
- Kafka Lag Exporter: Monitor consumer lag to detect processing delays
- Conduktor: Kafka-specific monitoring, schema validation, data quality checks
- MLflow: Track model versions, performance metrics, and experiment history
- Evidently AI: Monitor ML model quality and data drift in production
When predictions degrade, teams need tools to trace issues through the entire pipeline, from input data quality to model behavior. For comprehensive guidance on building data quality frameworks, see Building a Data Quality Framework.
Real-World Use Cases
- Fraud detection exemplifies real-time ML inference. When a payment transaction occurs, features are extracted (transaction amount, merchant category, user location, recent spending patterns). These features feed a model that outputs a fraud probability within milliseconds. High-risk transactions trigger additional verification or blocking before completion. Companies like PayPal and Stripe process millions of such predictions per second. For detailed architecture patterns, see Real-Time Fraud Detection with Streaming.
- Personalized recommendations use real-time inference to adapt to user behavior. As users browse products or content, their actions stream into Kafka. Models consume this activity to update recommendations dynamically. Netflix and YouTube continuously refine what content to suggest based on viewing patterns, with models updating predictions as users interact with the platform. For implementation guidance, see Building Recommendation Systems with Streaming Data.
- Predictive maintenance in manufacturing monitors sensor data from equipment. Vibration, temperature, and pressure readings stream from industrial IoT devices. ML models detect anomalies or predict failures before they occur, triggering maintenance workflows. This reduces unplanned downtime and extends equipment life. Edge inference is particularly valuable here, deploying lightweight models directly on IoT gateways enables sub-10ms latency even when network connectivity is unreliable.
Summary
Real-time ML inference with streaming data enables organizations to act on insights immediately rather than hours or days later. By integrating ML models with streaming platforms like Apache Kafka and Flink, systems can generate predictions with millisecond latency at massive scale.
Key architectural decisions include choosing between embedded models and dedicated serving platforms (like NVIDIA Triton, Ray Serve, or BentoML), managing feature engineering in stream processors, optimizing models for production (quantization, ONNX, TensorRT), and ensuring robust monitoring throughout the pipeline. Data quality validation, schema management, and comprehensive observability are critical for reliable production systems.
Modern 2025 best practices emphasize:
- Using KRaft-mode Kafka for simplified operations
- Implementing circuit breakers and proper error handling
- Tracking detailed inference metrics (P95/P99 latency, model staleness)
- Including model version metadata in all predictions
- Testing resilience through chaos engineering
- Optimizing models before deployment (quantization, edge inference)
While implementing streaming ML inference introduces complexity in state management, fault tolerance, and monitoring, the business value, preventing fraud in real-time, personalizing user experiences instantly, or predicting equipment failures before they occur, often justifies the investment. As streaming platforms mature and ML frameworks improve, real-time inference is becoming accessible to more organizations.
Related Concepts
- Streaming Data Pipeline - Build robust pipelines for real-time ML inference
- Schema Registry and Schema Management - Ensure data consistency for ML models
- Data Quality Dimensions: Accuracy, Completeness, and Consistency - Quality requirements for ML inputs
Sources and References
- Apache Kafka Documentation - Machine Learning Use Cases - Comprehensive guide to using Kafka as the backbone for ML inference pipelines
- Apache Flink ML Library - Documentation on Flink's machine learning capabilities for stream processing
- NVIDIA Triton Inference Server Documentation - Multi-framework inference serving with GPU optimization (2025 standard)
- Ray Serve Documentation - Python-native scalable model serving framework
- BentoML Documentation - Modern ML model serving with deployment automation
- vLLM: Fast and Easy LLM Inference - High-performance LLM inference engine for 2025 generative AI use cases
- Uber's Michelangelo - Machine Learning Platform - Real-world case study of building production ML systems with streaming inference
- Feature Stores for ML - Feast Documentation - Open-source feature store for managing online and offline features
- ONNX Runtime Performance Optimization - Cross-framework model optimization for production inference
- Evidently AI - ML Monitoring - Monitor ML model quality and data drift in production (2025)