Understanding KRaft Mode in Kafka
Apache Kafka has undergone one of its most significant architectural changes since its inception: the introduction of KRaft mode. This removes Kafka's long-standing dependency on Apache ZooKeeper, replacing it with a native consensus protocol built directly into Kafka.
What is KRaft?
KRaft (Kafka Raft) is Apache Kafka's implementation of the Raft consensus algorithm for managing cluster metadata. Introduced through KIP-500 and declared production-ready in Kafka 3.3.1, KRaft fundamentally changes how Kafka handles critical cluster information like topic configurations, partition assignments, access control lists, and broker metadata.
As of Kafka 4.0 (released in late 2024), ZooKeeper support has been completely removed, making KRaft the only supported mode for all new and upgraded Kafka deployments. After more than two years of production use across thousands of clusters, KRaft has proven itself as a mature, battle-tested architecture.
In traditional Kafka deployments, this metadata lived in ZooKeeper, a separate distributed coordination service. With KRaft, Kafka brokers themselves manage this metadata using a quorum-based approach (where a majority of controllers must agree on changes), eliminating the need for an external dependency.
The name "KRaft" combines "Kafka" with "Raft," the consensus algorithm developed by Diego Ongaro and John Ousterhout at Stanford University. Raft was designed to be more understandable than alternatives like Paxos while providing the same strong consistency guarantees. A consensus algorithm ensures that multiple computers can reliably agree on shared data even when some nodes fail or network partitions occur.
The ZooKeeper Problem
For over a decade, Apache ZooKeeper served as Kafka's metadata store and coordination layer. While this architecture worked, it introduced several operational and technical challenges.
- Operational Complexity: Running a production Kafka cluster meant operating two separate distributed systems, Kafka and ZooKeeper. Each had its own configuration, monitoring requirements, upgrade cycles, and failure modes. Teams needed expertise in both systems, and troubleshooting issues often required understanding complex interactions between them.
- Scalability Limitations: ZooKeeper wasn't designed for Kafka's specific workload patterns. As Kafka clusters grew to support hundreds of thousands of partitions, ZooKeeper became a bottleneck. The metadata size grew, and operations like partition reassignments or leader elections could take minutes instead of seconds.
- Metadata Propagation Delays: In the ZooKeeper model, metadata changes followed a complex path: written to ZooKeeper, then read by the controller, then propagated to other brokers. This multi-hop process introduced latency and created windows where different parts of the cluster had inconsistent views of metadata.
A concrete example: creating a topic with 1,000 partitions in a ZooKeeper-based cluster could take 10-15 seconds as metadata was written to ZooKeeper and then propagated to all brokers. During this window, producers and consumers couldn't reliably interact with the new topic.
How KRaft Works
KRaft replaces ZooKeeper with a Raft-based quorum controller running within Kafka itself. Instead of storing metadata in an external system, KRaft maintains it in a special internal Kafka topic called __cluster_metadata. 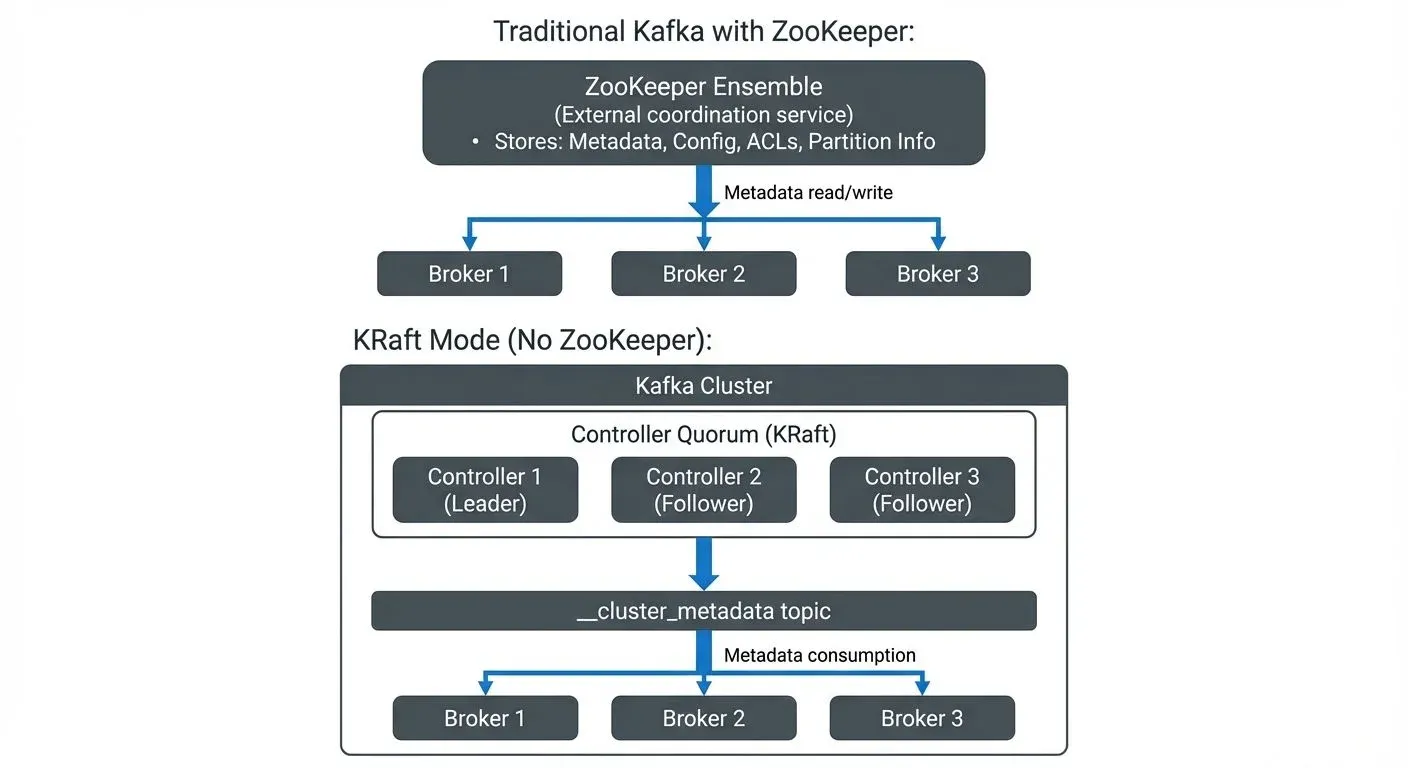
- The Quorum Controller: In a KRaft cluster, a subset of brokers are designated as controllers. These controllers form a Raft quorum, electing one controller as the active leader. The leader handles all metadata changes, appending them to the metadata log. Follower controllers replicate this log to maintain redundancy.
- Event-Driven Metadata: Unlike ZooKeeper's tree-based data structure, KRaft treats metadata as an event log. Every metadata change, creating a topic, changing a configuration, reassigning partitions, becomes an event in the metadata log. Brokers consume this log to build their view of cluster state, similar to how they handle regular Kafka topics.
- Leader Election: When the active controller fails, the remaining controllers use Raft's leader election protocol to choose a new leader automatically. This process typically completes in milliseconds, minimizing the window where metadata changes are unavailable.
Consider the same topic creation example: with KRaft, creating 1,000 partitions takes 1-2 seconds. The metadata change is written once to the metadata log and immediately available to all brokers consuming that log.
Starting Kafka in KRaft Mode
Setting up a KRaft cluster is straightforward. Here's a minimal configuration example for a single-node KRaft broker:
# server.properties for KRaft mode
process.roles=broker,controller
node.id=1
controller.quorum.voters=1@localhost:9093
listeners=PLAINTEXT://localhost:9092,CONTROLLER://localhost:9093
controller.listener.names=CONTROLLER
log.dirs=/var/kafka-logsKey configuration differences from ZooKeeper mode:
process.rolesdefines whether the node acts as a broker, controller, or bothcontroller.quorum.voterslists the controller nodes in the quorumCONTROLLERlistener handles internal controller communication- No
zookeeper.connectproperty required
For production deployments with dedicated controllers, separate the roles and configure a controller quorum with at least three nodes for high availability. For detailed cluster architecture guidance, see Apache Kafka.
Key Benefits of KRaft
The shift to KRaft delivers several tangible improvements for Kafka operations.
- Simplified Architecture: A KRaft cluster is just Kafka. No separate ZooKeeper ensemble to deploy, configure, monitor, or upgrade. This reduces infrastructure footprint and operational overhead. For development environments, you can run a single-node Kafka cluster without any external dependencies.
- Improved Scalability: KRaft supports clusters with millions of partitions, far beyond what was practical with ZooKeeper. The metadata log scales horizontally, and metadata propagation is faster and more efficient. For guidance on planning large-scale deployments, see Kafka Capacity Planning.
- Faster Metadata Operations: Controller failover times drop from seconds to milliseconds. Metadata changes propagate faster because brokers consume the metadata log directly rather than polling ZooKeeper. This improved reliability contributes to overall high availability, for more on resilience patterns, see Kafka Replication and High Availability.
- Better Observability: Since metadata is stored in a Kafka topic, you can use standard Kafka tools to inspect, monitor, and even replay metadata changes. Modern platforms like Conduktor provide specialized KRaft monitoring capabilities, including metadata topic visualization, controller health tracking, and quorum status monitoring, making it easier to understand cluster state and troubleshoot issues.
Migration Considerations
While new Kafka deployments should use KRaft by default, existing ZooKeeper-based clusters require careful migration planning.
- Migration Approaches: Kafka 3.4 through 3.x versions support a bridge mode that allows migration from ZooKeeper to KRaft without downtime. Bridge mode allows both systems to run in parallel temporarily while metadata is transferred, then switches over to KRaft-only mode. Note that Kafka 4.0+ only supports KRaft, so migrations must be completed before upgrading to 4.0.
- Testing Requirements: Before migrating production clusters, thoroughly test in non-production environments. Validate that client applications, monitoring tools, and operational procedures work correctly with KRaft. Some older management tools may not fully support KRaft clusters. For operational best practices during migration, see Kafka Admin Operations and Maintenance.
- Timing: ZooKeeper support was removed in Kafka 4.0 (released late 2024). Organizations still running ZooKeeper-based clusters must complete their migration to KRaft before upgrading to Kafka 4.0 or later versions. This makes migration planning essential for any organization maintaining Kafka 3.x clusters.
- Monitoring During Migration: During the transition, monitor both systems closely. Platforms like Conduktor can help track metadata consistency and identify any discrepancies between ZooKeeper and KRaft views of cluster state, ensuring a smooth migration process. For comprehensive monitoring strategies, see Kafka Cluster Monitoring and Metrics.
KRaft in Data Streaming Ecosystems
KRaft's impact extends beyond Kafka itself, affecting the broader data streaming landscape.
- Stream Processing Frameworks: Tools like Apache Flink, Kafka Streams, and Spark Structured Streaming rely on Kafka for reliable, scalable event streaming. KRaft's improved scalability and faster metadata operations enable larger streaming deployments with more topics, partitions, and consumer groups.
- Infrastructure as Code: KRaft's simplified architecture makes Kafka easier to deploy via infrastructure-as-code tools like Terraform, Kubernetes operators, or Ansible. Fewer components mean simpler deployment templates and less configuration drift. For comprehensive guidance on automating Kafka deployments, see Infrastructure as Code for Kafka Deployments.
- Cloud-Native Deployments: In containerized environments, KRaft reduces resource requirements and simplifies orchestration. Kubernetes-based Kafka deployments benefit from not needing to manage separate ZooKeeper StatefulSets. For Kubernetes-specific deployment patterns, see Running Kafka on Kubernetes and Strimzi Kafka Operator for Kubernetes.
- Ecosystem Tools: The Kafka ecosystem, schema registries, connectors, monitoring tools, continues to work with KRaft clusters. Modern management platforms like Conduktor fully support KRaft with specialized features for controller monitoring, metadata visualization, and cluster governance. Administrators should verify that older or less-maintained tools have been updated to support KRaft mode.
The shift to KRaft aligns Kafka with modern cloud-native and streaming-first architectures.
Related Concepts
- ZooKeeper to KRaft Migration - Step-by-step guide for migrating existing ZooKeeper-based clusters to KRaft mode.
- Kafka Replication and High Availability - KRaft improves failover times and metadata replication for enhanced cluster resilience.
- Kafka Capacity Planning - KRaft's efficiency gains impact infrastructure sizing and resource requirements.
Summary
KRaft mode is a foundational architectural shift in Apache Kafka, replacing ZooKeeper with a native Raft-based consensus protocol. This simplifies operations by eliminating an external dependency, improves scalability to support millions of partitions, and accelerates metadata operations through event-driven architecture.
For new Kafka deployments, KRaft is the only option. For existing ZooKeeper-based clusters, the removal of ZooKeeper in Kafka 4.0 makes migration planning essential. Understanding KRaft's architecture, benefits, and migration paths prepares you to operate Kafka effectively in modern streaming environments.
Sources and References
- Apache Kafka KIP-500: Replace ZooKeeper with a Self-Managed Metadata Quorum
- Apache Kafka Documentation: KRaft Mode
- Confluent Blog: Apache Kafka Made Simple: A First Glimpse of a Kafka Without ZooKeeper
- In Search of an Understandable Consensus Algorithm (Extended Version) - Diego Ongaro and John Ousterhout, Stanford University
- Apache Kafka 3.3.1 Release Notes (KRaft Production-Ready Announcement)