Ingest gRPC Streaming Data into Apache Kafka with Our New Source Connector

gRPC has become the default for service-to-service communication in microservices architectures. But when you need to get those gRPC streams into your Kafka-based data platform, you typically face a choice: write custom client code or build a bridge service. Both mean more code to write, test, deploy, and maintain.
The kafka-connect-grpc source connector is our answer to this. It's an open-source Kafka Connect connector that subscribes to gRPC server streaming endpoints and writes the messages into Kafka topics. No custom code, just configuration.
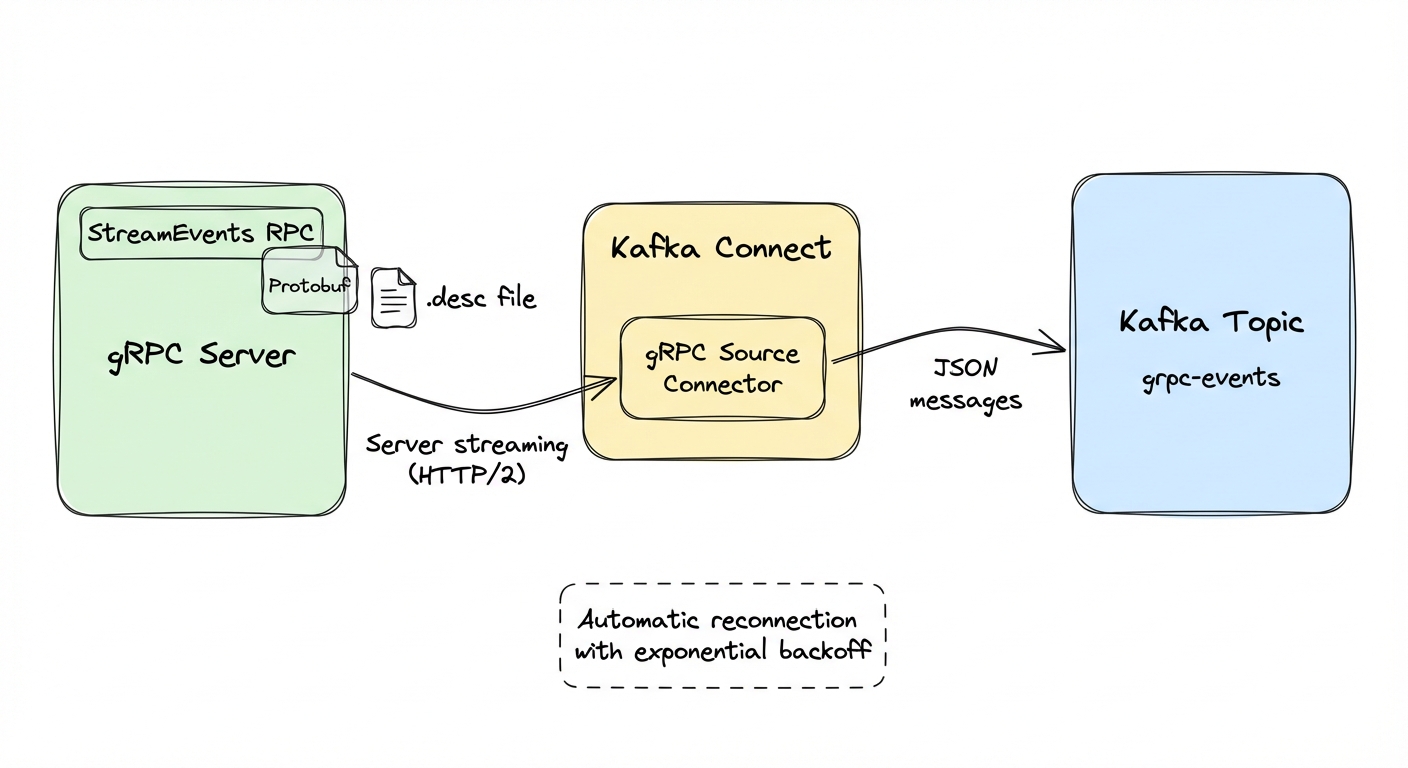
The gRPC-Kafka integration gap
Most architectures have gRPC on one side (services talking to each other with Protocol Buffers over HTTP/2) and Kafka on the other (analytics, event-driven processing, data pipelines). Getting data from one to the other usually means writing a standalone bridge service: a gRPC client that deserializes protobuf messages and produces them to Kafka.
This works, but it's tedious. You handle reconnection logic, monitor the service, manage deployments, and update the code when protobuf schemas change. Each gRPC endpoint you want to ingest needs its own client. Ten streaming endpoints, ten bridge services.
What the connector does
The kafka-connect-grpc source connector plugs gRPC server streaming endpoints into Kafka Connect. You deploy it with a JSON config file. Kafka Connect handles deployment, scaling, monitoring, and failure recovery.
The connector supports:
- Dynamic protobuf handling via descriptor files (no code generation)
- Automatic reconnection with exponential backoff
- TLS and mTLS
- Custom metadata and headers for authentication
- JMX metrics
- Configurable in-memory buffering for backpressure
The connector provides at-most-once delivery. If the in-memory buffer fills or the connector restarts, messages are lost. For use cases requiring guaranteed delivery, have the data source publish to Kafka directly.
Since it runs on Kafka Connect, you also get the Connect REST API, distributed deployment, offset tracking, and integration with tools like Conduktor Console.
Quick start
This takes about 15 minutes. We'll clone the repo, build the connector, run the bundled example with Docker Compose, and see data flowing into Kafka.
Clone and build:
git clone https://github.com/conduktor/kafka-connect-grpc.git
cd kafka-connect-grpc
mvn clean package -DskipTestsNo local Java? Use Docker instead:
docker run --rm -v "$(pwd)":/app -w /app maven:3.9-eclipse-temurin-17 mvn clean package -DskipTestsThe repo includes a ready-to-run example under examples/. It spins up Kafka, Kafka Connect, a Go-based gRPC test server, and auto-deploys the connector -- no manual steps required.
cd examples
docker compose up -dHere's what the example runs. The gRPC test server implements this service definition (from examples/grpc-test-server/stream.proto):
syntax = "proto3";
package teststream;
option go_package = "./;main";
service TestStreamService {
rpc StreamEvents(StreamRequest) returns (stream StreamEvent);
}
message StreamRequest {
string filter = 1;
int32 interval_ms = 2;
}
message StreamEvent {
string event_id = 1;
string timestamp = 2;
string event_type = 3;
string payload = 4;
int64 sequence = 5;
}StreamEvents is a server streaming RPC: the client sends one request, and the server streams events continuously. This is the pattern the connector supports.
Docker Compose brings up six containers: kafka-grpc (Kafka broker), kafka-connect-grpc (Kafka Connect with the connector JAR), grpc-test-server (the Go server above), connector-deploy-grpc (a one-shot container that auto-deploys the connector via curl), postgresql-grpc, and conduktor-console-grpc. The protobuf descriptor file is shared between the gRPC server and Kafka Connect through a Docker volume -- no protoc or docker cp needed on your side.
For reference, here's the connector configuration that gets auto-deployed:
{
"name": "grpc-test-source",
"config": {
"connector.class": "io.conduktor.connect.grpc.GrpcSourceConnector",
"tasks.max": "1",
"grpc.server.host": "grpc-server",
"grpc.server.port": "50051",
"grpc.service.name": "teststream.TestStreamService",
"grpc.method.name": "StreamEvents",
"grpc.request.message": "{\"interval_ms\": 2000}",
"grpc.proto.descriptor": "/opt/kafka/proto/stream.desc",
"kafka.topic": "grpc-events"
}
}After a minute or so, verify the connector is running:
curl http://localhost:8083/connectors/grpc-test-source/statusYou should see "state": "RUNNING" for both the connector and its task.
Now consume messages from Kafka:
docker exec kafka-grpc /opt/kafka/bin/kafka-console-consumer.sh \
--bootstrap-server localhost:9092 \
--topic grpc-events --from-beginning \
--max-messages 5Expected output (event types cycle through user.created, order.placed, payment.processed, item.shipped, user.login):
{"eventId":"evt-...","timestamp":"2026-01-19T12:00:01Z","eventType":"user.created","payload":"{\"userId\":\"user-1\",\"orderId\":\"order-1\",\"amount\":1.99,\"currency\":\"USD\",\"processed\":true}","sequence":"1"}
{"eventId":"evt-...","timestamp":"2026-01-19T12:00:03Z","eventType":"order.placed","payload":"{\"userId\":\"user-2\",\"orderId\":\"order-2\",\"amount\":2.99,\"currency\":\"USD\",\"processed\":true}","sequence":"2"}Events should appear in Kafka every 2 seconds as they stream from the gRPC server. The only thing you configured was JSON -- no custom code.
Messages arrive in order because each connector maintains a single gRPC connection. Events appear in the order the server sent them.
Set tasks.max to 1. A gRPC server streaming RPC is a single persistent connection -- multiple tasks would create duplicate connections. For multiple gRPC streams, deploy separate connector instances.
Protocol Buffers integration
The connector needs to understand your message schema to deserialize streaming responses. Rather than generating Java/Python/Go code (which would couple the connector to your specific schemas), you provide a descriptor file. The connector deserializes messages dynamically at runtime, so the same binary works with any gRPC service.
A descriptor file (.desc) is a compiled representation of your .proto files. Generate one like this:
protoc --descriptor_set_out=service.desc \
--include_imports \
service.protoThe --include_imports flag bundles all dependencies into the descriptor file, making it self-contained.
Two ways to provide the descriptor to the connector:
- File path - mount a volume in Docker containing your .desc files:
"grpc.proto.descriptor": "/opt/descriptors/service.desc"- Base64 encoded - embed the descriptor directly in the configuration:
DESCRIPTOR_B64=$(base64 -w 0 service.desc)"grpc.proto.descriptor": "base64:ABCD123..."The base64 approach works well when deploying via REST API or when you want to avoid managing mounted volumes.
Configuration reference
Required parameters:
| Parameter | Description | Example |
|---|---|---|
grpc.server.host | Hostname or IP of the gRPC server | "api.example.com" |
grpc.server.port | Port number | "443" |
grpc.service.name | Fully qualified service name from .proto | "myapp.v1.EventService" |
grpc.method.name | Server streaming method name | "StreamEvents" |
kafka.topic | Target Kafka topic | "events" |
grpc.request.message (default: {}) The initial request message sent to start the stream. Provide as JSON:
"grpc.request.message": "{\"filter\": \"temperature>20\", \"interval\": 1000}"grpc.proto.descriptor Path to .desc file or base64-encoded descriptor. Required unless your messages use well-known types only.
grpc.metadata Custom metadata headers for authentication or routing:
"grpc.metadata": "api-key:your-key-here,tenant-id:acme-corp"grpc.reconnect.interval.ms (default: 5000) Initial backoff interval before reconnecting after a connection failure. The connector uses exponential backoff internally, doubling the interval on each failed attempt up to a maximum of 5 minutes.
grpc.message.queue.size (default: 10000) Size of the in-memory buffer. If the gRPC server produces faster than Kafka can consume, messages queue here. If the queue fills, messages are dropped (at-most-once semantics).
A production configuration might look like this:
{
"name": "production-grpc-stream",
"config": {
"connector.class": "io.conduktor.connect.grpc.GrpcSourceConnector",
"tasks.max": "1",
"grpc.server.host": "events.prod.example.com",
"grpc.server.port": "443",
"grpc.service.name": "events.v2.EventStream",
"grpc.method.name": "Subscribe",
"kafka.topic": "prod-events",
"grpc.proto.descriptor": "base64:...",
"grpc.request.message": "{\"clientId\": \"kafka-connect\"}",
"grpc.tls.enabled": "true",
"grpc.tls.ca.cert": "/etc/ssl/certs/ca-bundle.crt",
"grpc.metadata": "authorization:Bearer ${env:GRPC_TOKEN}",
"grpc.reconnect.enabled": "true",
"grpc.reconnect.interval.ms": "10000",
"grpc.message.queue.size": "50000"
}
}The ${env:GRPC_TOKEN} syntax is Kafka Connect's environment variable substitution, which keeps secrets out of configuration files.
Use cases
Microservice event streaming. Your order service exposes a gRPC endpoint that streams order state changes. Rather than coupling the service directly to Kafka, it stays infrastructure-agnostic. The connector picks up the stream and writes it to Kafka, where downstream consumers (inventory, notifications, analytics) can each consume independently.
IoT telemetry. Edge gateways aggregate sensor data and expose gRPC streaming endpoints. The connector pulls telemetry into Kafka, feeding Kafka Streams alerting jobs, S3 archival via sink connectors, and KsqlDB materialized views for Grafana dashboards.
Financial market data. Market data providers increasingly offer gRPC streams for quotes, trades, and order book updates. The connector ingests these into Kafka for trading algorithms, compliance recording, and historical analysis. Note the at-most-once delivery caveat here: if you need guaranteed delivery for trade execution, have the data provider publish to Kafka directly.
Internal state synchronization. Services that expose gRPC streaming endpoints for state sync -- inventory levels, session updates, feature flag changes -- can be tapped without modifying the service. The connector subscribes to the existing stream and writes to Kafka for downstream consumers.
TLS and mTLS
Production gRPC services require TLS, and many require mutual TLS for authentication. The connector supports both.
Basic TLS:
{
"grpc.tls.enabled": "true",
"grpc.tls.ca.cert": "/etc/ssl/certs/ca-bundle.crt"
}This validates the server certificate against the provided CA bundle. Most cloud providers and service meshes handle TLS termination at the load balancer, so this is the common case.
Mutual TLS, when the server requires client certificates:
{
"grpc.tls.enabled": "true",
"grpc.tls.ca.cert": "/etc/ssl/certs/ca-bundle.crt",
"grpc.tls.client.cert": "/etc/ssl/certs/client.crt",
"grpc.tls.client.key": "/etc/ssl/private/client.key"
}The connector presents the client certificate during the TLS handshake. Common in zero-trust environments where every connection requires mutual authentication.
For API key or token-based authentication, use custom metadata:
{
"grpc.metadata": "authorization:Bearer eyJhbGc...,x-api-key:your-api-key"
}Multiple metadata headers use the same comma-separated format shown earlier.
These metadata headers are sent with every gRPC request, including the initial streaming call.
Getting started
You need Java 11+ and Maven 3.6+ installed. Clone the repository, build the connector, and run the example:
git clone https://github.com/conduktor/kafka-connect-grpc.git
cd kafka-connect-grpc
mvn clean package -DskipTests
cd examples
docker compose up -dThis launches Kafka, Kafka Connect, a sample gRPC server, and auto-deploys the connector.
For production, download the JAR from GitHub releases:
wget https://github.com/conduktor/kafka-connect-grpc/releases/download/v1.0.0/kafka-connect-grpc-1.0.0.jar
mkdir -p $KAFKA_HOME/plugins/kafka-connect-grpc
cp kafka-connect-grpc-1.0.0.jar $KAFKA_HOME/plugins/kafka-connect-grpc/Full documentation, including installation guides, the complete configuration reference, and schema evolution strategies, is at conduktor.github.io/kafka-connect-grpc.
The connector is open source under the Apache License 2.0. Source code, releases, and issue tracker are at github.com/conduktor/kafka-connect-grpc. If you have a use case that isn't supported or ideas for improvements, open an issue.
You can also ask questions and share feedback in the Conduktor community Slack.