Amazon MSK: Managed Kafka on AWS
Amazon Managed Streaming for Apache Kafka (MSK) is AWS's fully managed service for running Apache Kafka clusters in the cloud. Launched in 2019, MSK removes much of the operational burden of running Kafka while maintaining compatibility with the Apache Kafka ecosystem.
For organizations already running on AWS, MSK provides a straightforward way to adopt event-driven architectures and real-time data pipelines without managing Kafka infrastructure themselves.
What is Amazon MSK?
Amazon MSK is a fully managed service that handles the deployment, configuration, and maintenance of Apache Kafka clusters on AWS infrastructure. It automates provisioning, patching, and scaling while giving you control over Kafka configurations.
MSK runs open-source Apache Kafka, which means applications, tooling, and skills transfer directly. You get standard Kafka APIs and protocols without vendor lock-in at the application layer. AWS handles the underlying infrastructure: compute instances, storage volumes, networking, and availability zone distribution.
The service offers multiple deployment options: MSK Provisioned (traditional instance-based clusters), MSK Provisioned with Express brokers (2024+, optimized for high throughput and rapid scaling), and MSK Serverless (automatic scaling based on demand).
Architecture and Core Components
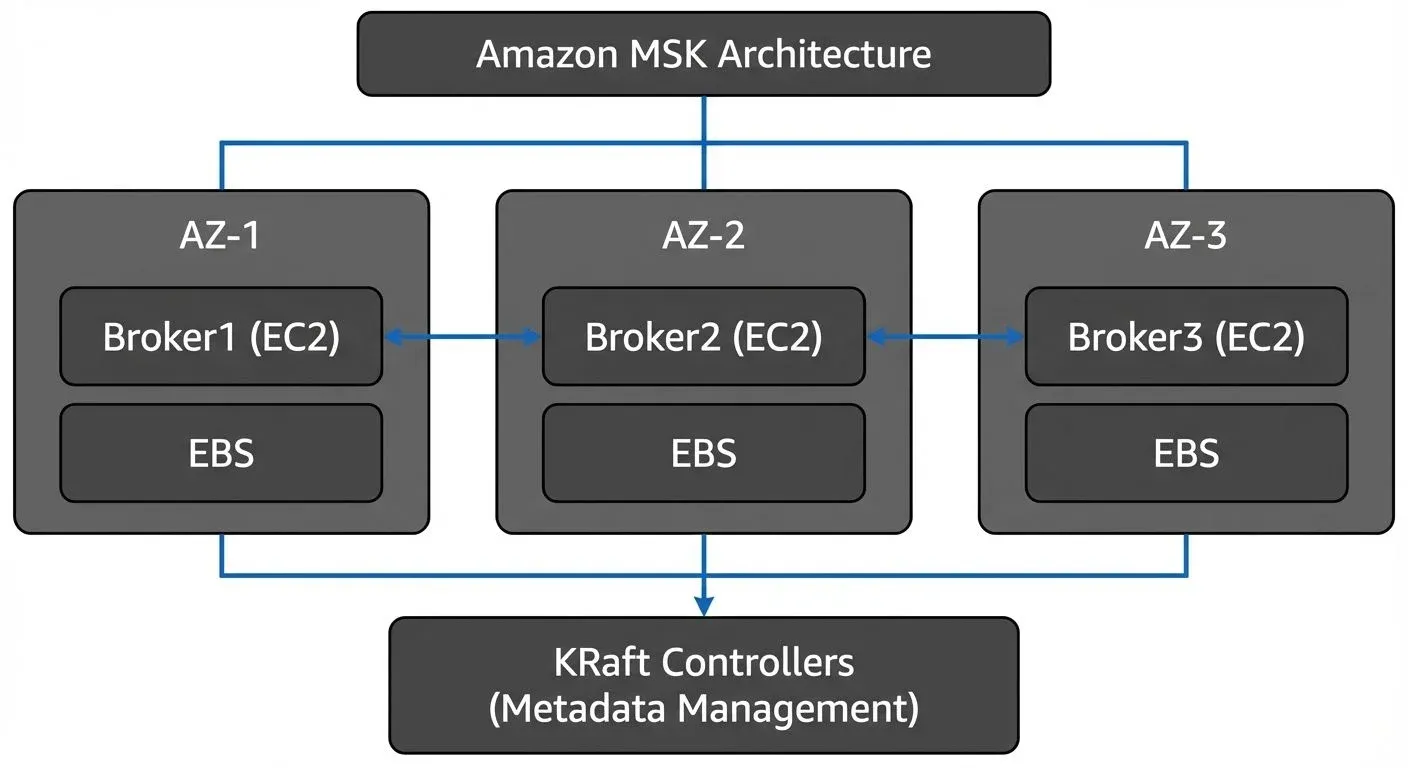
An MSK cluster consists of Apache Kafka brokers distributed across multiple availability zones within an AWS region. AWS manages the underlying EC2 instances, EBS volumes for storage, and KRaft controllers for cluster coordination. As of 2024, MSK supports KRaft mode (Kafka's native consensus protocol), which eliminates the need for ZooKeeper and provides improved scalability and faster metadata operations.
When you create an MSK cluster, you specify:
- The number of broker nodes and their distribution across availability zones
- Instance types (from kafka.m5.large to kafka.m7g.24xlarge for provisioned clusters)
- Storage capacity per broker
- Network configuration (VPC, subnets, security groups)
MSK automatically handles broker replacement if hardware fails, patches software with minimal downtime, and enables automatic minor version upgrades. Multi-AZ deployment ensures high availability: if one availability zone becomes unavailable, the cluster continues operating with replicas in other zones.
For example, a typical production MSK cluster might have six brokers spread across three availability zones (two brokers per zone), using kafka.m5.xlarge instances with 1TB of storage each. This configuration provides both fault tolerance and adequate capacity for moderate-throughput workloads.
MSK Provisioned: Standard vs Express Brokers
As of 2024, AWS offers two types of provisioned brokers with significantly different performance and cost characteristics:
Standard Brokers (Traditional MSK Provisioned)
Standard brokers use EC2 instances with attached EBS volumes. They offer:
- Predictable, instance-based pricing
- Wide range of instance types (kafka.m5.large to kafka.m7g.24xlarge)
- Fixed storage capacity that can be expanded (but not reduced)
- Traditional scaling: add brokers and rebalance partitions manually
Express Brokers (Recommended for 2025+)
- Express brokers represent AWS's optimized Kafka broker architecture, launched in 2024. They provide dramatic improvements over standard brokers:
- Performance Advantages:
- 3x higher throughput per broker compared to standard brokers
- 20x faster scaling: Add or remove capacity in ~5 minutes vs 20-40 minutes for standard brokers
- Unlimited storage: Pay-as-you-go storage model with no pre-provisioning required
- Lower latency: Optimized I/O path reduces p99 latency by 30-40%
Cost Model:
- Per-GB throughput pricing instead of instance hours
- Separate charges for compute, storage, and data transfer
- Generally 20-30% more expensive than standard brokers for steady-state workloads
- More economical for bursty workloads due to elastic capacity
When to Use Express Brokers:
- High-throughput streaming applications (>100 MB/s per broker)
- Variable workloads requiring rapid scaling
- Applications sensitive to rebalancing downtime
- Long retention requirements (unlimited storage reduces storage management overhead)
When to Use Standard Brokers:
- Predictable workloads with steady throughput
- Cost optimization for low-throughput use cases
- Existing clusters without urgent performance needs
- Migration Path: AWS recommends Express brokers for new production clusters. Existing standard broker clusters can migrate using MSK Replicator (see Cross-Region Replication section below) to avoid downtime.
- Example Comparison:
Standard Broker Cluster:
- 6x kafka.m5.xlarge brokers
- 1TB storage per broker
- ~$600/month + data transfer
- Manual scaling: 20-40 minutes
- Throughput: ~50 MB/s per broker
Express Broker Cluster:
- Pay-per-GB throughput
- Unlimited storage (pay for usage)
- ~$750/month for similar throughput
- Elastic scaling: ~5 minutes
- Throughput: ~150 MB/s per brokerKey Features and Capabilities
- Integrated Security: MSK integrates deeply with AWS security services. You can authenticate clients using IAM, TLS certificates, or SASL/SCRAM credentials stored in AWS Secrets Manager. Encryption in transit uses TLS, while encryption at rest uses AWS KMS. Fine-grained access control through IAM policies lets you define who can produce or consume from specific topics.
- Monitoring and Observability: MSK automatically publishes metrics to Amazon CloudWatch, including broker CPU, memory, disk usage, and Kafka-specific metrics like request rates and under-replicated partitions. You can set alarms and create dashboards without additional configuration.
- Storage Tiering: MSK Tiered Storage automatically moves older data from broker storage to Amazon S3, reducing costs while keeping data accessible. This is particularly valuable for workloads requiring long retention periods without paying for expensive broker storage.
- Apache Kafka Compatibility: MSK supports multiple Kafka versions and stays current with Apache Kafka releases. You control when to upgrade, and MSK performs rolling updates that maintain cluster availability.
- Serverless Option: MSK Serverless eliminates capacity planning entirely. It automatically provisions and scales compute and storage resources based on your workload, charging only for the throughput and storage you use.
MSK in the Data Streaming Ecosystem
Amazon MSK is the backbone for real-time data streaming architectures on AWS. It connects naturally with other AWS services: Kinesis Data Analytics for stream processing, Lambda functions for event-driven triggers, S3 for data lake integration, and RDS for change data capture patterns.
- Kafka Connect Integration: MSK works with Kafka Connect for integrating external systems. You can run self-managed Connect clusters or use MSK Connect, a managed service that deploys and scales Kafka Connect workers. Common patterns include streaming database changes using Debezium connectors or moving data to S3 using sink connectors.
- Stream Processing with Apache Flink: MSK pairs well with Amazon Managed Service for Apache Flink (formerly Kinesis Data Analytics) for stateful stream processing. Flink applications can consume from MSK topics, perform complex transformations and aggregations, then write results back to MSK or other sinks.
- Schema Management: While MSK doesn't include a schema registry, you can deploy AWS Glue Schema Registry or third-party registries. Governance platforms provide schema registry capabilities along with data governance and observability features, helping teams manage schema evolution and compatibility across producers and consumers.
- Developer Experience: Managing MSK clusters at scale requires good tooling. While AWS Console provides basic management, governance platforms offer richer interfaces for topic management, consumer group monitoring, message inspection, and data quality enforcement. This becomes especially valuable as organizations scale from a few topics to hundreds or thousands.
Operational Considerations
- Cost Structure: MSK pricing includes broker instance hours, storage costs, and data transfer. A three-broker cluster using kafka.m5.large instances (2 vCPUs, 8 GB memory each) with 500 GB storage per broker costs approximately $500-600/month before data transfer. MSK Serverless can be more economical for variable or unpredictable workloads. For implementing chargeback and cost attribution across MSK clusters to understand per-team and per-topic costs, see Conduktor's Cost Control Insights.
- Scaling: You can scale MSK clusters vertically by changing broker instance types or horizontally by adding brokers. Storage expansion happens online without downtime. However, rebalancing partitions across new brokers requires manual partition reassignment or tools that automate the process.
- Monitoring: Beyond CloudWatch metrics, production deployments benefit from comprehensive monitoring. This includes tracking consumer lag, partition distribution, broker disk usage trends, and data quality issues. Governance platforms can enforce policies on data quality, schema compliance, and access patterns before problems reach production.
- Disaster Recovery and Cross-Region Replication: MSK clusters are regional. AWS provides MSK Replicator, a fully managed cross-region replication service that simplifies multi-region deployments without managing MirrorMaker 2 infrastructure.
MSK Replicator features:
- Automatic replication: Configure source and target MSK clusters; AWS handles replication logic
- Topic filtering: Replicate specific topics or patterns, not entire clusters
- Consumer group offset sync: Enables seamless failover by replicating consumer offsets
- Exactly-once delivery: Prevents duplicate messages during replication
- Monitoring integration: CloudWatch metrics for replication lag and throughput
Use cases:
- Active-passive DR: Replicate production data to standby region for disaster recovery
- Active-active: Bidirectional replication for multi-region writes (requires careful conflict resolution)
- Data aggregation: Replicate from multiple regional clusters to central analytics cluster
- Migration: Zero-downtime migration from standard brokers to Express brokers or between regions
Cost: MSK Replicator charges per GB replicated plus inter-region data transfer fees. Typically adds 20-40% to total MSK costs for DR scenarios.
Conduktor Console Insights: See topic health, costs, and consumer lag in one dashboard. Explore Conduktor Console Insights →
Use Cases and When to Choose MSK
Best Fit Scenarios:
- Organizations already using AWS services extensively
- Teams that want Kafka's ecosystem without managing infrastructure
- Applications requiring event-driven architectures with high throughput
- Microservices needing reliable inter-service communication
- Real-time analytics and data pipeline workloads
- Real-World Example: A financial services company might use MSK to stream transaction events from payment systems to fraud detection services, analytics platforms, and audit logging systems. MSK handles millions of events per day while the team focuses on business logic rather than cluster operations.
- Consider Alternatives When:
- You need maximum control over Kafka internals and hardware tuning
- Your workload is primarily on other cloud providers (consider their managed Kafka offerings)
- You have specialized compliance requirements that preclude managed services
- Your team has deep Kafka operations expertise and wants full control
MSK Serverless works well for development environments, unpredictable traffic patterns, or teams wanting to start small without capacity planning. MSK Provisioned suits production workloads with predictable throughput where you want control over instance types and storage.
Summary
Amazon MSK simplifies running Apache Kafka on AWS by handling infrastructure management, patching, and availability while maintaining compatibility with the Kafka ecosystem. It offers two deployment models: provisioned clusters for predictable workloads and serverless for variable demand.
MSK integrates well with AWS services and the broader streaming ecosystem, supporting Kafka Connect, Apache Flink, and various schema management solutions. Operational aspects like monitoring, scaling, and disaster recovery require planning, though AWS handles much of the infrastructure complexity.
For AWS-focused organizations wanting Kafka without the operational overhead, MSK is a solid foundation for real-time data streaming. Success depends on proper cluster sizing, monitoring, security configuration, and tooling for governance and developer experience.
Related Concepts
- Apache Kafka - The open-source streaming platform that MSK is built on
- Kafka Capacity Planning - Essential for right-sizing MSK clusters and controlling costs
- Streaming Total Cost of Ownership - Understanding the full economic impact of managed Kafka services
Sources and References
- AWS Documentation: Amazon MSK Developer Guide - Official AWS documentation covering architecture, configuration, and best practices.
- Apache Kafka Documentation: Apache Kafka Documentation - Core Kafka concepts and features that MSK implements.
- AWS Blog: Best Practices for Running Apache Kafka on AWS - AWS Big Data Blog with MSK use cases, performance optimization, and architecture patterns.
- AWS Case Studies: Netflix and Amazon MSK - Real-world implementation examples from major MSK users.
- Confluent Platform: Kafka on AWS Best Practices - Kafka ecosystem insights applicable to MSK deployments, including monitoring and operations patterns.