Streaming Total Cost of Ownership: Understanding the Full Picture
When organizations evaluate their streaming infrastructure costs, they often focus solely on their cloud provider bills. The true Total Cost of Ownership (TCO) for streaming platforms like Apache Kafka extends far beyond monthly infrastructure charges. Understanding the complete picture is essential for making informed decisions about architecture, vendor selection, and resource allocation. For foundational knowledge of Apache Kafka architecture, see Apache Kafka. 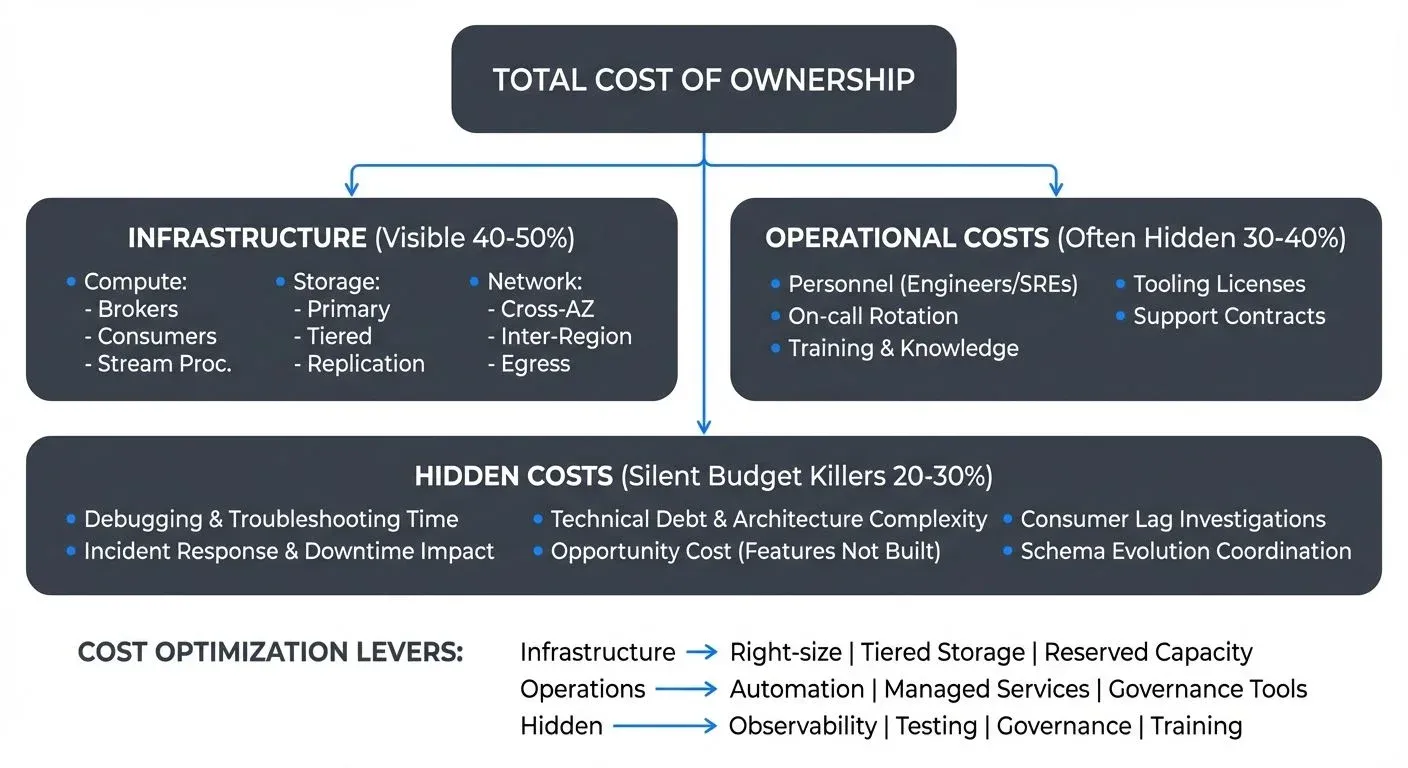
Streaming infrastructure costs are frequently underestimated because many organizations fail to account for operational overhead, opportunity costs, and hidden expenses that accumulate over time. A streaming platform that appears cost-effective based on compute and storage charges alone may prove expensive when factoring in the engineering time required to maintain it, the impact of incidents on business operations, and the complexity debt that slows future development.
The challenge with streaming TCO is that costs are distributed across multiple dimensions: infrastructure resources scale with data volume, operational costs grow with system complexity, and hidden costs emerge from technical decisions made months or years earlier. To optimize your streaming infrastructure effectively, you need visibility into all these cost categories and their relationships.
Infrastructure Costs: The Visible Foundation
Infrastructure costs form the most visible component of streaming TCO, appearing directly on cloud bills or capital expenditure reports. These costs fall into three primary categories that scale differently based on your architecture and workload patterns.
Compute costs represent the processing power required to run your streaming infrastructure. This includes broker nodes that handle message routing and persistence, consumer applications that process streams, and stream processing frameworks like Kafka Streams or Apache Flink. Broker costs typically scale with throughput and partition count, while consumer costs depend on processing complexity and parallelism requirements. Stream processors add another layer, often requiring substantial resources for stateful operations and windowing computations. Organizations running self-managed Kafka might spend 40-60% of their streaming budget on compute resources alone.
With Kafka 4.0's KRaft mode (which eliminates the ZooKeeper dependency), operational costs decrease significantly through simplified cluster management, faster recovery times, and reduced infrastructure overhead. KRaft removes the need for 3-5 dedicated ZooKeeper nodes and their associated operational burden, reducing both compute costs and the engineering time required for maintenance and troubleshooting. For a comprehensive understanding of KRaft's architecture and benefits, see Understanding KRaft Mode in Kafka.
- Storage costs accumulate from multiple sources in streaming architectures. Primary storage holds recent messages based on your retention policy, whether days, weeks, or months. Longer retention directly increases storage costs, with expenses compounded by replication factors (typically 3x for production systems to ensure fault tolerance). Tiered storage solutions can reduce costs by moving older data to object storage like S3, cutting expenses by 80-90% for cold data. Kafka 4.0's production-ready tiered storage (KIP-405) provides improved performance and simpler configuration, making this cost optimization more accessible for organizations of all sizes. For detailed implementation guidance, see Tiered Storage in Kafka. However, cross-region replication for disaster recovery adds substantial storage overhead, effectively multiplying your baseline costs by the number of regions (see Disaster Recovery Strategies for Kafka Clusters for cost-effective DR approaches).
- Network costs are often underestimated but can represent 20-30% of streaming infrastructure expenses. Data ingress is typically free in cloud environments, but egress charges apply when data leaves the cloud provider's network. More significantly, cross-availability-zone (AZ) traffic generates costs even within the same region, problematic for streaming systems where replication inherently requires cross-AZ data transfer. Inter-region replication multiplies these costs further, and organizations with hybrid or multi-cloud architectures face additional egress charges when streaming data between environments. For strategies to minimize these costs, see Cross-AZ Traffic in Streaming.
- Example infrastructure cost breakdown: A medium-sized deployment processing 1TB daily with 7-day retention might incur: $4,000/month for compute (6 broker nodes), $1,200/month for storage (7TB with 3x replication), and $1,800/month for network transfers (cross-AZ replication and consumer egress), totaling approximately $7,000/month in infrastructure costs alone before operational overhead.
Operational Costs: The Human Factor
While infrastructure costs are measurable and predictable, operational costs represent the ongoing human investment required to run streaming platforms successfully. These costs often exceed infrastructure expenses for self-managed deployments.
- Personnel costs encompass the engineers, SREs, and platform teams dedicated to streaming infrastructure. A typical self-managed Kafka deployment requires at least one full-time engineer for every few clusters, with larger organizations maintaining entire teams focused on streaming platform operations. This includes on-call rotations for incident response, capacity planning, version upgrades, and security patching. When you calculate fully-loaded costs (salary, benefits, overhead), even a small team managing streaming infrastructure can cost $500K-$1M annually.
- Tooling and third-party services add another operational layer. Monitoring solutions, observability platforms, schema registries (which centrally manage data formats and ensure compatibility), and governance tools all carry licensing costs. Platforms like Conduktor provide comprehensive management, monitoring, and governance capabilities that significantly reduce operational overhead while improving visibility and control. Organizations might spend $50K-$200K annually on complementary tools for a production streaming platform. While these tools reduce manual operational burden, they represent recurring costs that must be factored into TCO calculations.
- Training and knowledge transfer create less obvious but significant expenses. Streaming platforms require specialized expertise, and onboarding new team members takes months of experienced engineer time. Knowledge silos emerge when only a few people understand the streaming infrastructure deeply, creating risk and slowing development. Documentation, runbooks, and internal training programs require ongoing investment to maintain effectiveness.
Hidden Costs: The Silent Budget Killers
The most expensive aspects of streaming TCO often hide in engineering productivity losses and opportunity costs that never appear on formal budgets.
- Debugging and troubleshooting time consumes substantial engineering resources in streaming systems. Message ordering issues, consumer lag spikes, rebalancing problems, and data quality bugs require deep expertise to diagnose. Engineers might spend days investigating why a consumer group is falling behind or why certain partitions show different behavior. This investigative work doesn't create new features or business value, it merely maintains existing functionality.
- Incident response and downtime impact extends beyond the immediate fix. When a streaming platform experiences issues, downstream systems fail, dashboards go dark, and business processes stall. The cost includes not just the engineering time to resolve incidents but the business impact of delayed data, incomplete analytics, and degraded customer experiences. A single major incident might cost tens of thousands in business value, plus hundreds of engineering hours for resolution and post-mortem work.
- Technical debt and architecture complexity accumulate over time in streaming platforms. Quick fixes become permanent workarounds, special-case logic proliferates, and the system becomes increasingly fragile. Each additional complexity makes future changes slower and riskier. Organizations often underestimate how technical debt in streaming infrastructure slows all data platform development, creating opportunity costs measured in delayed projects and missed business opportunities.
The opportunity cost of engineering time represents perhaps the most significant hidden expense. Every hour engineers spend managing streaming infrastructure is time not spent building customer-facing features, improving data products, or developing new capabilities. For organizations where streaming isn't core to their business model, this represents a substantial drain on technical resources that could create competitive advantages elsewhere.
Cost Drivers and Optimization Strategies
Understanding what drives streaming costs enables targeted optimization strategies that reduce TCO without sacrificing capabilities.
- Key cost drivers include throughput (messages per second), retention period (how long messages are kept), and replication factor (copies of data maintained). Doubling throughput doesn't double costs linearly, it may require additional partitions, more brokers, and increased network capacity. Retention multiplies storage costs directly: keeping data for 30 days costs roughly ten times more than 3-day retention. Replication factor multiplies both storage and network costs, with cross-region replication adding inter-region transfer charges.
- Right-sizing resources provides immediate optimization opportunities. Many organizations overprovision streaming infrastructure based on peak capacity requirements, running oversized brokers during normal load periods. Modern monitoring tools like Kafka Lag Exporter provide detailed visibility into consumer performance and resource utilization (see Consumer Lag Monitoring for comprehensive monitoring strategies). For Kubernetes deployments, the Strimzi operator significantly reduces operational complexity and costs through automated management and scaling capabilities (detailed in Strimzi Kafka Operator for Kubernetes). Analyzing actual partition load distribution often reveals opportunities to consolidate underutilized resources.
- Spot instances and reserved capacity offer significant cloud cost savings. Broker workloads generally run on reserved or savings plan instances for 40-60% discounts, while transient consumer workloads can leverage spot instances for even larger savings. However, spot instances require fault-tolerant architectures since instances can be reclaimed with minimal notice.
- Compaction and data lifecycle management reduce storage costs substantially. Log compaction is particularly valuable for changelog and state topics where only the current state matters, it keeps only the latest value for each key, dramatically reducing storage while preserving the most recent data. Tiered storage moves older segments to object storage, cutting costs by 80-90% for cold data. Automated retention policies prevent unbounded storage growth, and per-topic retention configurations allow fine-grained control based on business requirements.
- Managed vs self-managed comparison reveals striking TCO differences. Managed services like AWS MSK, Azure Event Hubs, or platforms like Conduktor charge premium rates for infrastructure but eliminate operational overhead. For small to medium deployments, managed services often provide lower TCO once operational costs are factored in. Self-managed deployments become cost-effective at larger scales where infrastructure savings outweigh operational costs, typically beyond several terabytes of throughput daily. However, this calculation depends heavily on team expertise and the opportunity cost of engineering time.
Logical Topics: Reducing Infrastructure Costs Through Consolidation
Conduktor's Logical Topics feature reduces partition counts and infrastructure overhead without sacrificing logical organization. Concentrated Topics enable dramatic cost reductions by co-locating multiple logical topics on a single physical topic, for example, 4 regional topics (400 partitions total) consolidate to 100 partitions, reducing infrastructure overhead by 75% while maintaining complete logical separation.
Fewer partitions mean fewer broker resources for replication, reduced metadata overhead, and lower network transfer costs. For organizations paying per-partition pricing in managed Kafka services, this directly translates to proportional cost reduction. Beyond infrastructure savings, fewer partitions also simplify cluster management, enabling faster controller elections and rebalancing operations.
Cost Attribution and Governance
Effective cost management requires visibility into who uses streaming resources and accountability for consumption patterns.
- Per-team and per-topic cost allocation enables data-driven decisions about resource usage. Tagging topics with team ownership, cost centers, and project codes allows attribution of infrastructure costs to consuming teams. Storage costs can be allocated based on topic size and retention, while compute costs distribute based on partition count and throughput. Network costs prove more challenging to attribute but can be estimated from producer and consumer patterns.
- Chargeback models and accountability transform streaming from a free shared resource into a managed service with cost awareness. When teams see actual costs for their streaming usage, they make different decisions about retention, replication, and topic design. Chargeback models range from simple showback (reporting costs without billing) to full chargebacks where teams' budgets are charged for streaming consumption. Even informational cost reporting significantly reduces wasteful usage patterns. For practical implementation of chargeback in Kafka environments, see Conduktor's chargeback documentation which provides strategies for cost attribution and accountability across teams.
- Governance tools for cost control provide automated policy enforcement. Platforms like Conduktor enable organizations to set quotas on topic creation, enforce retention limits, and require approval for high-resource configurations through comprehensive governance policies. Conduktor Gateway adds additional capabilities for testing, chaos engineering, and policy enforcement at the protocol level, helping prevent costly production incidents before they occur. Schema validation prevents inefficient message formats, and topic lifecycle policies archive or delete unused topics automatically. These governance capabilities prevent cost surprises while maintaining developer agility through self-service workflows. For practical chargeback implementation strategies, see Chargeback with Gateway and Chargeback without Gateway. For comprehensive governance implementation including audit trails that support cost attribution, see Audit Logging for Streaming Platforms.
- Setting budgets and alerts provides early warning when streaming costs trend higher than expected. Cloud cost management tools can alert on spending thresholds, while streaming-specific monitoring tracks resource usage patterns. Predictive analytics can forecast costs based on growth trends, enabling proactive capacity planning rather than reactive crisis management.
Building Your TCO Model and Measuring ROI
A comprehensive TCO model for streaming infrastructure encompasses all cost categories and enables informed decision-making.
Creating a comprehensive cost model starts with categorizing expenses: infrastructure (compute, storage, network), operations (personnel, tooling, training), and hidden costs (debugging time, incidents, opportunity cost). Collect baseline data for each category, then model how costs scale with key metrics like daily message volume, topic count, and retention periods. Include both fixed costs (baseline operational overhead) and variable costs (scale with usage).
Track infrastructure costs monthly from cloud bills, breaking down by resource type and usage pattern. Estimate operational costs based on team size and time allocation, survey engineers on how they spend time across streaming operations, feature development, and incident response. Hidden costs require more judgment but can be estimated from incident post-mortems, Jira tickets related to streaming issues, and retrospective analysis of delayed projects.
- Tracking costs over time reveals optimization opportunities and validates architectural decisions. Build dashboards showing TCO trends alongside usage metrics like daily message volume and topic count. This enables you to calculate unit economics, cost per million messages, cost per GB stored, or cost per topic, and track how these metrics evolve as you optimize infrastructure.
- Measuring business value vs cost provides the ROI context for streaming investments. Identify business outcomes enabled by streaming infrastructure: real-time analytics, fraud detection, customer experience improvements, operational efficiency gains. Quantify these benefits where possible, even roughly, to compare against TCO. A streaming platform costing $500K annually might enable $5M in business value through improved customer retention, faster incident detection, or operational automation.
- Making build vs buy decisions becomes clearer with complete TCO models. Compare the fully-loaded cost of self-managed infrastructure (including operations and hidden costs) against managed service pricing. Factor in strategic considerations: does streaming infrastructure represent a core competency and competitive advantage, or is it undifferentiated infrastructure better outsourced to specialists? For most organizations outside the technology sector, managed services provide superior TCO when all costs are considered.
Summary
Understanding the total cost of ownership for streaming infrastructure requires looking beyond infrastructure bills to include operational overhead, hidden costs, and opportunity costs. While compute, storage, and network charges form the visible foundation, personnel costs, debugging time, and the business impact of incidents often exceed infrastructure expenses.
Effective TCO management combines technical optimization — right-sizing resources, tiered storage, managing retention policies — with organizational practices like cost attribution, governance policies, and chargeback models.
The decision between self-managed and managed streaming platforms depends on a complete TCO analysis. Self-managed infrastructure may appear cheaper based on hourly rates, but the operational investment required to run it reliably often tips the equation toward managed services for organizations where streaming is not core to their competitive advantage.
Streaming TCO is not just about minimizing costs — it's about optimizing the ratio of business value to total investment. A more expensive platform that enables faster development and fewer incidents may provide better ROI than a cheaper solution that consumes engineering time and delays strategic work.
Related Concepts
- Streaming Maturity Model - Understanding TCO at different maturity levels
- Infrastructure as Code for Kafka Deployments - Reducing operational costs through automation
- Disaster Recovery Strategies for Kafka Clusters - Balancing DR costs with business requirements
Sources and References
- AWS Pricing - Amazon MSK (Managed Streaming for Apache Kafka). Amazon Web Services. https://aws.amazon.com/msk/pricing/ - Detailed breakdown of managed Kafka infrastructure costs including compute, storage, and data transfer pricing.
- Azure Event Hubs Pricing. Microsoft Azure. https://azure.microsoft.com/en-us/pricing/details/event-hubs/ - Pricing models for managed streaming platforms with detailed cost calculators.
- FinOps Foundation - Cloud Cost Optimization Best Practices. Linux Foundation. https://www.finops.org/framework/capabilities/ - Framework for cloud financial management applicable to streaming infrastructure cost optimization.
- Apache Kafka Documentation - Tiered Storage. Apache Software Foundation, 2025. https://kafka.apache.org/documentation/#tieredstorage - Technical documentation on Kafka's tiered storage capabilities and cost optimization strategies.
- Conduktor Platform Documentation. Conduktor. https://docs.conduktor.io/ - Platform documentation covering governance, monitoring, and cost management for Apache Kafka.
Written by Stéphane Derosiaux · Last updated April 29, 2026