Testing Strategies for Streaming Applications
Testing streaming applications presents challenges that traditional software testing approaches often fail to address. Unlike batch processing or request-response systems, streaming applications operate continuously, process unbounded data, maintain state across time, and handle complex temporal semantics. This article explores testing strategies for building reliable streaming applications on platforms like Apache Kafka, Apache Flink, and Kafka Streams. For foundational understanding of Kafka, see Apache Kafka. 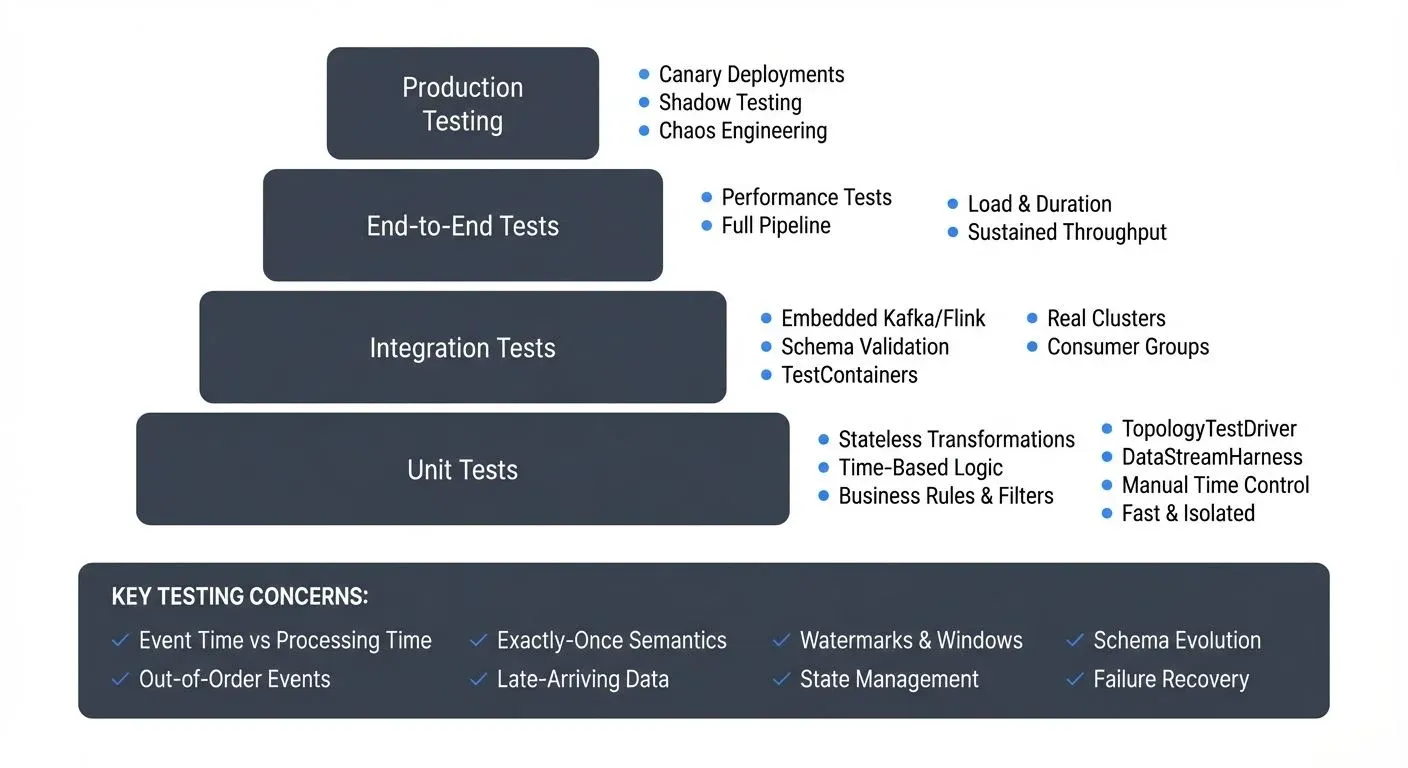
The Testing Challenge in Streaming Systems
Streaming applications differ fundamentally from traditional software in several ways that complicate testing. They process infinite streams of events asynchronously, maintain state that evolves over time, and must handle out-of-order events, late arrivals, and failures gracefully.
Traditional unit tests that verify input-output behavior struggle with the asynchronous nature of stream processing. Integration tests face challenges reproducing timing-dependent bugs. Performance tests must account for sustained throughput over hours or days, not just peak bursts.
The distributed nature of streaming platforms like Kafka adds another layer of complexity. Tests must account for network partitions, broker failures, consumer rebalancing, and exactly-once semantics. For details on exactly-once processing guarantees, see Exactly-Once Semantics in Kafka. A comprehensive testing strategy requires multiple layers, from isolated unit tests to full end-to-end validation.
Unit Testing Stream Processors
Unit testing forms the foundation of any testing strategy. For streaming applications, this means testing individual transformations, filters, and business logic in isolation from the streaming infrastructure.
Most streaming frameworks provide testing utilities for this purpose. Kafka Streams offers the TopologyTestDriver, which allows you to test your stream processing topology without running Kafka brokers. A topology in Kafka Streams is the computational graph defining how data flows from input topics through transformations (filters, maps, aggregations) to output topics. The test driver lets you feed input records, advance time manually, and assert on output records, all in-memory and deterministically.
TopologyTestDriver testDriver = new TopologyTestDriver(topology, config);
TestInputTopic<String, Order> inputTopic =
testDriver.createInputTopic("orders", stringSerde, orderSerde);
TestOutputTopic<String, OrderTotal> outputTopic =
testDriver.createOutputTopic("order-totals", stringSerde, totalSerde);
inputTopic.pipeInput("order-1", new Order(100.0));
OrderTotal result = outputTopic.readValue();
assertEquals(100.0, result.getTotal());Apache Flink (1.18+) provides similar capabilities with MiniCluster for testing complete job graphs (the dataflow execution plan), and utilities like DataStreamTestHarness for testing individual operators. A job graph in Flink represents the logical execution plan of your streaming application, how operators transform data as it flows through the pipeline. The key is to abstract your business logic into pure functions that can be tested independently of the streaming framework. For detailed coverage of Flink's stateful processing model, see What is Apache Flink: Stateful Stream Processing.
Integration Testing with Embedded Clusters
Integration tests validate that your stream processing logic works correctly when deployed to actual streaming infrastructure. However, standing up full production-like environments for every test run is impractical.
Embedded clusters solve this problem by running lightweight versions of Kafka, Flink, or other platforms within your test process. TestContainers has become the standard approach, providing Docker-based Kafka clusters that start in seconds.
@Testcontainers
public class OrderProcessorIT {
@Container
public static KafkaContainer kafka =
new KafkaContainer(DockerImageName.parse("confluentinc/cp-kafka:7.8.0"));
@Test
public void testOrderProcessing() {
// Configure your streaming app to use kafka.getBootstrapServers()
// Send test events, consume results, assert expectations
}
}This approach provides high confidence that your application will work in production while keeping tests fast and isolated. You can test schema evolution (see Schema Registry and Schema Management), serialization, partitioning strategies, and consumer group behavior without external dependencies.
Testing with Kafka 4.0 and KRaft Mode
Kafka 4.0 (released in 2024) eliminated the ZooKeeper dependency in favor of KRaft mode, where Kafka itself manages cluster metadata using the Raft consensus protocol. This architectural change affects testing strategies in several ways. For background on KRaft, see Understanding KRaft Mode in Kafka.
When using TestContainers with Kafka 4.0+, containers start faster and require less memory since a separate consensus service is no longer needed. The KRaft configuration is simpler, but tests should verify:
- Metadata operations: Controller elections, partition leadership, and rebalancing work correctly
- Cluster configuration: Dynamic config updates that are now handled natively by Kafka controllers
- Migration scenarios: If testing upgrades from earlier Kafka versions, validate migration paths
Most integration tests work identically under KRaft, but if your application directly relied on external metadata coordination (a deprecated practice), those integrations will fail and need updating. Modern Kafka clients and admin APIs abstract away these implementation details.
Testing Stateful Operations and State Stores
Many streaming applications maintain state, aggregations, joins, sessionization, and pattern detection all require remembering previous events. Testing stateful operations requires verifying not just correct output, but correct state evolution and recovery from failures.
For Kafka Streams applications, you can inspect state stores directly during testing using the TopologyTestDriver.getKeyValueStore() method. This lets you verify that state is being built correctly over time. For comprehensive coverage of state management, see State Stores in Kafka Streams.
Failure recovery testing is equally important. Your tests should simulate failures, process crashes, network partitions, broker outages, and verify that your application recovers correctly using checkpoints or changelog topics. Flink provides utilities for triggering and recovering from savepoints during tests. For handling backpressure during failures, see Backpressure Handling in Streaming Systems.
Consider testing these scenarios:
- State accumulation over many events
- State size limits and eviction policies
- Recovery from checkpoint or savepoint
- State migration during application upgrades
- Handling corrupted or missing state
Testing Time Semantics and Windows
Time is fundamental to stream processing but notoriously difficult to test. Most streaming applications use event time (the timestamp when events occurred) rather than processing time (when they're processed), with watermarks tracking progress through the event timeline. Watermarks are special markers that flow through the data stream, indicating that no events with timestamps earlier than the watermark should be expected, allowing the system to safely close windows and emit results. Windowed operations, tumbling, sliding, and session windows, depend critically on correct time handling. For a comprehensive explanation of watermarks, see Watermarks and Triggers in Stream Processing.
The key to testing time-based operations is controlling time explicitly. Kafka Streams' TopologyTestDriver allows you to advance time manually, simulating hours of processing in milliseconds of test execution.
// Simulate events arriving over a 10-minute window
testDriver.advanceWallClockTime(Duration.ofMinutes(1));
inputTopic.pipeInput("key1", event1, timestamp1);
testDriver.advanceWallClockTime(Duration.ofMinutes(2));
inputTopic.pipeInput("key1", event2, timestamp2);
// Advance past window close and grace period
testDriver.advanceWallClockTime(Duration.ofMinutes(10));
// Assert on windowed aggregation resultsTest late arrivals, out-of-order events, and watermark advancement. Verify that windows close at the correct time and that late data is handled according to your application's policy (discard, side output, or include).
Data Quality Testing for Streaming Pipelines
Beyond functional correctness, streaming applications must maintain data quality, ensuring completeness, accuracy, consistency, and timeliness. Data quality issues often manifest as silent failures: missing records, incorrect transformations, schema drift, or duplicate events that pass functional tests but corrupt downstream analytics.
Modern data quality frameworks like Great Expectations and Soda Core can integrate with streaming test pipelines. These tools allow you to define expectations about your data (value ranges, null rates, schema compliance, uniqueness constraints) and validate them continuously.
For streaming applications, data quality tests should validate:
- Completeness: All expected events arrive (no data loss during processing)
- Timeliness: Events are processed within acceptable latency bounds
- Schema compliance: Output data matches expected schemas and contracts
- Business rules: Domain-specific constraints (e.g., order totals are non-negative)
- Duplicate detection: Exactly-once semantics are maintained
You can run these tests in multiple ways: as part of integration tests using TestContainers, as shadow tests comparing production and test outputs, or as continuous monitors in production. For comprehensive coverage of data quality testing, see Automated Data Quality Testing and Great Expectations Data Testing Framework.
Consider implementing data contracts between producers and consumers that codify quality expectations. When tests detect violations, they can route problematic records to dead letter queues for investigation. For error handling patterns, see Dead Letter Queues for Error Handling.
Performance and Load Testing
Functional correctness is necessary but not sufficient. Streaming applications must meet throughput and latency requirements under sustained load. Performance testing for streaming differs from traditional load testing in important ways.
First, tests must run long enough to reach steady state. Many issues, memory leaks, state bloat, resource exhaustion, only appear after hours or days of processing. Short burst tests miss these problems.
Second, you need to test realistic event patterns, not just uniform load. Real streams have spikes, lulls, and correlations. Tools like kafka-producer-perf-test can generate load, but often custom producers that replay production patterns or generate realistic synthetic data provide more valuable insights.
Key metrics to track:
- End-to-end latency (event production to final output)
- Processing lag (how far behind real-time)
- Throughput (events per second)
- State size growth over time
- Resource utilization (CPU, memory, network)
Dedicated testing platforms like Conduktor provide tools to generate realistic test data, monitor cluster health, and validate data quality at scale.
Chaos Engineering for Streaming Applications
Chaos engineering, deliberately injecting failures to validate system resilience, is crucial for streaming applications that must handle network partitions, broker failures, and unexpected load spikes. Traditional testing often misses how applications behave under real-world failure conditions.
Modern tools like Conduktor Gateway enable proxy-based chaos testing for Kafka applications. As a transparent proxy sitting between applications and Kafka clusters, Gateway can inject faults without modifying application code:
- Network failures: Simulate broker unreachability, network partitions, or high latency
- Message corruption: Test schema validation and error handling
- Throttling and backpressure: Validate rate limiting and flow control
- Rebalancing simulation: Test consumer group behavior under controlled rebalancing scenarios
For example, you might test how your application handles a broker becoming unavailable during peak load, or how consumers recover from a rebalance when processing a backlog of events. These scenarios are difficult to reproduce reliably without specialized tooling.
Chaos testing should be part of your CI/CD pipeline for critical streaming applications, with automated tests that inject failures and verify recovery within acceptable time bounds. For comprehensive coverage of chaos engineering patterns, see Chaos Engineering for Streaming Systems.
Testing in Production and Observability
Even comprehensive pre-production testing cannot catch every issue. The complexity and scale of production environments means some bugs only appear in the wild. This has led to "testing in production" practices that allow safe validation with real traffic.
Shadow testing runs new versions of your application in parallel with production, consuming the same events but writing to separate output topics. You can compare results between versions to catch regressions before they affect users.
Canary deployments gradually roll out changes to small percentages of traffic while monitoring key metrics. If error rates or latency degrade, you can roll back before widespread impact.
Effective observability is essential for both testing strategies. Instrument your applications to emit metrics, traces, and logs that help you understand behavior. For Kafka applications, this includes consumer lag (monitored with tools like Kafka Lag Exporter), processing time per record, exception rates, and state store sizes. Modern observability platforms using OpenTelemetry provide distributed tracing that tracks individual events through complex streaming pipelines. For details on distributed tracing, see Distributed Tracing for Kafka Applications.
Platforms like Conduktor provide real-time monitoring, data quality validation, and governance that helps teams detect issues quickly in production environments. Schema validation, audit logging of client connections, and anomaly detection can catch problems that traditional testing misses. For understanding consumer lag monitoring patterns, see Consumer Lag Monitoring.
Best Practices and Tooling
A comprehensive testing strategy for streaming applications combines multiple approaches:
- Test pyramid: Many fast unit tests, fewer integration tests, minimal end-to-end tests
- Deterministic testing: Control time, ordering, and failures explicitly
- Property-based testing: Use frameworks like QuickCheck or Hypothesis to generate random event sequences and verify that invariants hold across arbitrary inputs. For streaming applications, this might mean generating random event orderings, timestamps, or failure scenarios to discover edge cases that hand-written tests miss
- Continuous testing: Run long-duration tests to catch slow memory leaks or state growth
- Production validation: Shadow testing and canary deployments with strong observability
The streaming ecosystem provides excellent tooling:
- TopologyTestDriver (Kafka Streams) and DataStreamTestHarness (Flink) for unit tests
- TestContainers for integration tests with real clusters
- Gatling or custom producers for performance testing
- Kafka's testing utilities like
MockProducerandMockConsumer - Schema validation tools to validate schema evolution
- Conduktor for comprehensive testing, monitoring, and chaos engineering
- Kafka Lag Exporter for consumer lag monitoring in test and production environments
- Great Expectations and Soda Core for data quality validation
Remember that testing streaming applications requires patience and rigor. Invest in good testing infrastructure early, it pays dividends as applications grow in complexity. For CI/CD integration, see CI/CD Best Practices for Streaming Applications.
Summary
Testing streaming applications requires adapting traditional software testing practices to handle asynchronous processing, unbounded data, stateful operations, and complex time semantics. A layered approach combining unit tests, integration tests with embedded clusters, stateful and temporal testing, performance validation, and production monitoring provides confidence in application correctness and reliability.
The key is controlling the non-deterministic aspects of streaming — time, ordering, failures — to create reproducible tests. Modern streaming frameworks provide solid testing utilities, and tools like TestContainers make integration testing practical. Combined with observability and production testing techniques, teams can build reliable streaming applications that handle real-world complexity.
Related Concepts
- CI/CD Best Practices for Streaming Applications - Integrating testing into deployment pipelines
- Chaos Engineering for Streaming Systems - Testing resilience through controlled failures
- Data Quality Dimensions: Accuracy, Completeness, and Consistency - Understanding what to test for in streaming data
Sources and References
- Confluent Documentation: "Testing Kafka Streams" - https://docs.confluent.io/platform/current/streams/developer-guide/testing.html
- Apache Flink Documentation: "Testing" - https://nightlies.apache.org/flink/flink-docs-stable/docs/dev/datastream/testing/
- Kleppmann, Martin. "Designing Data-Intensive Applications" - Chapter 11: Stream Processing (O'Reilly Media, 2017)
- TestContainers Documentation: "Kafka Module" - https://www.testcontainers.org/modules/kafka/
- Narkhede, Neha et al. "Kafka: The Definitive Guide" - Chapter 7: Building Data Pipelines (O'Reilly Media, 2017)