Kafka Log Compaction Explained
Apache Kafka is widely known for its ability to retain message streams for extended periods. While most users are familiar with time-based or size-based retention policies, Kafka offers a powerful alternative called log compaction. This retention mechanism serves a fundamentally different purpose: maintaining the latest state of each record rather than preserving a complete historical timeline. 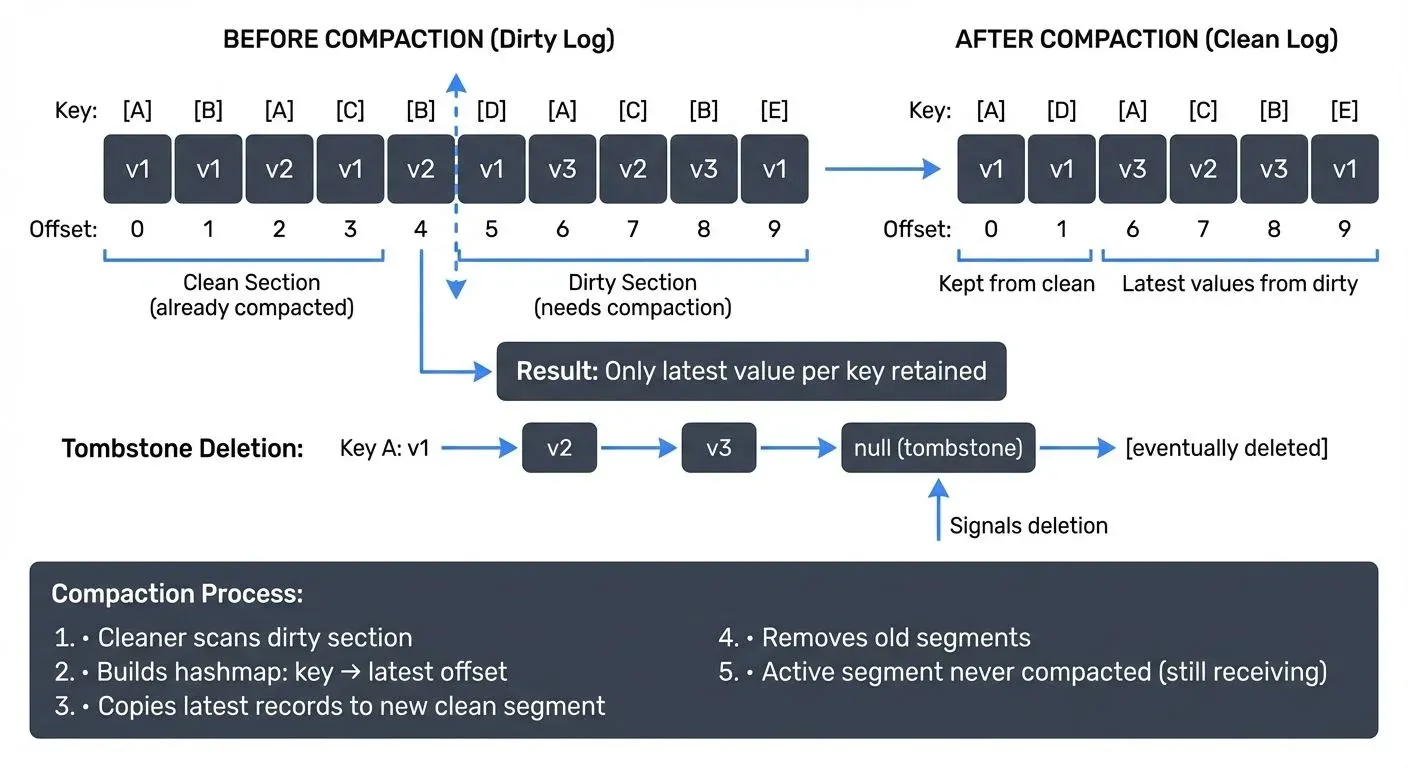
What is Kafka Log Compaction?
Log compaction is a retention policy that ensures a Kafka topic retains at least the last known value for each message key within a partition. Unlike standard deletion-based retention (which removes old data after a specified time or when a size limit is reached), compaction keeps the most recent update for each key indefinitely.
For foundational understanding of Kafka's architecture including topics, partitions, and brokers, see Kafka Topics, Partitions, and Brokers: Core Architecture.
This approach transforms a Kafka topic from an append-only log of events into something closer to a table of current states. However, the log structure remains intact, compaction doesn't remove messages immediately, and it preserves message offsets so consumers can still track their position reliably.
A critical feature of log compaction is support for tombstone records. When a message with a null value is published for a given key, it signals that the key should be deleted. The compaction process will eventually remove both the tombstone and all previous messages for that key.
How Log Compaction Works
Kafka partitions are divided into segments, immutable files that contain a portion of the log. Each segment typically contains a time-bounded or size-bounded chunk of messages, allowing Kafka to manage, compact, and delete data efficiently. Log compaction operates on these segments using a background cleaner thread.
Log compaction works identically in both legacy ZooKeeper-based Kafka and modern KRaft mode (Kafka 4.0+). The compaction process is entirely broker-side and doesn't depend on the metadata management layer, making it a reliable feature across all Kafka deployment modes.
The log is conceptually split into two sections:
- Clean section: Segments that have already been compacted, containing only the most recent value for each key
- Dirty section: Segments containing potentially duplicate keys that haven't been compacted yet
The cleaner thread periodically scans the dirty section, builds a hash map of the latest offset for each key, and creates new clean segments containing only the most recent records. The old segments are then deleted.
Several configuration parameters control when compaction runs:
min.cleanable.dirty.ratio: The minimum ratio of dirty records to total records before compaction triggers (default 0.5)segment.ms: How long before a segment becomes eligible for compactionmin.compaction.lag.ms: Minimum time a message remains uncompacted, ensuring recent messages stay available
Importantly, the active segment (currently being written to) is never compacted, ensuring new data is immediately available to consumers.
Log Compaction vs Time-Based Retention
Standard Kafka topics use deletion-based retention, configured with retention.ms or retention.bytes. Messages older than the retention period are deleted regardless of their content.
Log compaction, enabled with cleanup.policy=compact, takes a different approach. It retains messages based on key uniqueness rather than age. This means:
- Time-based retention: Appropriate for event streams where historical order matters (clickstreams, logs, audit trails)
- Log compaction: Appropriate for state or entity updates where only the current value matters (user profiles, product catalogs, configuration data)
You can also combine both policies with cleanup.policy=compact,delete, which compacts the log while also removing old segments that exceed retention limits.
Common Use Cases
Log compaction enables several important patterns in data streaming:
Change Data Capture (CDC)
When capturing database changes into Kafka, each message represents a row update keyed by the primary key. Log compaction ensures the topic always contains the latest state of each row without storing the complete change history indefinitely.
For a comprehensive introduction to CDC patterns and implementation strategies, see What is Change Data Capture (CDC) Fundamentals.
For example, consider a users table synced to Kafka:
Key: user_123 | Value: {"name": "Alice", "email": "alice@example.com", "updated_at": "2025-01-15"}
Key: user_123 | Value: {"name": "Alice", "email": "alice@newmail.com", "updated_at": "2025-02-20"}
Key: user_123 | Value: {"name": "Alice Smith", "email": "alice@newmail.com", "updated_at": "2025-03-10"}After compaction, only the final record remains, representing the current state of user_123.
State Stores and Materialized Views
Applications that build local state from Kafka topics benefit from compaction. When restarting or rebalancing, they can rebuild state by consuming only the latest value for each key rather than processing the entire history.
Configuration Management
Distributed systems often use compacted topics to share configuration across services. Each configuration key holds its current value, and services can reconstruct the full configuration by reading the compacted topic.
For broader guidance on designing topics for different use cases, including configuration management, see Kafka Topic Design Guidelines.
Configuring Log Compaction
To enable log compaction on a topic, set the cleanup policy:
# Using kafka-configs.sh
kafka-configs.sh --bootstrap-server localhost:9092 \
--entity-type topics \
--entity-name my-compacted-topic \
--alter \
--add-config cleanup.policy=compact
# Or specify during topic creation
kafka-topics.sh --bootstrap-server localhost:9092 \
--create \
--topic my-compacted-topic \
--partitions 3 \
--replication-factor 3 \
--config cleanup.policy=compact \
--config min.cleanable.dirty.ratio=0.5Additional important configurations include:
min.cleanable.dirty.ratio: Controls compaction frequency (lower values mean more frequent compaction but higher resource usage). Default is 0.5, meaning compaction triggers when 50% of the log contains duplicate keys.delete.retention.ms: How long tombstone records are retained before final deletion (default 24 hours)max.compaction.lag.ms: Maximum time before a message must be compactedsegment.msandsegment.bytes: Control segment size and rotation, affecting compaction granularity
It's important to understand that compaction is not immediate. Messages remain in the log until the cleaner thread runs and processes the segments containing them.
Log Compaction and Tiered Storage
Kafka 3.6+ introduced tiered storage, which allows older log segments to be moved to cheaper object storage (S3, GCS, Azure Blob) while keeping recent data on local broker disks. Understanding how log compaction interacts with tiered storage is critical for 2025 deployments.
Key behaviors with tiered storage enabled:
- Compaction only applies to local segments: The cleaner thread only compacts segments stored on broker disks, not segments that have been moved to remote storage
- Remote segments remain uncompacted: Once a segment is uploaded to tiered storage, it retains all its original messages (including duplicates) indefinitely
- Implications for state reconstruction: When rebuilding state from a compacted topic with tiered storage, consumers may need to read and deduplicate remote segments, potentially increasing recovery time
Best practices for compacted topics with tiered storage:
- Adjust local retention: Set
local.retention.mshigh enough to ensure adequate compaction before segments are moved to remote storage - Monitor compaction lag: Track the dirty ratio and ensure segments are compacted before tiering
- Consider compaction-only policies: For true state store topics, use
cleanup.policy=compactwithout tiered storage, or use very high local retention thresholds
For detailed coverage of tiered storage architecture and configuration, see Tiered Storage in Kafka.
Log Compaction in Data Streaming Architectures
Log compaction plays a crucial role in stateful stream processing frameworks like Kafka Streams and Apache Flink.
KTables and Compacted Topics
In Kafka Streams, a KTable represents a changelog stream where each record is an update to a keyed state. KTables are fundamentally backed by compacted topics, the abstraction directly maps to log compaction semantics:
// KTable automatically interprets the compacted topic as a table
StreamsBuilder builder = new StreamsBuilder();
KTable<String, User> usersTable = builder.table(
"users-compacted", // Must be a compacted topic
Consumed.with(Serdes.String(), userSerde)
);
// Updates to the KTable produce to a compacted changelog
usersTable
.filter((key, user) -> user.isActive())
.toStream()
.to("active-users-compacted"); // Also compactedWhen you materialize a KTable with operations like aggregations or joins, Kafka Streams automatically creates compacted changelog topics to back the state stores. For example:
KTable<String, Long> orderCounts = ordersStream
.groupByKey()
.count(Materialized.as("order-counts-store"));
// Creates compacted topic: app-id-order-counts-store-changelogState Store Recovery with Compacted Topics
Kafka Streams uses compacted changelog topics to back state stores. When a stream processing application updates local state (such as an aggregation or join table), it writes changes to a compacted topic. If the application fails or restarts, it can rebuild its state by consuming this topic. Since the topic is compacted, restoration is faster, only the latest value for each key needs to be processed.
This pattern enables exactly-once processing semantics (EOS) and fault-tolerant stateful operations without requiring external databases. The compacted topic serves as both a changelog and a source of truth for application state.
Example: Tombstone deletion in Kafka Streams
// Deleting from a KTable produces a tombstone to the compacted topic
usersTable
.toStream()
.filter((key, user) -> user.shouldDelete())
.mapValues(user -> null) // Produces tombstone (null value)
.to("users-compacted"); // Eventually removes the key entirelyFor detailed coverage of state store architecture and recovery mechanisms, see State Stores in Kafka Streams.
Event Sourcing and Materialized Views
Event sourcing architectures also use log compaction. While the complete event history might be preserved in one topic, a compacted topic can maintain the current projection or materialized view derived from those events. This pattern is common in CQRS (Command Query Responsibility Segregation) architectures where read models are built from event streams.
For comparing stream processing frameworks and their approaches to state management, see Kafka Streams vs Apache Flink.
Monitoring and Troubleshooting
Monitoring log compaction is essential to ensure it's working correctly and not falling behind.
Key JMX Metrics
Important JMX metrics to track:
kafka.log.LogCleanerManager.max-dirty-percent: Shows how much of the log is dirty and eligible for compactionkafka.log.LogCleaner.cleaner-recopy-percent: Indicates compaction efficiency (lower is better)kafka.log.LogCleaner.max-compaction-delay-secs: Maximum time any partition waited for compactionkafka.server.BrokerTopicMetrics.TotalProduceRequestsPerSec: Helps correlate compaction lag with write throughput- Segment count and size per partition
Modern Monitoring with Conduktor
In 2025, managing compaction across multiple clusters and environments is significantly easier with platforms like Conduktor. Conduktor provides:
- Visual topic configuration inspection: Quickly identify which topics have
cleanup.policy=compactacross all clusters - Real-time compaction metrics: Dashboard views of dirty ratios, cleaner lag, and segment statistics without manually querying JMX
- Alerting on compaction issues: Get notified when dirty ratios exceed thresholds or compaction falls behind
- Configuration management: Easily adjust compaction parameters (
min.cleanable.dirty.ratio,max.compaction.lag.ms) through the UI with validation - Data inspection: Browse compacted topics to verify latest values and identify tombstone records
Conduktor Gateway, a Kafka proxy, also enables testing compaction behavior in development environments by introducing controlled delays or failures in the compaction process.
For comprehensive monitoring strategies across your Kafka infrastructure, see Kafka Cluster Monitoring and Metrics.
Common Issues
Frequent compaction problems and their solutions:
- Compaction lag: If the dirty ratio stays high, compaction may not be keeping up. Increase cleaner threads (
log.cleaner.threads) or adjustmin.cleanable.dirty.ratioto trigger compaction more aggressively - Missing keys: Messages without keys cannot be compacted, they're retained until time/size-based deletion. Ensure all messages include keys when using compacted topics
- Unexpected deletion: Check for tombstone records (null values) if data disappears unexpectedly. Review producer code for accidental null value writes
- Slow state restoration: With tiered storage enabled, verify that adequate local retention allows compaction before segments move to remote storage
Related Concepts
- Kafka Topic Design Guidelines - Guidance on choosing between compaction, time-based retention, and hybrid retention policies for different use cases.
- Introduction to Kafka Streams - Kafka Streams relies heavily on compacted topics for maintaining state stores and changelog topics.
- Tiered Storage in Kafka - Understanding how compaction interacts with tiered storage is critical for modern Kafka deployments.
Summary
Kafka log compaction is a powerful retention mechanism that maintains the latest state for each message key rather than preserving a complete time-ordered history. It transforms Kafka topics into durable, fault-tolerant state stores that support use cases like change data capture, configuration management, and stateful stream processing.
Understanding the mechanics of compaction, how the cleaner thread operates on segments, when compaction triggers, and how tombstones enable deletion, is essential for using this feature effectively. While compaction isn't appropriate for all use cases, it's invaluable when you need a distributed, scalable way to maintain current state in a data streaming architecture.
By configuring compaction correctly and monitoring its performance, you can use Kafka not just as a message broker but as a reliable state management layer.
Sources and References
- Apache Kafka Documentation: Log Compaction - Official Kafka documentation detailing compaction mechanics and configuration
- Confluent: Log Compaction Highlights - In-depth explanation of how log compaction works under the hood
- Narkhede, N., Shapira, G., & Palino, T. (2017). Kafka: The Definitive Guide. O'Reilly Media. - Comprehensive book covering Kafka internals including log compaction
- Kleppmann, M. (2017). Designing Data-Intensive Applications. O'Reilly Media. - Context on event sourcing and state management patterns
- Kafka Streams Documentation: State Stores - How Kafka Streams uses compacted topics for state management