Infrastructure as Code for Kafka Deployments
Managing Apache Kafka deployments at scale presents unique challenges. Unlike stateless applications, Kafka requires careful orchestration of brokers, persistent storage, network configurations, and numerous operational resources like topics, ACLs, and connectors. Infrastructure as Code (IaC) has emerged as a critical practice for teams seeking to deploy Kafka reliably across multiple environments while maintaining consistency and reducing human error.
What is Infrastructure as Code?
Infrastructure as Code is the practice of managing and provisioning infrastructure through machine-readable definition files rather than manual configuration or interactive tools. Instead of clicking through cloud consoles or running ad-hoc commands, teams define their desired infrastructure state in code that can be version-controlled, reviewed, and automatically applied.
The benefits extend beyond automation. IaC provides documentation as code, your infrastructure definitions become the source of truth for how systems are configured. Changes go through the same review processes as application code, creating an audit trail and enabling rollbacks when issues arise. For distributed systems like Kafka, where configuration drift can lead to subtle but serious problems, this consistency is invaluable. 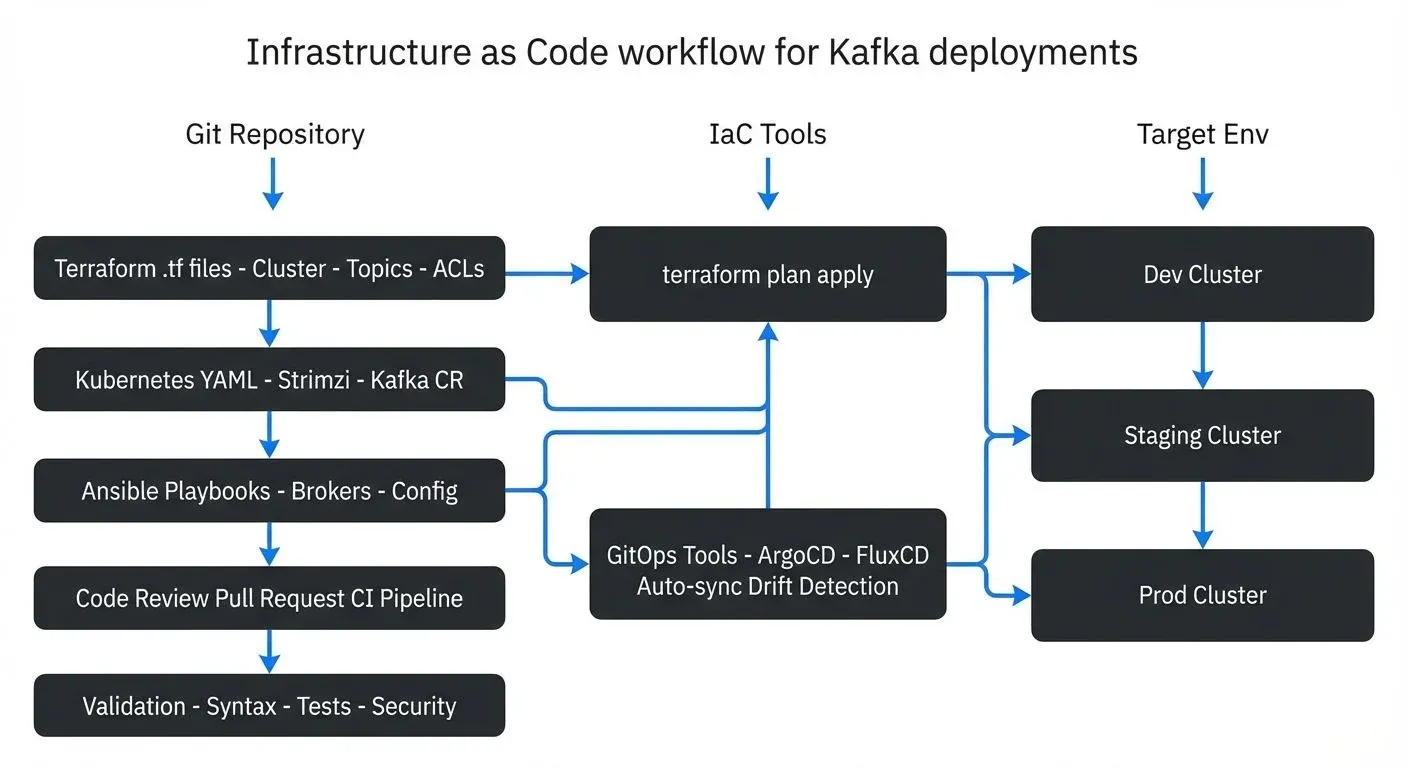
The Kafka Infrastructure Challenge
Kafka deployments involve multiple layers of infrastructure that must work in harmony. At the foundation, you need compute resources (virtual machines or containers) with appropriate CPU, memory, and network configurations. Storage requires careful planning, Kafka brokers need persistent volumes that can handle high throughput and provide the necessary durability guarantees.
Beyond the infrastructure layer, Kafka has its own configuration complexity. Historically, clusters depended on ZooKeeper for coordination, adding another distributed system to manage. With Kafka 4.0+ (released in 2024), KRaft mode has become the default and recommended approach, eliminating ZooKeeper entirely. KRaft mode introduces new considerations around controller quorum setup, dedicated controller nodes that manage cluster metadata using Kafka's own Raft consensus protocol. Each broker requires specific configurations for log retention, replication factors, and inter-broker communication. For more details on KRaft architecture, see Understanding KRaft Mode in Kafka.
On top of the cluster itself, operational resources multiply quickly. A production Kafka deployment typically includes dozens or hundreds of topics, each with specific partition counts, replication settings, and retention policies (see Kafka Topic Design Guidelines for best practices). Security configurations add access control lists, user credentials, and encryption settings, covered in detail in Kafka ACLs and Authorization Patterns and Kafka Security Best Practices. Kafka Connect deployments require connector configurations and associated infrastructure (see Kafka Connect: Building Data Integration Pipelines). Schema registries need their own setup and version management (see Schema Registry and Schema Management).
Managing this complexity manually is error-prone and doesn't scale. When you need to replicate environments for development, staging, and production, or deploy across multiple regions, manual processes break down quickly.
IaC Tools for Kafka Deployments
Several tools have emerged to tackle Kafka infrastructure management, each with different strengths.
- Terraform has become a popular choice for Kafka deployments. The Terraform Kafka provider allows you to define topics, ACLs, and quotas as code. Combined with cloud provider modules, you can manage the entire stack from virtual machines to Kafka resources in a single workflow. Terraform's state management and plan-preview capabilities help teams understand changes before applying them.
- Kubernetes Operators like Strimzi provide a cloud-native approach to Kafka deployment. These operators use custom resources to define Kafka clusters declaratively, handling the complexity of pod scheduling, storage provisioning, and rolling updates. The operator pattern fits naturally with containerized environments and provides built-in automation for common operational tasks.
- Ansible offers procedural automation through playbooks that can configure both infrastructure and Kafka resources. While less declarative than Terraform or operators, Ansible's flexibility makes it suitable for complex migration scenarios or organizations with existing Ansible investments.
- Cloud Provider Modules enable integration with managed Kafka services like AWS MSK, Azure Event Hubs, and Google Cloud Pub/Sub. These modules handle cloud-specific configurations while maintaining the benefits of infrastructure as code across hybrid environments.
GitOps and Continuous Deployment
GitOps has emerged as a powerful pattern for managing Kafka infrastructure in 2025. GitOps extends IaC principles by using Git as the single source of truth and automatically synchronizing infrastructure state with Git repository contents.
ArgoCD and FluxCD are the leading GitOps tools for Kubernetes-based Kafka deployments. These tools continuously monitor Git repositories and automatically apply changes to Kubernetes clusters, including Kafka resources managed by operators like Strimzi. When you update a Kafka cluster definition in Git, ArgoCD or FluxCD detects the change and orchestrates the rolling update automatically, with built-in rollback capabilities if issues arise.
GitOps patterns provide several advantages for Kafka operations:
- Audit trail: Every infrastructure change is a Git commit, providing complete history of who changed what and when
- Drift detection: GitOps tools continuously reconcile actual cluster state with desired state in Git, alerting on manual changes
- Disaster recovery: Entire Kafka deployments can be reconstructed from Git repository contents
- Multi-cluster management: Single Git repository can define infrastructure across development, staging, production, and multiple regions
For Kubernetes-based Kafka deployments, see Running Kafka on Kubernetes and Strimzi Kafka Operator for Kubernetes for detailed implementation guidance.
Cloud-Native and Managed Services
Modern Kafka deployments increasingly use cloud provider services that work well with IaC workflows:
- AWS MSK (Managed Streaming for Apache Kafka) now supports KRaft mode and can be provisioned entirely through Terraform or CloudFormation. MSK handles broker provisioning, patching, and scaling while allowing teams to manage topics, ACLs, and Connect configurations as code.
- Azure Event Hubs provides a Kafka-compatible API and integrates with Azure Resource Manager templates and Terraform. Teams can define Event Hubs namespaces and event hubs (equivalent to topics) declaratively alongside other Azure resources.
- Google Cloud Pub/Sub offers Kafka-compatible endpoints through its Pub/Sub Lite service, manageable via Terraform and Google Cloud Deployment Manager.
These managed services reduce operational burden while maintaining IaC benefits. Teams define cluster configurations, security policies, and monitoring as code without managing underlying infrastructure. For production deployments, combining managed control planes with IaC for application-level resources (topics, schemas, connectors) provides an optimal balance of convenience and control.
Infrastructure as Code in Data Streaming Environments
Data streaming platforms present unique IaC requirements that distinguish them from traditional application infrastructure. Streaming systems are inherently stateful and often run continuously for months or years. Any infrastructure change must account for in-flight data and avoid disrupting processing pipelines.
IaC enables streaming teams to maintain consistency across environments while adapting configurations to each environment's needs. Your development environment might use single-broker Kafka with minimal replication, while production requires a multi-zone cluster with replication factor three. With IaC, these differences are parameterized rather than ad-hoc, reducing the risk of configuration drift causing issues.
Disaster recovery planning becomes more robust with IaC. When infrastructure definitions exist as code, rebuilding a failed cluster or creating a new cluster in a different region becomes a repeatable process rather than an emergency scramble to remember undocumented settings. Teams can even test their recovery procedures by regularly spinning up new clusters from code in test environments. For multi-region deployments, see Kafka MirrorMaker 2 for Cross-Cluster Replication.
Multi-tenant streaming platforms particularly benefit from IaC. When onboarding a new team or application, infrastructure teams can apply tested templates that provision topics, service accounts, ACLs, and monitoring in a standardized way. This self-service approach scales better than manual provisioning while maintaining security and operational standards. For multi-tenancy patterns, see Multi-Tenancy in Kafka Environments.
Best Practices for Kafka IaC
Successful Kafka IaC implementations follow several key practices. Version control is foundational, all infrastructure definitions should live in Git repositories with the same protections as application code. This enables code review, creates an audit trail, and allows teams to understand how infrastructure evolved over time.
Separate environments should use the same IaC code with different parameters or variable files. This "write once, deploy many" approach ensures that your production infrastructure actually matches what was tested in lower environments. Consider using workspaces in Terraform or separate namespaces in Kubernetes to isolate environments while sharing code.
Test infrastructure changes before applying them to production. Terraform's plan command and Kubernetes' dry-run capabilities let you preview changes. For critical changes like modifying partition counts or replication factors, test in a non-production environment first to verify the impact.
Implement proper secret management. Never commit credentials or sensitive configuration to version control. Use secret management tools like HashiCorp Vault, AWS Secrets Manager, or Kubernetes Secrets, and reference them in your IaC code.
Document non-obvious decisions through code comments and README files. While IaC serves as documentation, context about why certain configurations were chosen helps future maintainers understand the system.
Real-World Implementation Example
Here's a practical example using Terraform to manage Kafka topics. This snippet demonstrates how teams can define topics with specific configurations and manage them as code:
terraform {
required_providers {
kafka = {
source = "Mongey/kafka"
version = "~> 0.8"
}
}
}
provider "kafka" {
bootstrap_servers = var.kafka_bootstrap_servers
tls_enabled = true
# For KRaft mode clusters (Kafka 4.0+), no ZooKeeper configuration needed
}
resource "kafka_topic" "orders" {
name = "customer.orders"
replication_factor = 3
partitions = 12
config = {
"retention.ms" = "604800000" # 7 days
"compression.type" = "snappy"
"min.insync.replicas" = "2"
"cleanup.policy" = "delete"
}
}
resource "kafka_acl" "orders_producer" {
resource_type = "Topic"
resource_name = kafka_topic.orders.name
acl_principal = "User:order-service"
acl_operation = "Write"
acl_permission_type = "Allow"
}This code defines a topic with production-appropriate settings: three-way replication for durability, 12 partitions for parallelism, and a seven-day retention period. The ACL grants write permissions to the order service. Running terraform apply creates these resources, and changes to the code trigger updates to keep infrastructure aligned with the definition.
Complementary Tooling and Testing
While IaC tools handle infrastructure provisioning, additional platforms enhance the complete deployment lifecycle:
Conduktor provides comprehensive Kafka management capabilities that complement IaC workflows. Conduktor's platform includes:
- Configuration management: Define topic standards, naming conventions, and governance policies that validate IaC-created resources against organizational requirements
- Testing integration: Conduktor Gateway, a Kafka proxy, enables chaos engineering and integration testing for Kafka deployments. Teams can test how applications handle broker failures, network partitions, or replication lag, validating that IaC-defined resilience settings actually work
- Observability: Real-time monitoring of topics, consumer groups, and cluster health, helping validate that deployed infrastructure performs as expected (see Kafka Cluster Monitoring and Metrics for comprehensive monitoring strategies)
- Security governance: Enforces data masking, encryption, and access policies across environments, ensuring IaC-defined security configurations align with compliance requirements
- Terraform automation: Automate Conduktor configuration with Terraform for complete infrastructure-as-code workflows
For example, after Terraform provisions a new topic, Conduktor can automatically verify it meets naming standards, has appropriate retention policies, and complies with data classification rules. Conduktor Gateway can then inject failures to test that the replication factor and min.insync.replicas settings actually provide the expected durability.
This layered approach, IaC for provisioning, complementary platforms for governance and testing, creates robust, well-tested Kafka deployments. For comprehensive testing approaches, see Testing Strategies for Streaming Applications. For sizing infrastructure correctly, see Kafka Capacity Planning.
Summary
Infrastructure as Code transforms Kafka deployments from manual, error-prone processes into repeatable, testable, and auditable workflows. By codifying infrastructure decisions, teams gain consistency across environments, simplified disaster recovery, and the ability to scale operations without proportionally scaling operational overhead.
The specific tools matter less than the principles: version-controlled definitions, automated application of changes, separation of environments through parameterization, and thorough testing before production deployment. Whether using Terraform, Kubernetes operators, or other tools, these practices enable teams to manage Kafka's inherent complexity while maintaining reliability. For operational best practices beyond IaC, see Kafka Admin Operations and Maintenance.
As streaming platforms grow in scale, IaC becomes a necessity. Infrastructure automation tools combined with platforms for resource management make reliable streaming data systems achievable.
Related Concepts
- Strimzi Kafka Operator for Kubernetes - Kubernetes-native IaC approach for Kafka using operators and custom resources with GitOps workflows.
- CI/CD Best Practices for Streaming Applications - Integrate IaC-managed Kafka infrastructure into continuous deployment pipelines.
- Kafka Capacity Planning - Use capacity planning insights to parameterize IaC templates for different environment sizes and workloads.
Sources and References
- HashiCorp Terraform Kafka Provider Documentation - https://registry.terraform.io/providers/Mongey/kafka/latest/docs
- Strimzi: Kubernetes Operator for Apache Kafka - https://strimzi.io/documentation/
- Confluent: Automation and Infrastructure as Code - https://docs.confluent.io/platform/current/installation/overview.html
- Martin Fowler, "Infrastructure as Code" - https://martinfowler.com/bliki/InfrastructureAsCode.html
- Apache Kafka Operations Documentation - https://kafka.apache.org/documentation/#operations