API Gateway Patterns for Data Platforms
Modern data platforms handle diverse data sources, multiple protocols, and complex access patterns. API gateways provide a critical abstraction layer that simplifies client access while enforcing security, governance, and performance controls. Understanding gateway patterns helps teams build scalable, secure data architectures.
What is an API Gateway in Data Platforms?
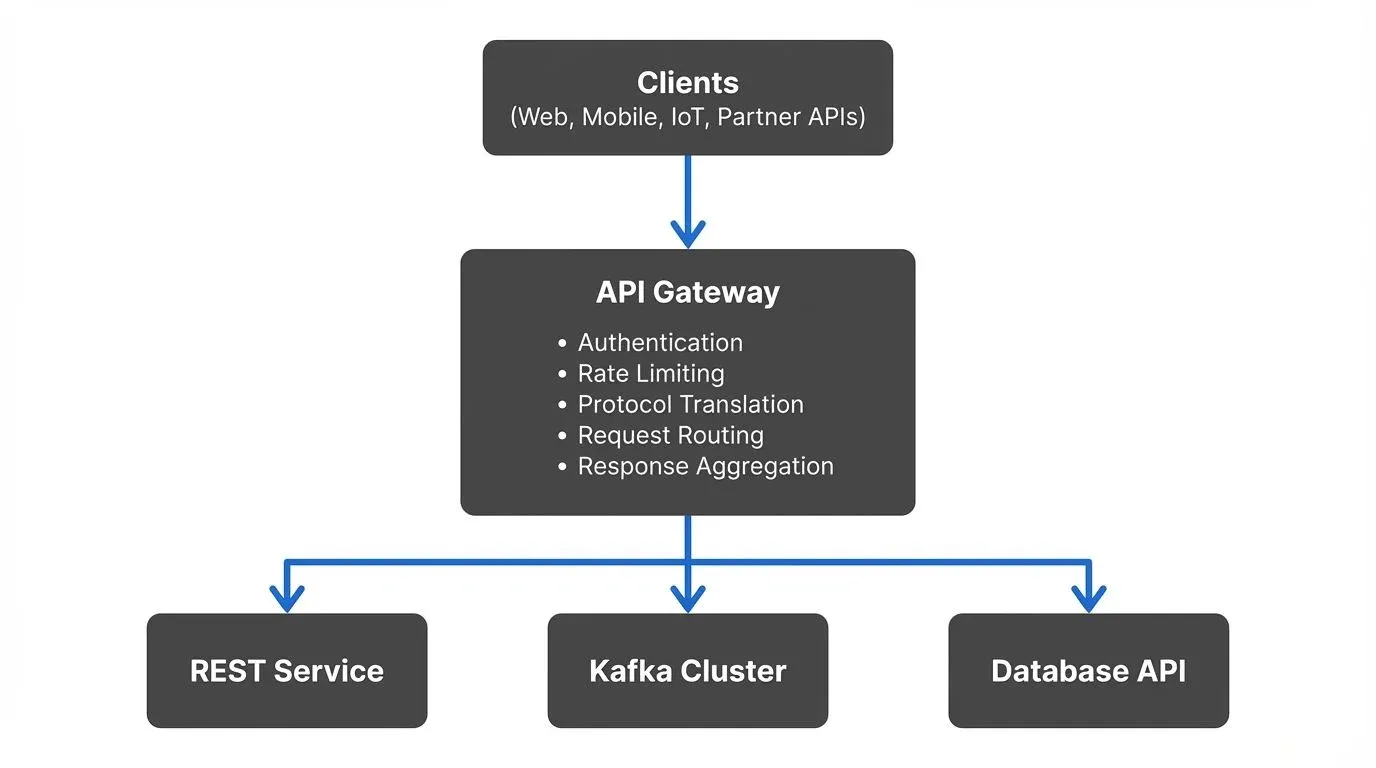
An API gateway is a server that provides a single entry point for multiple backend services. In data platforms, gateways sit between data consumers and data sources, whether those sources are REST APIs, databases, or streaming platforms like Apache Kafka.
The gateway handles cross-cutting concerns that would otherwise need to be implemented in every service: authentication, rate limiting, protocol translation, logging, and request routing. This consolidation reduces complexity and creates consistent behavior across the platform.
For data platforms specifically, API gateways solve several problems. They provide a unified interface to heterogeneous data sources, translate between protocols (like REST to Kafka), enforce data governance policies, and protect backend systems from overload.
Core API Gateway Patterns
Routing and Service Discovery
The routing pattern directs requests to appropriate backend services based on URL paths, headers, or request content. A gateway might route /customers/ to a customer database API while /orders/ goes to an order processing service.
Dynamic routing extends this by discovering services at runtime. When new data sources come online, the gateway automatically includes them without manual configuration changes. This pattern is essential in cloud-native data platforms where services scale dynamically.
Protocol Translation
Data platforms often need to bridge different communication protocols. A common scenario involves HTTP clients accessing Kafka topics. The gateway translates REST requests into Kafka producer calls and streams Kafka messages back as HTTP responses.
Confluent's REST Proxy exemplifies this pattern, allowing HTTP clients to produce and consume Kafka messages without native Kafka client libraries. This enables broader ecosystem integration, though with performance tradeoffs: HTTP serialization overhead typically reduces throughput to ~20K events/second per deployment compared to 100K+ events/second for native Kafka clients. The tradeoff favors accessibility over raw performance, ideal for low-throughput integrations, web clients, and services where native Kafka libraries aren't feasible.
Request and Response Aggregation
The aggregation pattern combines multiple backend calls into a single gateway response. For example, a dashboard might need customer data, recent orders, and account balance. Instead of three separate client requests, the gateway fetches all three and returns a unified response.
This pattern reduces network round trips and simplifies client code. However, it requires careful design to avoid creating overly complex gateway logic that duplicates business logic better placed in dedicated services.
Rate Limiting and Throttling
Protecting backend systems from overload is critical in data platforms. Rate limiting restricts how many requests a client can make in a time window. This prevents individual consumers from monopolizing resources or accidentally creating cascading failures.
Throttling extends rate limiting by actively slowing down requests rather than rejecting them. A gateway might queue excess requests and process them at a sustainable rate. This smooths traffic spikes while maintaining system stability.
API Gateways for Data Streaming Systems
Streaming platforms like Apache Kafka present unique gateway requirements. Traditional HTTP gateways assume request-response patterns, but streaming systems are inherently asynchronous and continuous.
Stream-Specific Gateway Patterns
Kafka gateways must handle long-lived connections for consuming message streams. A WebSocket gateway can maintain persistent connections that stream Kafka messages to browsers or mobile apps. This enables real-time data delivery without constant polling.
For comprehensive understanding of Kafka's core architecture and how topics, partitions, and consumer groups work, see Apache Kafka. 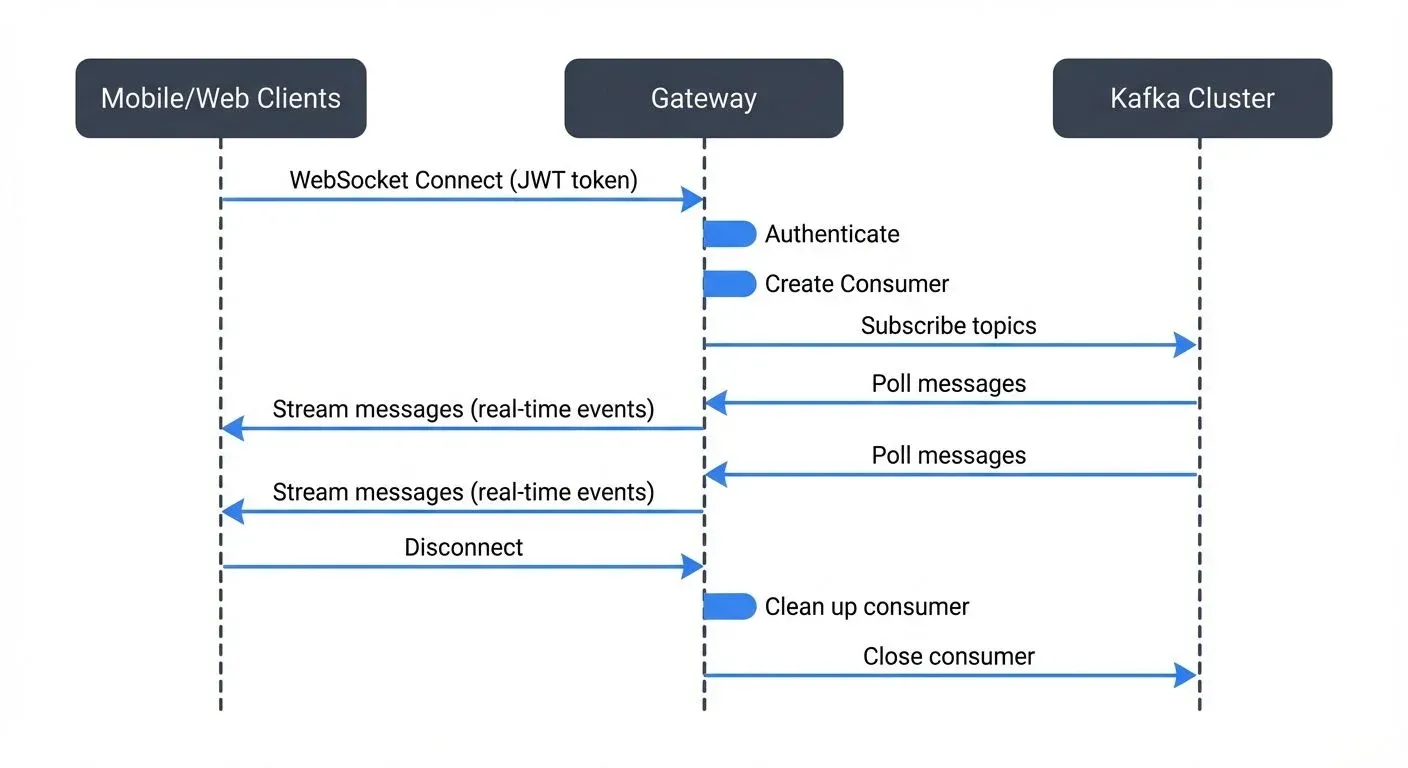
Topic-based routing becomes the streaming equivalent of path-based routing. The gateway maps logical topics to physical Kafka topics, allowing topic reorganization without breaking client code. It can also merge multiple topics into a single consumer stream or split a single topic into multiple logical views.
Real-World Example: Event-Driven API Gateway
Consider an e-commerce platform using Kafka for event streaming. Mobile apps need real-time order updates, but implementing Kafka clients in mobile apps creates maintenance challenges and security risks.
An API gateway solves this by exposing a WebSocket endpoint at /orders/stream. When a mobile app connects, the gateway:
- Authenticates the user via JWT token
- Determines which Kafka topics the user can access
- Creates a Kafka consumer scoped to that user's orders
- Streams order events back through the WebSocket connection
- Manages consumer lifecycle, including offset commits and reconnection handling
Important: The gateway must carefully manage consumer group membership and offset commits. Options include:
- Unique consumer group per WebSocket session: Simplest but resource-intensive
- Shared consumer group with external offset storage: Store delivery tracking in Redis/database
- Stateful gateway instances: Use sticky sessions so reconnections hit the same gateway instance
The choice depends on delivery semantics (at-least-once vs at-most-once) and reconnection requirements. This pattern keeps Kafka internals hidden while providing real-time capabilities to clients.
For detailed consumer group mechanics and offset management strategies, see Kafka Consumer Groups Explained.
Specialized Kafka Gateways
Specialized gateways extend traditional API gateway patterns specifically for Kafka environments. They sit between applications and Kafka clusters, enforcing policies that would be difficult to implement at the application level.
These gateways support encryption and decryption of sensitive fields, ensuring that applications never see raw PII data. They also provide topic virtualization, where teams can access logical topic names that map to physical topics according to governance rules.
For multi-tenant Kafka clusters, specialized gateways enforce tenant isolation by validating that applications only access their authorized topics and consumer groups. This prevents accidental cross-tenant data leakage while maintaining a unified Kafka infrastructure.
Security and Governance Patterns
Authentication and Authorization
Gateways centralize authentication by validating credentials once rather than in every backend service. Common patterns include JWT validation, OAuth flows, and API key verification.
Authorization determines what authenticated users can access. In data platforms, this often means enforcing row-level or column-level security. A gateway might filter datasets based on user roles or mask sensitive fields before returning data.
Audit Logging and Compliance
Comprehensive audit trails are essential for data governance. Gateways log every request with details like user identity, requested resources, timestamp, and response status. This creates a single source of truth for data access patterns.
For compliance regimes like GDPR or HIPAA, gateways can enforce retention policies, log data lineage, and provide evidence of proper data handling. The centralized position makes gateways ideal for compliance enforcement.
For comprehensive audit logging patterns in streaming environments, see Audit Logging for Streaming Platforms.
Performance and Scalability Considerations
Caching Strategies
Gateways can cache frequently accessed data to reduce backend load and improve response times. Time-based expiration works for relatively static data, while event-based invalidation suits data that changes in response to specific events.
For streaming platforms, caching becomes more complex. A gateway might cache the latest message from each Kafka topic, serving recent data instantly while streaming updates as they arrive. This balances latency and freshness.
Circuit Breaker Pattern
When backend services fail, circuit breakers prevent cascading failures. The gateway monitors error rates and automatically stops sending requests to failing services. After a timeout, it allows test requests through to check if the service recovered.
This pattern is critical in data platforms where a single slow database query could back up the entire system. Circuit breakers fail fast and preserve capacity for healthy services.
Gateway Scalability
The gateway itself must not become a bottleneck. Horizontal scaling runs multiple gateway instances behind a load balancer. Stateless gateway design ensures that any instance can handle any request.
For high-throughput streaming scenarios, gateways may need specialized infrastructure. Kafka gateways benefit from co-location with Kafka brokers to minimize latency and network overhead.
Real-World Implementation Example
A financial services company processes millions of transactions daily through Kafka. Different teams need access to transaction data, but security requirements vary by team.
Their gateway implementation includes:
- API key authentication for internal services and OAuth for external partners
- Role-based topic access where retail banking teams see only retail transactions
- PII masking that redacts customer names and account numbers for analytics teams
- Rate limiting of 1000 requests per minute per API key
- Circuit breakers that fail over to cached data when Kafka is unavailable
This architecture allows diverse consumers to access the same underlying data platform while maintaining strict security and performance guarantees. The gateway handles complexity that would otherwise require custom code in dozens of applications.
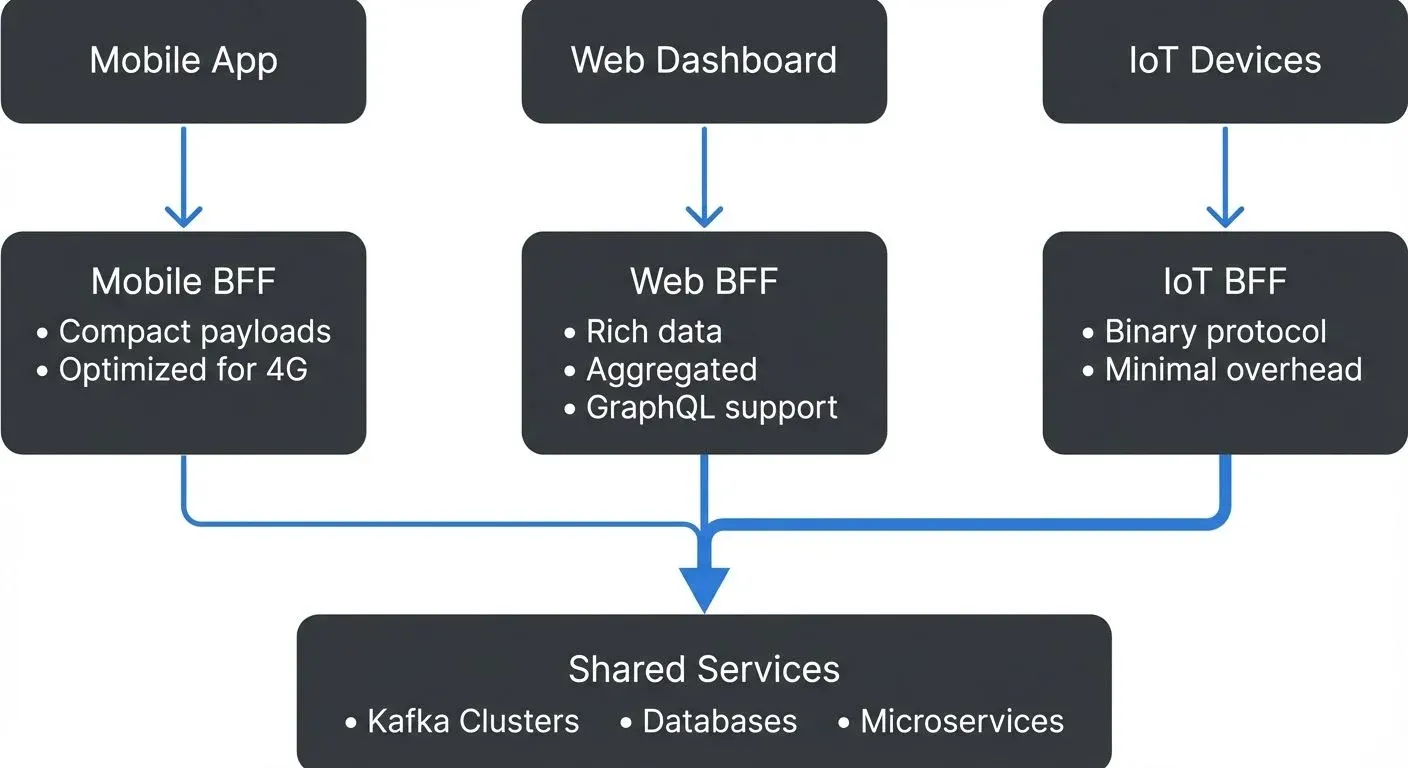
Backend for Frontend (BFF) Pattern
The BFF pattern addresses a common problem with monolithic API gateways: they accumulate client-specific logic that bloats the gateway and couples it to specific frontends. Instead of one gateway serving all clients, each client type gets its own optimized backend service.
Why BFF Matters
Different clients have different needs:
- Mobile apps need minimal payloads (battery/bandwidth constraints)
- Web dashboards need rich aggregated data
- IoT devices need efficient binary protocols
- Partner APIs need stable, versioned contracts
A single gateway serving all these clients either:
- Returns everything (over-fetching for most clients)
- Returns minimal data (under-fetching, requiring multiple requests)
- Grows complex conditional logic based on client type
BFF Architecture
BFF Benefits for Data Platforms
- Domain ownership: Each frontend team owns their BFF, enabling independent deployment and iteration without coordinating with other teams.
- Optimized queries: Mobile BFF fetches only fields needed for mobile UI, reducing Kafka message deserialization and database queries.
- Protocol flexibility: Web BFF can offer GraphQL while IoT BFF uses efficient binary protocols (Protobuf, CBOR).
- Simplified testing: Each BFF has a focused scope, making integration testing easier than testing a monolithic gateway with conditional paths.
BFF Considerations
- Code duplication: Common logic (authentication, rate limiting) may be duplicated across BFFs. Solve with shared libraries or a thin common gateway layer.
- Operational overhead: Multiple BFFs mean multiple deployments. Container orchestration (Kubernetes) and infrastructure-as-code reduce this burden.
- When not to use BFF: Small teams with simple requirements benefit from a unified gateway. BFF pattern pays off as client diversity and team count grow.
Summary
API gateways are essential components of modern data platforms, providing unified access to diverse data sources while enforcing security, governance, and performance policies. Core patterns like routing, protocol translation, aggregation, and rate limiting apply across all gateway implementations.
For data streaming systems like Kafka, gateways enable new use cases by bridging HTTP and streaming protocols, managing long-lived connections, and enforcing fine-grained access controls. Patterns like circuit breakers and caching ensure gateways enhance rather than degrade system performance.
Successful gateway implementations balance flexibility with governance. They simplify client access without creating a monolithic bottleneck. As data platforms grow in complexity, well-designed API gateways become increasingly critical to maintaining security, performance, and developer productivity.
Related Concepts
- Access Control for Streaming - Access control mechanisms that API gateways enforce to protect streaming data platforms
- Kafka ACLs and Authorization Patterns - Fine-grained authorization patterns that gateways can implement for Kafka-based data platforms
- Multi-Tenancy in Kafka Environments - Multi-tenant patterns that API gateways enable by providing isolation and resource controls
Sources and References
- Richardson, C. (2018). Microservices Patterns: With Examples in Java. Manning Publications. Chapter 8: External API Patterns.
- Confluent Documentation. (2024). "REST Proxy API Reference." https://docs.confluent.io/platform/current/kafka-rest/api.html
- AWS Architecture Center. (2024). "API Gateway Pattern." https://aws.amazon.com/architecture/
- Stopford, B. (2018). Designing Event-Driven Systems. O'Reilly Media. Chapter 11: Event Streams and APIs.
Written by Stéphane Derosiaux · Last updated May 12, 2026