High Value Assets: Protecting Critical Data in Streaming
Not all data is created equal. In any organization, certain data assets represent disproportionate value, or risk. These High Value Assets (HVAs) are the crown jewels that, if compromised, could cause severe business disruption, regulatory penalties, or reputational damage.
In streaming architectures, where data flows continuously through multiple systems and services, identifying and protecting HVAs becomes both more critical and more complex. A single Kafka topic carrying payment transactions, personally identifiable information (PII), or intellectual property may represent millions of dollars in potential liability. Yet the real-time nature of streaming means traditional perimeter-based "castle-and-moat" security approaches often fall short.
Modern security architectures embrace zero trust principles: verify every access request, assume breach, minimize blast radius, and enforce least-privilege access, regardless of network location. For HVAs in streaming systems, zero trust means authenticating and authorizing every producer and consumer, encrypting all data in transit, and continuously monitoring for anomalous behavior. For comprehensive security patterns, see Kafka Security Best Practices and Kafka ACLs and Authorization Patterns. 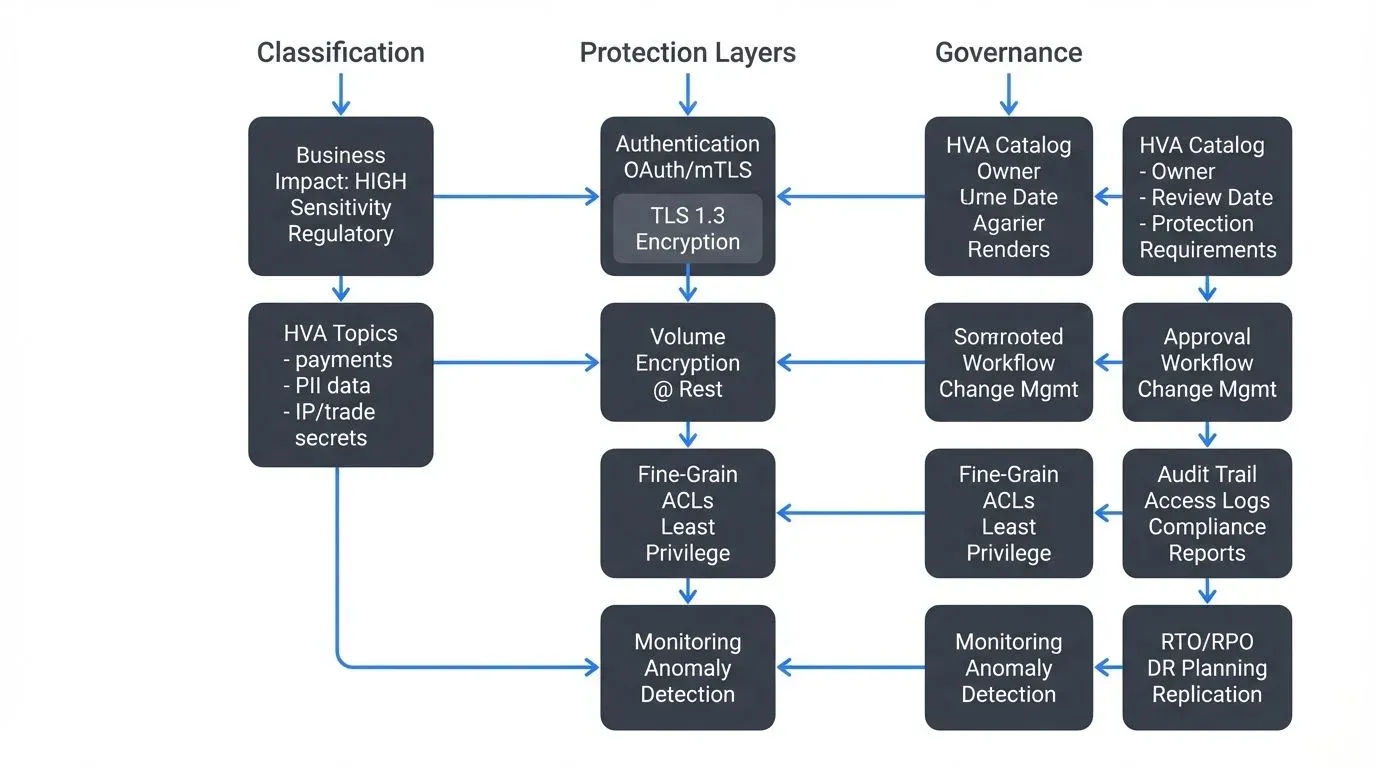
The cost of HVA compromise extends beyond immediate financial loss. Organizations face regulatory fines, litigation expenses, customer churn, and lasting damage to brand trust. According to IBM's 2024 Cost of a Data Breach Report, the average cost of a data breach reached $4.88 million globally, representing a 10% increase from 2023. Breaches involving sensitive customer data and regulated information command the highest price tags, with healthcare breaches averaging $9.77 million. For streaming systems processing HVAs at scale, where a single compromised topic could expose millions of records, the stakes are exponentially higher.
Classifying High Value Assets
Effective HVA protection starts with proper classification. Organizations must establish clear, consistent criteria for determining which data assets qualify as high-value. Three primary dimensions drive HVA classification:
- Business Impact: Assets that directly affect revenue, operations, or strategic advantage. In streaming systems, this includes topics carrying financial transactions, pricing data, supply chain events, or real-time analytics feeding business-critical decisions. The key question: "What would happen if this data became unavailable, corrupted, or exposed?"
- Sensitivity: Data subject to privacy laws, competitive advantage concerns, or confidentiality agreements. Personal health information (PHI), payment card data (PCI), customer PII, trade secrets, and merger/acquisition details all qualify. Streaming platforms often aggregate multiple sensitive data types into derived topics, elevating their HVA status.
- Regulatory Requirements: Certain regulations explicitly mandate HVA programs. NIST Cybersecurity Framework, CMMC (Cybersecurity Maturity Model Certification), and various financial services regulations require organizations to identify and protect high-value or high-risk data assets. Failure to properly classify and safeguard regulatory HVAs can trigger compliance violations.
In streaming contexts, HVA classification becomes dynamic. A topic containing anonymized data might transition to HVA status when joined with re-identification vectors through stream processing. Time-series data that seems innocuous in isolation may reveal competitive intelligence when analyzed in aggregate. Your HVA inventory must reflect these transformations.
Discovering and Cataloging HVAs
Building an HVA inventory requires systematic discovery across your streaming landscape. This process presents unique challenges compared to traditional databases:
- Dynamic Discovery: Streaming topics proliferate rapidly. Teams create new data products, join streams, and derive new topics without always following formal approval processes. Automated discovery tools that continuously scan your Kafka clusters, schema registries, and stream processing applications become essential. These tools should capture topic metadata, schema definitions, data lineage, and consumer patterns.
- Content Classification: Understanding what's in a topic requires more than reading topic names. Schema analysis helps, but real HVAs often hide in nested fields or emerge from combinations of seemingly innocuous attributes. Data classification engines that sample streaming data, apply machine learning models, and flag sensitive patterns provide crucial visibility. For PII detection specifically, see PII Detection and Handling in Event Streams.
- Lineage Tracking: Where did this data come from? Where does it go? HVA classification must follow data lineage. If a source system contains HVA data, downstream topics inheriting that data likely qualify as HVAs too, unless effective de-identification (removing identifiers to prevent re-identification), encryption (encoding data to prevent unauthorized access), or filtering (removing sensitive fields entirely) occurs in transit. Each technique serves different purposes: filtering eliminates data permanently, masking obscures it reversibly for certain users, and encryption protects it while maintaining full fidelity for authorized consumers.
Modern governance platforms provide tools specifically designed for streaming architectures, making it easier to manage and protect HVAs across complex topologies. Tools like Apache Atlas and OpenLineage provide open-source lineage tracking, while Conduktor offers commercial-grade policy enforcement, access controls, and audit logging for Kafka environments.
Your HVA catalog should document:
- Asset identifier (cluster, topic, schema)
- Classification rationale (business impact, sensitivity, regulatory)
- Data owner and steward
- Protection requirements
- Retention policies
- Approved consumers
- Review date
Example HVA Catalog Entry:
Topic: payments-prod-us-east-1
Cluster: prod-financial-cluster
Classification: High Value Asset
Rationale:
- Business Impact: HIGH - Processes $50M+ daily transactions
- Sensitivity: HIGH - Contains PCI DSS cardholder data
- Regulatory: PCI DSS 4.0, SOC 2 Type II
Owner: Payments Platform Team (payments-team@company.com)
Data Steward: Jane Chen (jane.chen@company.com)
Protection Requirements:
- TLS 1.3 encryption in transit
- Volume encryption at rest (AWS KMS)
- OAuth 2.0 authentication required
- ACLs restricted to 3 authorized service accounts
- Audit logging enabled with 7-year retention
Retention Policy: 90 days (regulatory requirement)
Approved Consumers:
- payment-processing-service (Write)
- fraud-detection-service (Read)
- compliance-reporting-service (Read)
Last Review: 2025-10-15
Next Review: 2026-01-15Treat this catalog as a living document. Schedule quarterly reviews, trigger reassessment when data usage changes, and automate alerts when new potential HVAs appear. For schema governance and evolution tracking, see Schema Registry and Schema Management.
Risk-Based Protection Strategies
Once identified, HVAs demand proportional protection. The principle of risk-based security means applying stronger controls to higher-value assets while avoiding over-engineering protections for lower-risk data.
- Encryption: HVAs should be encrypted at rest and in transit. For streaming systems, this means TLS for all broker connections, encrypted storage for Kafka log segments, and potentially application-level encryption for sensitive fields.
- Envelope encryption provides an additional security layer for maximum-sensitivity HVAs: data encryption keys (DEKs) encrypt your actual data, while master keys stored in hardware security modules (HSMs) or cloud key management services (AWS KMS, Azure Key Vault, GCP Cloud KMS) encrypt the DEKs themselves. This separation means compromising storage doesn't expose master keys, and key rotation becomes manageable without re-encrypting all data.
Example encryption configuration for Kafka brokers (2025 standards):
# Enable TLS 1.3 for client connections (Kafka 3.0+)
listeners=SSL://kafka-broker:9093
ssl.protocol=TLSv1.3
ssl.enabled.protocols=TLSv1.3
ssl.cipher.suites=TLS_AES_256_GCM_SHA384,TLS_AES_128_GCM_SHA256
# SSL certificates and keystores
# Keystore: contains broker's private key and certificate (broker identity)
# Truststore: contains trusted CA certificates (for validating client certificates)
ssl.keystore.location=/var/private/ssl/kafka.server.keystore.jks
ssl.keystore.password=${KEYSTORE_PASSWORD}
ssl.key.password=${KEY_PASSWORD}
ssl.truststore.location=/var/private/ssl/kafka.server.truststore.jks
ssl.truststore.password=${TRUSTSTORE_PASSWORD}
ssl.client.auth=required
# Enable encryption at rest
log.dirs=/var/kafka-logs-encrypted
# Use LUKS (Linux), dm-crypt, or cloud-native volume encryption
# SASL/SCRAM for authentication (Kafka 2.0+)
sasl.mechanism.inter.broker.protocol=SCRAM-SHA-512
sasl.enabled.mechanisms=SCRAM-SHA-512
security.inter.broker.protocol=SASL_SSLAccess Control: Implement least-privilege access through fine-grained ACLs. HVA topics should restrict both producers and consumers to explicitly authorized service accounts. Role-based access control (RBAC) policies should clearly document who can read, write, or administer HVA assets. For highly sensitive topics, consider implementing dual-authorization requirements where multiple approvals are needed before granting access.
Example ACL configuration for HVA topics (Kafka 3.x+ with KRaft mode):
# Modern KRaft-mode ACL management (Kafka 3.0+, required for Kafka 4.0+)
# Note: --bootstrap-server replaces deprecated --authorizer-properties with ZooKeeper
# Allow only specific service account to produce to HVA topic
kafka-acls --bootstrap-server localhost:9092 \
--command-config admin.properties \
--add \
--allow-principal User:payment-service \
--operation Write \
--topic payments-hva
# Allow only analytics service to consume
kafka-acls --bootstrap-server localhost:9092 \
--command-config admin.properties \
--add \
--allow-principal User:analytics-service \
--operation Read \
--topic payments-hva \
--group analytics-consumer-group
# Deny all other access explicitly (evaluated after allow rules)
kafka-acls --bootstrap-server localhost:9092 \
--command-config admin.properties \
--add \
--deny-principal User:* \
--operation All \
--topic payments-hva
# For enterprise environments, Conduktor provides GUI-based ACL management
# with visual policy builders, change tracking, and audit trailsOAuth 2.0 and Modern Authentication: Modern HVA protection increasingly uses OAuth 2.0 and OpenID Connect (OIDC) for fine-grained, time-limited access control. Rather than managing long-lived service account credentials directly, OAuth enables centralized identity providers (Okta, Auth0, Azure AD, Keycloak) to issue short-lived access tokens with specific scopes and claims.
Kafka 3.1+ supports OAuth 2.0 through the org.apache.kafka.common.security.oauthbearer SASL mechanism. This enables:
- Token-based authentication with automatic expiration and renewal
- Fine-grained authorization based on JWT claims (user roles, groups, scopes)
- Centralized credential management eliminating distributed secret storage
- Audit integration with identity provider logs for complete access tracking
For detailed OAuth implementation patterns, see Kafka Authentication: SASL, SSL, OAuth.
Example OAuth configuration for HVA consumer:
# Client OAuth configuration (Kafka 3.1+)
security.protocol=SASL_SSL
sasl.mechanism=OAUTHBEARER
sasl.jaas.config=org.apache.kafka.common.security.oauthbearer.OAuthBearerLoginModule required \
clientId="hva-analytics-service" \
clientSecret="${OAUTH_CLIENT_SECRET}" \
scope="kafka.hva.read" \
tokenEndpointUrl="https://idp.example.com/oauth/token";
sasl.login.callback.handler.class=org.apache.kafka.common.security.oauthbearer.secured.OAuthBearerLoginCallbackHandler- Network Segmentation: Isolate HVA processing in dedicated clusters or brokers with restricted network access. Use private network segments, strict firewall rules, and jump hosts (secure intermediary servers requiring multi-factor authentication) for administrative access. This limits the blast radius if other parts of your streaming infrastructure become compromised.
- Data Masking and Tokenization: Where possible, mask or tokenize sensitive fields before they enter streaming pipelines. Stream processing applications can dynamically mask PII for non-HVA consumers while preserving full fidelity for authorized analytics. Format-preserving encryption maintains data utility while protecting HVA content.
- Monitoring and Anomaly Detection: HVAs require enhanced monitoring beyond standard observability. Track access patterns, data volumes, schema changes, and authentication events. Alert on unusual consumer activity, unexpected topic configurations, or access attempts from unauthorized networks. SIEM (Security Information and Event Management) systems like Splunk, Elastic Security, or AWS Security Hub enable correlation with broader security events across your infrastructure.
Modern HVA monitoring increasingly incorporates AI/ML-based anomaly detection to identify subtle attack patterns that rule-based systems miss, such as credential stuffing, gradual data exfiltration, or insider threat behaviors.
Example monitoring configuration using JMX metrics (captured via Prometheus for Kafka):
# Prometheus JMX exporter config for HVA monitoring
rules:
- pattern: kafka.server<type=BrokerTopicMetrics, name=MessagesInPerSec, topic=(.+)><>Count
name: kafka_topic_messages_in_total
labels:
topic: "$1"
type: COUNTER
- pattern: kafka.server<type=BrokerTopicMetrics, name=BytesInPerSec, topic=(.+)><>Count
name: kafka_topic_bytes_in_total
labels:
topic: "$1"
type: COUNTER
# Alert rules for HVA topics
alerts:
- alert: HVAUnauthorizedAccess
expr: increase(kafka_topic_failed_authentication_total{topic=~".*-hva"}[5m]) > 5
annotations:
summary: "Unauthorized access attempts on HVA topic {{ $labels.topic }}"
- alert: HVAUnusualVolume
expr: rate(kafka_topic_messages_in_total{topic=~".*-hva"}[5m]) > 2 * avg_over_time(rate(kafka_topic_messages_in_total{topic=~".*-hva"}[5m])[1h:5m])
annotations:
summary: "Unusual message volume on HVA topic {{ $labels.topic }}"Governance and Compliance
HVA protection isn't just technical, it requires robust governance processes:
- Approval Workflows: Creating new HVA topics or granting HVA access should trigger formal approval workflows. Data owners must review and approve requests. Security teams should validate that proposed protections meet policy requirements. Governance platforms like Conduktor can automate these workflows, routing requests through proper channels and maintaining immutable audit trails (see Conduktor Self-Service for approval workflow automation). For comprehensive audit logging patterns, see Streaming Audit Logs.
- Regulatory Mapping: Document which regulations apply to each HVA. PCI DSS governs payment data, HIPAA covers healthcare information, GDPR protects EU personal data, and CCPA addresses California consumer data. Each regulation imposes specific protection requirements. Your HVA program must map these requirements to technical controls and demonstrate compliance through regular assessments. For GDPR-specific considerations, see GDPR Compliance for Data Teams.
- Business Continuity: HVAs receive priority in disaster recovery planning. Recovery Time Objectives (RTOs) define maximum acceptable downtime before business impact becomes severe, while Recovery Point Objectives (RPOs) specify maximum acceptable data loss measured in time. HVA topics typically demand RTOs under 15 minutes and RPOs under 1 minute.
Implement cross-region replication using MirrorMaker 2 or cloud-native replication, maintain verified backups, and regularly test failover procedures. When HVA topics go down, critical business processes halt, your continuity plans must reflect this reality. For replication strategies, see Kafka MirrorMaker 2 for Cross-Cluster Replication.
Change Management: Changes affecting HVAs demand extra scrutiny. Schema evolution, retention policy updates, or ACL modifications should follow change control procedures with impact analysis and rollback plans. Automated governance tools can enforce these procedures, preventing unauthorized changes from reaching production.
Measuring Protection Effectiveness
You can't improve what you don't measure. HVA protection programs require metrics demonstrating effectiveness:
Coverage Metrics:
- Percentage of HVAs with encryption enabled
- HVAs with documented ownership
- HVAs with current access reviews
- Time-to-classify new HVA assets
Control Effectiveness:
- Failed access attempts to HVA topics
- Mean time to detect (MTTD) HVA incidents
- Mean time to respond (MTTR) to HVA incidents
- Policy violations detected and remediated
Compliance Metrics:
- HVAs meeting regulatory requirements
- Audit findings related to HVAs
- Days since last HVA inventory review
- Training completion for HVA stewards
Business Metrics:
- HVA incidents per quarter
- Financial impact of HVA-related incidents
- HVA availability percentage
- Cost per HVA (protection overhead)
Establish baselines, set improvement targets, and report metrics to leadership regularly. When metrics reveal gaps, trigger remediation. When incidents occur involving HVAs, conduct root cause analysis and update controls accordingly.
Conclusion: Building an HVA Program
High Value Asset protection represents a maturity milestone for data governance programs. Organizations that successfully implement HVA programs demonstrate risk management sophistication, regulatory compliance, and business alignment.
Start by identifying your most critical streaming data assets. Establish clear classification criteria and build your initial HVA inventory. Don't aim for perfection, start with your top 10-20 most critical topics and expand from there.
Implement proportional protections based on risk. Not every control applies to every HVA, but every HVA should have documented protection requirements and verified implementations.
Automate where possible. Manual HVA management doesn't scale in streaming architectures where topics number in the hundreds or thousands. Governance platforms that provide automated discovery, classification, policy enforcement, and compliance reporting make this tractable.
Threats evolve, business priorities shift, and new regulations emerge. Regular reviews, continuous monitoring, and adaptive controls keep HVA protections current.
Related Concepts
- Kafka ACLs and Authorization Patterns - Fine-grained access control patterns essential for protecting high-value assets in streaming environments
- Data Governance Framework: Roles and Responsibilities - Governance structures that support HVA identification, classification, and protection workflows
- Encryption at Rest and in Transit for Kafka - Encryption strategies critical for protecting high-value data as it flows through streaming systems
Sources and References
- NIST Special Publication 800-53: Security and Privacy Controls for Information Systems and Organizations
- NIST Cybersecurity Framework: High Value Asset Management Guidelines
- ISO/IEC 27001:2022: Information Security Management Systems
- PCI DSS v4.0: Payment Card Industry Data Security Standard
- HIPAA Security Rule: 45 CFR Part 164, Subpart C - Security Standards for the Protection of Electronic Protected Health Information
- GDPR Article 32: Security of Processing Requirements
- Apache Kafka Security Documentation: Encryption and Authentication Configuration
- CMMC Model: Cybersecurity Maturity Model Certification - Asset Management Practices
- Cost of a Data Breach Report 2023: IBM Security and Ponemon Institute
Written by Stéphane Derosiaux · Last updated May 12, 2026