Data Drift in Streaming: Detecting and Managing Unexpected Changes
In streaming data systems, the assumption that data maintains consistent patterns and structures over time is rarely true. Data drift — where data characteristics change unexpectedly — creates real challenges for real-time pipelines and machine learning models. Understanding and managing drift is essential for reliable streaming applications. 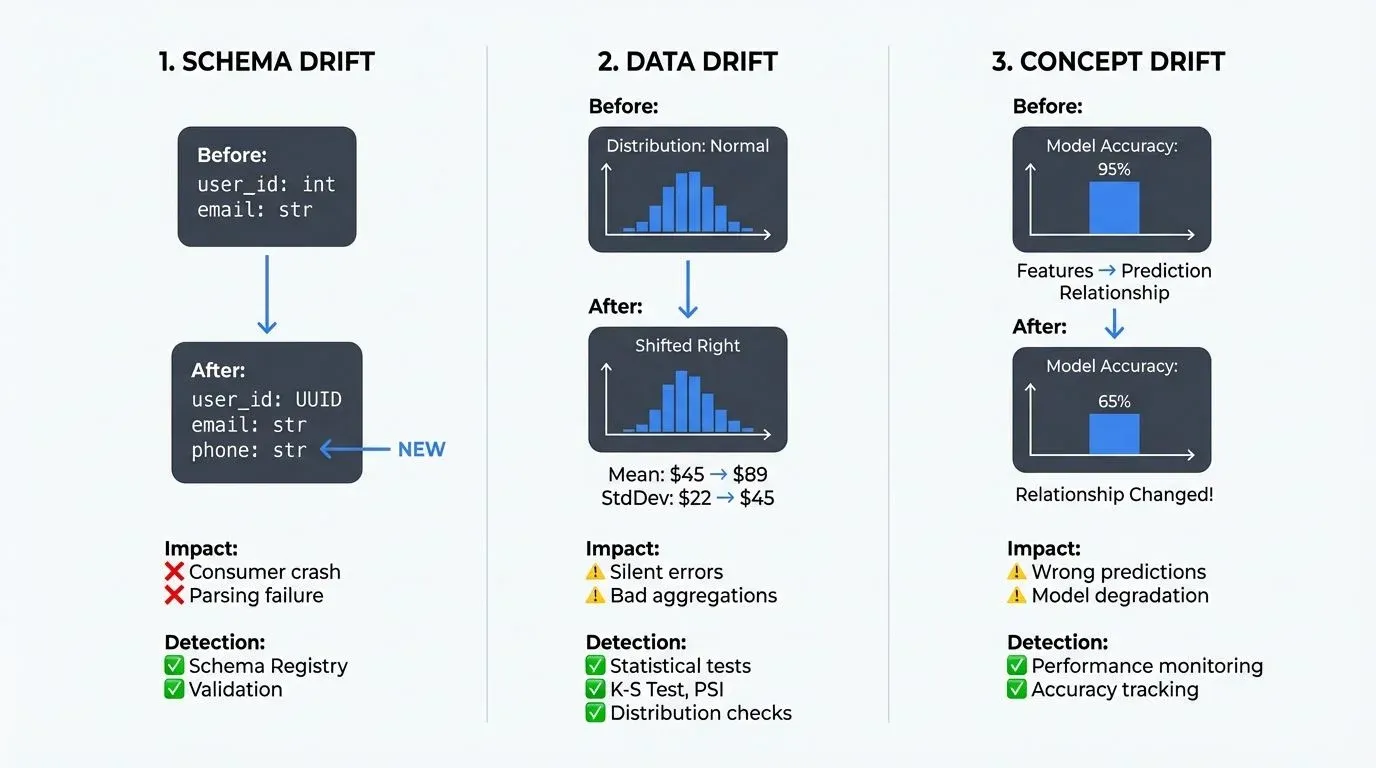
Understanding Types of Drift
Data drift is an umbrella term that encompasses several distinct types of changes, each with different implications for streaming systems.
- Schema drift occurs when the structure of your data changes. A new field appears in your event schema, an existing field's type changes from integer to string, or a required field becomes optional. In streaming systems, schema drift can break downstream consumers that expect a specific structure. For example, if a payment event suddenly includes a new
currency_codefield, consumers that parse these events may fail if they're not designed to handle unexpected fields. - Data drift (sometimes called statistical drift) refers to changes in the statistical properties of your data, the distribution, range, or patterns within the data itself. The same schema might persist, but the values flowing through your pipeline shift. Average transaction amounts might increase, user activity patterns might change, or the ratio between different event types might evolve. This type of drift is particularly insidious because it often goes undetected by schema validation alone.
- Concept drift affects machine learning models specifically. It occurs when the relationship between input features and target predictions changes over time. A fraud detection model trained on historical patterns may degrade as fraudsters adapt their tactics. The model's inputs (transaction features) might follow the same schema and distributions, but their predictive relationship to fraud has fundamentally changed. For comprehensive coverage of ML-specific drift challenges, see Model Drift in Streaming.
Root Causes of Drift in Streaming
Drift emerges from various sources, many of which are inherent to evolving business systems.
- Upstream system changes are the most common culprit. When a microservice updates its event schema without coordination, or when a new version of a mobile app starts sending additional fields, downstream streaming pipelines must adapt. These changes often happen without warning, especially in distributed organizations where teams operate independently.
- New data sources introduce variation when integrated into existing pipelines. Merging events from a newly acquired company, adding a third-party data feed, or incorporating IoT sensor data can shift overall data distributions. Each source brings its own quirks, formats, and value ranges.
- Business evolution naturally causes drift. Seasonal patterns change market behavior, new product features alter user engagement, and regulatory changes force schema modifications. A subscription service expanding to new countries might see payment methods, currencies, and purchase patterns shift dramatically.
- Bugs and data quality issues create unexpected drift. A faulty sensor might start reporting extreme values, a code bug might corrupt certain fields, or a misconfigured producer might send malformed events. Unlike intentional changes, these issues require immediate detection and remediation.
Detecting Drift in Real-Time Systems
Early detection is critical because drift's impact compounds over time. Streaming systems require continuous monitoring to catch drift before it cascades into downstream failures.
- Schema validation provides the first line of defense. Tools like Schema Registry (Confluent, AWS Glue) enforce contracts between producers and consumers. When a producer attempts to publish an event that violates the registered schema, the system rejects it immediately. This prevents incompatible data from entering your pipeline but only catches structural drift, not statistical or conceptual changes.
- Statistical monitoring tracks data distributions over time. Calculating metrics like mean, median, standard deviation, and percentile distributions for numerical fields helps identify when values shift from historical norms. For example, if your transaction amount field historically averages $47 with a standard deviation of $22, but recent data shows an average of $89 with standard deviation $45, this signals significant drift requiring investigation. For categorical fields, monitoring the frequency distribution of different values reveals when rare categories become common or vice versa.
- Automated drift detection tests compare current data windows against baseline distributions using statistical hypothesis testing:
- Kolmogorov-Smirnov (K-S) test: Compares continuous distributions (e.g., transaction amounts, response times). Use when you need to detect any change in the overall shape of the distribution. Threshold: p-value < 0.05 typically indicates significant drift.
- Chi-squared test: Detects shifts in categorical distributions (e.g., status codes, product categories). Ideal for comparing frequency distributions across categories. Works best with sufficient sample sizes in each category.
- Population Stability Index (PSI): Quantifies the shift between two distributions using a single score. PSI < 0.1 indicates minimal drift, 0.1-0.25 indicates moderate drift requiring investigation, PSI > 0.25 signals significant drift demanding immediate action.
When statistical tests exceed predefined thresholds, alerts trigger for investigation.
Here's a practical example of implementing drift detection in Python:
import numpy as np
from scipy import stats
from typing import Dict, List, Tuple
from dataclasses import dataclass
from enum import Enum
class DriftSeverity(Enum):
NONE = "none"
MODERATE = "moderate"
SIGNIFICANT = "significant"
@dataclass
class DriftResult:
field: str
severity: DriftSeverity
metric: str
value: float
threshold: float
message: str
class StreamingDriftDetector:
def __init__(self, baseline_data: List[float]):
"""Initialize with baseline distribution from training/historical data"""
self.baseline_data = np.array(baseline_data)
self.baseline_mean = np.mean(baseline_data)
self.baseline_std = np.std(baseline_data)
def detect_ks_drift(self, current_data: List[float],
threshold: float = 0.05) -> DriftResult:
"""Kolmogorov-Smirnov test for continuous distributions"""
statistic, p_value = stats.ks_2samp(self.baseline_data, current_data)
if p_value < threshold:
severity = DriftSeverity.SIGNIFICANT
message = f"Significant distribution shift detected (p={p_value:.4f})"
else:
severity = DriftSeverity.NONE
message = f"No significant drift (p={p_value:.4f})"
return DriftResult(
field="continuous_field",
severity=severity,
metric="ks_test_p_value",
value=p_value,
threshold=threshold,
message=message
)
def detect_psi_drift(self, current_data: List[float],
n_bins: int = 10) -> DriftResult:
"""Population Stability Index for distribution shift"""
# Create bins based on baseline data
_, bin_edges = np.histogram(self.baseline_data, bins=n_bins)
# Calculate distributions
baseline_counts, _ = np.histogram(self.baseline_data, bins=bin_edges)
current_counts, _ = np.histogram(current_data, bins=bin_edges)
# Convert to proportions
baseline_props = baseline_counts / len(self.baseline_data)
current_props = current_counts / len(current_data)
# Calculate PSI (avoid division by zero)
psi = 0
for baseline_prop, current_prop in zip(baseline_props, current_props):
if baseline_prop > 0 and current_prop > 0:
psi += (current_prop - baseline_prop) * np.log(current_prop / baseline_prop)
# Interpret PSI
if psi > 0.25:
severity = DriftSeverity.SIGNIFICANT
message = f"Significant drift (PSI={psi:.4f}) - immediate action required"
elif psi > 0.1:
severity = DriftSeverity.MODERATE
message = f"Moderate drift (PSI={psi:.4f}) - investigation recommended"
else:
severity = DriftSeverity.NONE
message = f"Minimal drift (PSI={psi:.4f})"
return DriftResult(
field="continuous_field",
severity=severity,
metric="psi",
value=psi,
threshold=0.1,
message=message
)
def detect_summary_stats_drift(self, current_data: List[float],
std_threshold: float = 2.0) -> List[DriftResult]:
"""Detect drift using summary statistics (mean, std deviation)"""
current_mean = np.mean(current_data)
current_std = np.std(current_data)
results = []
# Check if mean has drifted significantly (more than N standard deviations)
mean_shift = abs(current_mean - self.baseline_mean) / self.baseline_std
if mean_shift > std_threshold:
results.append(DriftResult(
field="continuous_field",
severity=DriftSeverity.SIGNIFICANT,
metric="mean_shift",
value=mean_shift,
threshold=std_threshold,
message=f"Mean shifted from {self.baseline_mean:.2f} to {current_mean:.2f} "
f"({mean_shift:.2f} standard deviations)"
))
# Check if variance has changed significantly
variance_ratio = current_std / self.baseline_std if self.baseline_std > 0 else 0
if variance_ratio > 1.5 or variance_ratio < 0.67:
severity = DriftSeverity.MODERATE if variance_ratio < 2.0 else DriftSeverity.SIGNIFICANT
results.append(DriftResult(
field="continuous_field",
severity=severity,
metric="std_ratio",
value=variance_ratio,
threshold=1.5,
message=f"Standard deviation changed from {self.baseline_std:.2f} "
f"to {current_std:.2f} (ratio={variance_ratio:.2f})"
))
if not results:
results.append(DriftResult(
field="continuous_field",
severity=DriftSeverity.NONE,
metric="summary_stats",
value=mean_shift,
threshold=std_threshold,
message="Summary statistics within expected ranges"
))
return results
# Example usage: Monitoring transaction amounts
baseline_transactions = [45.20, 52.10, 38.90, 61.50, 44.30, 55.80, 49.70,
42.60, 58.90, 47.20] * 100 # 1000 baseline samples
current_transactions = [87.40, 95.30, 102.50, 78.90, 91.20, 88.60,
93.80, 85.70, 97.10, 90.40] * 100 # 1000 current samples
detector = StreamingDriftDetector(baseline_transactions)
# Run drift detection
ks_result = detector.detect_ks_drift(current_transactions)
psi_result = detector.detect_psi_drift(current_transactions)
stats_results = detector.detect_summary_stats_drift(current_transactions)
print(f"K-S Test: {ks_result.message}")
print(f"PSI: {psi_result.message}")
for result in stats_results:
print(f"Summary Stats: {result.message}")Model performance monitoring specifically targets concept drift. Track prediction accuracy, precision, recall, and other relevant metrics on a continuous basis. When a fraud detection model's false positive rate suddenly increases or a recommendation engine's click-through rate drops, concept drift is likely occurring.
Impact on Streaming Pipelines
Drift manifests in streaming systems through various failure modes, each with different severity and visibility.
- Broken consumers are the most visible impact. When schema drift introduces incompatible changes, consuming applications crash, throw exceptions, or stall. A consumer expecting an integer
user_idfield will fail when it encounters a string UUID. These failures are immediate and obvious but disruptive to operations. - Silent data corruption is more dangerous because it goes unnoticed. When a consumer can technically parse drifted data but misinterprets it, corrupt data flows downstream. A percentage field changing from 0-100 scale to 0-1 scale might be read successfully but produce incorrect calculations. These errors accumulate in data warehouses, dashboards, and reports before anyone notices.
- Failed processing jobs occur when assumptions about data quality break down. Aggregations produce unexpected results, joins fail to find matches due to key format changes, or filtering logic becomes irrelevant. A streaming job that filters events where
status = "completed"will miss events if the upstream system changes the value tostatus = "COMPLETED". - Cascading failures happen when drift in one component triggers failures in dependent systems. A recommendation service experiencing concept drift might generate poor suggestions, leading to lower user engagement, which in turn affects analytics dashboards, A/B testing frameworks, and business metrics, all depending on the same degraded data source.
Impact on Machine Learning Models
For ML models consuming streaming data, drift directly affects prediction quality and business outcomes.
- Model degradation occurs gradually as concept drift widens the gap between training data and production reality. A model trained on pre-pandemic e-commerce behavior would struggle with post-pandemic patterns. Without retraining, prediction accuracy erodes, and business value diminishes.
- Feature distribution shifts cause data drift to affect model inputs. If a model expects average transaction values around $50 but suddenly receives values around $500 due to market changes, predictions become unreliable even if the underlying concept remains stable. Many models are sensitive to input ranges that deviate from training distributions.
- Retraining triggers must balance responsiveness against stability. Retrain too frequently and you chase noise; retrain too infrequently and drift degrades performance. Automated retraining pipelines use drift detection metrics to trigger updates when distributions shift beyond acceptable thresholds, ensuring models stay current without constant churn.
Prevention Through Governance
Preventing drift requires organizational processes and technical controls working in concert.
- Schema registries enforce contracts between data producers and consumers. By centralizing schema definitions and validating compatibility rules (backward, forward, or full compatibility), registries prevent breaking changes from reaching production. Producers must evolve schemas following compatibility guidelines, ensuring consumers continue functioning as schemas change.
- Producer-consumer contracts establish explicit agreements about data formats, value ranges, required fields, and evolution policies. These contracts, whether formal (like Protobuf definitions) or documented (like API specifications), create shared expectations. When changes are necessary, contract owners coordinate migrations rather than surprising downstream teams. For implementation guidance, see Data Contracts for Reliable Pipelines.
- Governance policies define how data can evolve. Data governance platforms enable organizations to enforce validation rules, approval workflows for schema changes, and quality checks before data reaches production streams. Policies might require backward compatibility for all schema changes, mandate documentation for new fields, or restrict who can modify critical event types.
- Testing in non-production environments validates changes before they reach production streams. Staging environments that mirror production topologies allow teams to test schema migrations, verify consumer compatibility, and assess performance impacts. Canary deployments gradually roll out changes while monitoring for drift-related issues.
Remediation Strategies
When drift occurs despite prevention efforts, effective remediation minimizes impact.
- Backward compatibility allows old consumers to continue functioning while new consumers leverage enhanced schemas. Adding optional fields with default values, widening field types (integer to long), or maintaining deprecated fields during migration periods keeps systems operational during transitions.
- Versioning strategies enable multiple schema versions to coexist. Topic naming conventions (like
payment-events-v2) or version fields within messages allow producers to migrate gradually while consumers update on their own schedules. This decoupling prevents forcing coordinated deployments across all services. - Graceful degradation designs consumers to handle unexpected data. Rather than failing on unknown fields, consumers ignore them. When expected fields are missing, they use sensible defaults or skip processing. When types mismatch, they log warnings and continue processing valid records. This resilience prevents complete failures from drift.
- Dead letter queues capture problematic events for later analysis and reprocessing. When drift causes processing failures, routing failed events to a separate queue preserves them for investigation. Teams can fix issues, update consumers, and replay failed events once systems are drift-compatible. For detailed coverage of error handling patterns, see Dead Letter Queues for Error Handling.
Here's an example of implementing drift-aware error handling with dead letter queues:
from kafka import KafkaConsumer, KafkaProducer
import json
import logging
from typing import Dict, Any, Optional
logger = logging.getLogger(__name__)
class DriftAwareConsumer:
def __init__(self):
self.consumer = KafkaConsumer(
'payment-events',
bootstrap_servers=['localhost:9092'],
value_deserializer=lambda m: json.loads(m.decode('utf-8')),
auto_offset_reset='latest',
enable_auto_commit=False
)
self.dlq_producer = KafkaProducer(
bootstrap_servers=['localhost:9092'],
value_serializer=lambda m: json.dumps(m).encode('utf-8')
)
# Expected schema baseline
self.expected_fields = {'payment_id', 'amount', 'currency', 'status'}
self.expected_types = {
'payment_id': str,
'amount': (int, float),
'currency': str,
'status': str
}
def validate_schema(self, event: Dict[str, Any]) -> Optional[str]:
"""Validate event schema and return error message if invalid"""
# Check for missing required fields
missing_fields = self.expected_fields - set(event.keys())
if missing_fields:
return f"Schema drift: Missing required fields {missing_fields}"
# Check field types
for field, expected_type in self.expected_types.items():
if field in event:
if not isinstance(event[field], expected_type):
actual_type = type(event[field]).__name__
expected = expected_type.__name__ if not isinstance(expected_type, tuple) \
else f"({', '.join(t.__name__ for t in expected_type)})"
return f"Schema drift: Field '{field}' has type {actual_type}, expected {expected}"
return None
def send_to_dlq(self, event: Dict[str, Any], error: str, topic: str):
"""Send failed event to dead letter queue with enriched metadata"""
dlq_message = {
'original_event': event,
'error': error,
'source_topic': topic,
'timestamp': event.get('timestamp', 'unknown'),
'drift_type': 'schema_drift' if 'Schema drift' in error else 'data_quality'
}
self.dlq_producer.send('payment-events-dlq', value=dlq_message)
logger.warning(f"Event sent to DLQ: {error}")
def process_with_graceful_degradation(self, event: Dict[str, Any]) -> bool:
"""Process event with graceful degradation for non-critical drift"""
try:
# Validate schema
schema_error = self.validate_schema(event)
if schema_error:
self.send_to_dlq(event, schema_error, 'payment-events')
return False
# Validate business rules with defaults for optional fields
amount = event['amount']
currency = event.get('currency', 'USD') # Default currency if missing
status = event['status']
# Validate data ranges (detect data drift)
if amount < 0 or amount > 1000000:
error = f"Data drift: Amount {amount} outside expected range [0, 1000000]"
self.send_to_dlq(event, error, 'payment-events')
return False
# Process valid event
logger.info(f"Processed payment {event['payment_id']}: "
f"{currency} {amount} - {status}")
return True
except Exception as e:
error = f"Processing error: {str(e)}"
self.send_to_dlq(event, error, 'payment-events')
return False
def run(self):
"""Main consumer loop with drift handling"""
try:
for message in self.consumer:
event = message.value
success = self.process_with_graceful_degradation(event)
if success:
self.consumer.commit()
# Note: We commit even on failure since event is in DLQ
finally:
self.consumer.close()
self.dlq_producer.close()
# Usage
if __name__ == "__main__":
logging.basicConfig(level=logging.INFO)
consumer = DriftAwareConsumer()
consumer.run()Tools and Platforms
Modern tooling helps detect, prevent, and manage drift across streaming pipelines.
- Schema registries like Confluent Schema Registry (v7.x+), AWS Glue Schema Registry, and Karapace (open-source alternative) centralize schema management and enforce compatibility rules. They integrate with streaming platforms to validate events at production time. For detailed coverage of schema management strategies, see Schema Registry and Schema Management and Schema Evolution Best Practices.
- Data quality frameworks provide comprehensive validation capabilities:
- Great Expectations (GX 1.0+): Production-grade data validation framework with 300+ built-in expectations. The August 2024 release introduced breaking API changes with a fluent interface. See Great Expectations: Data Testing Framework for streaming integration patterns.
- Soda Core: Open-source framework using YAML-based quality checks, designed for modern data stacks with native dbt and orchestration tool integration.
- Elementary Data: Observability platform for dbt with ML-based anomaly detection, automatic data quality monitoring, and lineage tracking.
- dbt Tests and Contracts: dbt 1.5+ includes native data contracts with automatic validation during transformation workflows, providing explicit interfaces between models.
Drift detection platforms specifically target statistical and concept drift:
- Evidently AI: Specialized ML monitoring for data drift, concept drift, and prediction drift with visual reports and real-time detection capabilities.
- Amazon SageMaker Model Monitor: Automated drift detection for deployed ML models with integration into AWS streaming architectures.
- Observability platforms including Datadog, Prometheus with Grafana, and OpenTelemetry-based solutions track drift metrics alongside system metrics. Dashboards visualize distribution changes, anomaly detection algorithms identify unusual patterns, and alerting systems notify teams when thresholds breach.
- Governance platforms provide centralized control over streaming data ecosystems, combining schema management, data quality validation, access control, and compliance enforcement in unified platforms to make drift prevention an organizational capability rather than individual team responsibility.
Building Drift-Resilient Systems
Managing data drift requires treating it as a normal condition rather than an exceptional failure. Streaming systems that embrace change through robust schemas, continuous monitoring, and graceful handling remain resilient as data evolves.
Start by establishing schema contracts with backward compatibility requirements. Implement statistical monitoring to detect distribution shifts early. Design consumers to degrade gracefully when encountering unexpected data. Build feedback loops that trigger model retraining when concept drift degrades predictions. Treat drift detection as seriously as error monitoring, both indicate your system's health.
For comprehensive approaches to quality management, see Building a Data Quality Framework and Automated Data Quality Testing. When drift causes incidents, refer to Data Quality Incidents for response strategies.
The organizations that succeed with streaming data don't prevent all drift — they build systems that detect, adapt to, and recover from it automatically. Resilience comes from treating drift as a normal condition, not an exceptional one.
Related Concepts
- Streaming Data Pipeline - Build drift-resilient data pipelines
- Schema Registry and Schema Management - Manage schema evolution to prevent drift
- Data Quality Dimensions: Accuracy, Completeness, and Consistency - Quality checks to detect drift
Sources
- Confluent - "Detecting and Managing Schema Drift in Apache Kafka" - https://www.confluent.io/blog/schema-registry-kafka-stream-processing-yes-virginia-you-really-need-one/
- Google Cloud - "Detecting and Managing Data Drift in ML Systems" - https://cloud.google.com/architecture/mlops-continuous-delivery-and-automation-pipelines-in-machine-learning
- Amazon SageMaker - "Model Monitor for Data Quality and Model Drift" - https://docs.aws.amazon.com/sagemaker/latest/dg/model-monitor.html
- Martin Kleppmann - "Designing Data-Intensive Applications" (O'Reilly) - Schema evolution and compatibility
- Databricks - "Monitoring Data Drift in Production ML Models" - https://www.databricks.com/blog/2019/09/18/productionizing-machine-learning-from-deployment-to-drift-detection.html