Policy Enforcement in Streaming: Automated Governance for Real-Time Data
In traditional batch processing systems, data quality checks and governance controls are applied at specific points, before loading, after transformation, during validation phases. But streaming systems operate continuously, with events flowing through pipelines 24/7. This constant flow demands a different approach: policy enforcement that operates automatically, in real-time, as data moves through the system. 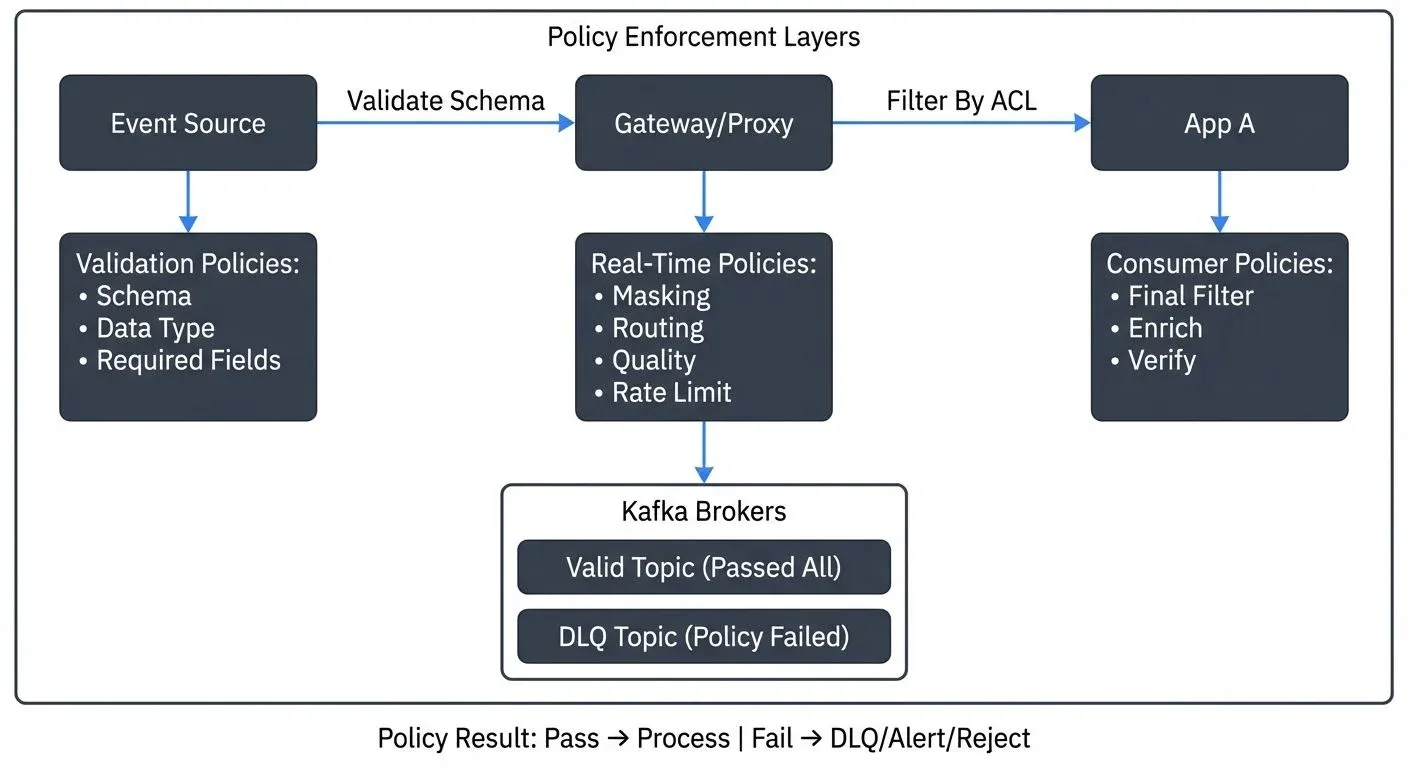
Policy enforcement in streaming means applying rules, validations, and transformations automatically as events flow from producers to consumers. These policies ensure that every message meets quality standards, complies with security requirements, and follows organizational governance rules — without manual intervention and without slowing down the data pipeline.
A simple example: A policy might automatically reject any order event where the order_amount field is missing or negative, preventing downstream services from processing invalid data. Another policy might automatically mask credit card numbers in payment events before they reach analytics consumers, protecting sensitive data without requiring changes to producing applications.
Understanding Streaming Policies
A streaming policy is an automated rule that evaluates, transforms, or routes events as they flow through the system. Unlike application-level validation that happens in specific services, streaming policies operate at the infrastructure level, affecting all data that passes through enforcement points.
- Core policy categories include:
- Validation policies verify that events meet structural and semantic requirements. Schema validation ensures messages conform to expected formats. Data quality rules check for null values, invalid ranges, or malformed data. Format enforcement verifies dates, emails, phone numbers, and other typed fields follow conventions.
- Transformation policies modify events to meet standards or protect sensitive data. Field masking obscures personally identifiable information. Standardization rules convert values to canonical formats. Enrichment policies add context or metadata to events as they flow through the system.
- Routing policies determine where events should go based on their content or metadata. Topic routing directs messages to different destinations based on classification. Filtering policies prevent certain events from reaching specific consumers. Rate limiting controls how many events flow to particular endpoints.
- Security policies protect data and enforce access controls. Encryption policies ensure sensitive data is encrypted in transit or at rest. Authentication rules verify producer and consumer identities. Authorization policies control which services can access specific data streams.
Policy Enforcement Points
Policies can be enforced at different locations in the streaming architecture, each with distinct trade-offs.
Producer-Side Enforcement
Implementing policies in producers, the applications generating events, provides the earliest point of validation. Producers can validate schemas, check data quality, and apply masking before sending events to the streaming platform.
This approach prevents invalid data from ever entering the system. Failed validation can trigger immediate retries or error handling in the producing application. However, it requires implementing and maintaining policy logic across every producing service, leading to duplication and inconsistency risks.
Broker-Side Enforcement
Applying policies at the broker level, in the streaming platform itself, centralizes enforcement. Kafka brokers, for example, can validate schemas using Schema Registry integration, enforce quotas to prevent resource exhaustion, and apply retention policies to manage storage.
Broker-side enforcement provides a single point of control, ensuring all data flowing through the platform meets standards regardless of producer implementation. But broker-level validation adds processing overhead and can create bottlenecks if not carefully designed.
Consumer-Side Enforcement
Policies enforced in consumers, the applications reading events, provide the final validation layer. Consumers can apply business-specific validation, perform additional transformations, or filter events based on their specific needs.
This approach allows different consumers to apply different policies to the same data stream. A analytics consumer might accept approximate data while a billing consumer requires exact values. However, consumer-side enforcement doesn't prevent invalid data from entering the system, and duplicating validation across consumers wastes resources.
Multi-Layer Strategy
Production systems typically combine enforcement points. Critical validations like schema compliance and security controls operate at the broker level, ensuring platform-wide consistency. Business-specific rules execute at consumer level, allowing flexibility for different use cases. Producers perform basic validation to catch obvious errors early.
Implementation Approaches
Several technical approaches enable policy enforcement in streaming systems.
Interceptors
Producer and consumer interceptors are plugins that execute automatically when messages are sent or received. An interceptor can inspect messages, modify them, record metrics, or reject invalid data.
Interceptors operate within the client application but execute transparently, application code doesn't need explicit calls. A schema validation interceptor can verify every produced message against Schema Registry before allowing transmission. A masking interceptor can obscure sensitive fields in every consumed message before passing data to application logic.
Single Message Transforms
Kafka Connect uses Single Message Transforms (SMTs) to apply policies during data integration. SMTs are lightweight transformations that execute as data flows through connectors, allowing modification without writing custom code.
SMTs can mask fields, rename attributes, route messages to different topics, filter events, or add metadata. A connector pulling customer data from a database can apply a masking SMT to obscure email addresses before writing to Kafka. Another SMT can add a timestamp indicating when the event was captured.
Example SMT configuration for masking sensitive fields:
{
"name": "customer-source-connector",
"config": {
"connector.class": "io.debezium.connector.postgresql.PostgresConnector",
"transforms": "maskEmail,maskPhone",
"transforms.maskEmail.type": "org.apache.kafka.connect.transforms.MaskField$Value",
"transforms.maskEmail.fields": "email",
"transforms.maskEmail.replacement": "***@***.com",
"transforms.maskPhone.type": "org.apache.kafka.connect.transforms.MaskField$Value",
"transforms.maskPhone.fields": "phone_number",
"transforms.maskPhone.replacement": "XXX-XXX-XXXX"
}
}Stream Processing
Stream processing frameworks like Kafka Streams, Apache Flink, or Apache Beam provide powerful policy enforcement capabilities through continuous processing topologies.
A stream processing application can consume from one topic, apply complex validation logic, enrich events with reference data, filter based on sophisticated rules, and produce to multiple output topics based on routing policies. This approach handles policies requiring stateful processing, joins across streams, or aggregations over time windows.
Example policy implementation in Kafka Streams:
StreamsBuilder builder = new StreamsBuilder();
KStream<String, Order> orders = builder.stream("orders");
// Policy: Validate order amounts and split into valid/invalid streams
Map<String, KStream<String, Order>> branches = orders.split(Named.as("branch-"))
.branch((key, order) -> order.getAmount() != null && order.getAmount() > 0,
Branched.as("valid"))
.branch((key, order) -> true, Branched.as("invalid"))
.noDefaultBranch();
// Valid orders proceed to processing
branches.get("branch-valid").to("orders-validated");
// Invalid orders go to dead letter queue for investigation
branches.get("branch-invalid").to("orders-dlq");Stream processors can also publish policy violations to dedicated topics for monitoring and alerting, creating an audit trail of governance enforcement.
Schema Registry Integration
Schema Registry provides centralized schema management and compatibility checking. When configured with Kafka, it enforces schema policies automatically.
Producers serialize data using Schema Registry, which validates that schemas are registered and compatible with previous versions using formats like Avro, Protobuf, or JSON Schema. Consumers deserialize using the same registry, ensuring they can parse messages. Compatibility modes (backward, forward, full) define what schema changes are permitted, preventing breaking changes from reaching production.
Policy-as-Code with Open Policy Agent
Modern streaming governance increasingly adopts policy-as-code approaches using dedicated policy engines like Open Policy Agent (OPA) or AWS Cedar. These engines separate policy logic from application code, enabling centralized management and consistent enforcement.
OPA uses the Rego language to express policies declaratively:
package kafka.authz
# Policy: Only payment services can produce to payment topics
default allow_produce = false
allow_produce {
input.principal.name == "payment-service"
startswith(input.topic, "payments.")
}
# Policy: Sensitive topics require encryption
violation[{"msg": msg}] {
startswith(input.topic, "pii.")
not input.encryption_enabled
msg := sprintf("Topic %v requires encryption", [input.topic])
}OPA integrates with Kafka through interceptors or proxy layers, evaluating policies on every request. Policy decisions can enforce authorization, validate message structure, or require specific configurations based on topic classification.
Streaming Data Gateways
Conduktor Gateway, a Kafka proxy, and similar streaming data gateways provide a modern approach to centralized policy enforcement. Rather than implementing policies in every producer and consumer, a gateway sits between clients and brokers, intercepting all traffic.
Gateways enable:
- Centralized policy enforcement without modifying applications
- Field-level encryption and masking applied transparently
- Schema validation before messages reach brokers
- Virtual topics that apply transformations or filters
- Audit logging of all data access patterns
- Multi-tenancy isolation with quota enforcement per team
This proxy-based architecture is particularly valuable in 2025 as organizations implement data mesh patterns where multiple teams produce and consume data independently but must comply with organization-wide governance policies.
Schema Governance Policies
Schema policies maintain structural integrity across the streaming platform.
- Compatibility rules prevent breaking changes. Backward compatibility ensures new schemas can read old data, critical when consumers haven't upgraded yet. Forward compatibility ensures old schemas can read new data, important when producers deploy first. Full compatibility requires both, while transitive variants extend compatibility across all historical versions. See schema evolution best practices for detailed guidance.
- Required fields ensure critical data is always present. Marking fields as required in Avro, Protobuf, or JSON Schema prevents producers from omitting essential information.
- Naming conventions standardize field names, avoiding confusion. Policies can enforce camelCase or snake_case, prevent abbreviations, or require specific prefixes for certain field types.
- Documentation requirements can mandate descriptions for schemas and fields, improving discoverability and understanding across teams. These documentation policies are essential components of data contracts between producers and consumers.
Security and Privacy Policies
Security policies protect sensitive data as it flows through streaming systems.
- Encryption policies ensure data protection. Encryption in transit using TLS protects data moving between producers, brokers, and consumers. Encryption at rest protects data stored in broker logs. End-to-end encryption can protect data even from platform administrators by encrypting payloads before producing.
- Field-level masking obscures sensitive data based on rules. A policy might mask credit card numbers for all consumers except payment processing services, or hash email addresses for analytics while providing plaintext to customer communication systems.
- Field-level encryption protects sensitive data end-to-end, even from platform administrators. Modern approaches use envelope encryption where data encryption keys (DEKs) encrypt individual fields, and key encryption keys (KEKs) stored in key management services (like AWS KMS or HashiCorp Vault) protect the DEKs. This enables selective decryption, only consumers with appropriate KEK access can decrypt specific fields, while the streaming platform handles encrypted data opaquely.
- Access control policies define who can produce to or consume from topics. Combined with authentication and authorization mechanisms like SASL (Simple Authentication and Security Layer) and ACLs (Access Control Lists), these policies enforce principle of least privilege, ensuring services access only the data they need.
- Audit logging records all policy decisions, creating compliance trails. Logs capture what policies were evaluated, whether events passed or failed, and what actions were taken. See audit logging for streaming platforms for implementation patterns.
Operational Policies
Operational policies maintain platform health and resource efficiency.
- Retention policies control how long data remains available. Time-based retention deletes events after a specified duration. Size-based retention limits topic storage. Compaction-based retention keeps only the latest value for each key, supporting changelog semantics (where topics represent the current state of entities, similar to database change logs).
- Quota policies prevent resource exhaustion. Producer quotas limit how much data applications can write per second. Consumer quotas limit read bandwidth. Request quotas prevent any single client from overwhelming broker capacity.
- Replication policies ensure durability and availability. Minimum in-sync replicas requirements prevent data loss by ensuring sufficient replicas acknowledge writes before considering them successful.
Policy-as-Code and Governance Integration
Modern policy enforcement treats policies as code, applying software engineering practices to governance.
- Version control stores policy definitions in Git alongside application code. Changes go through code review, creating accountability and knowledge sharing. History tracking shows how policies evolved over time.
- CI/CD integration validates and deploys policies automatically. Automated tests verify policies work as expected before deployment. Staging environments allow testing policy changes against realistic data before production rollout.
- Declarative policy languages like Rego (used by Open Policy Agent) or proprietary DSLs express policies as readable, testable specifications rather than scattered imperative code.
- Policy testing frameworks enable comprehensive validation before production deployment. Tests verify that policies correctly allow valid data, reject invalid data, and handle edge cases:
# Testing OPA policies with sample inputs
opa test policy/ tests/ -v
# Example test case
test_payment_topic_access {
allow_produce with input as {
"principal": {"name": "payment-service"},
"topic": "payments.transactions"
}
not allow_produce with input as {
"principal": {"name": "analytics-service"},
"topic": "payments.transactions"
}
}Policy observability tracks enforcement in production through metrics, logs, and alerts:
- Enforcement metrics measure policy evaluation latency, success/failure rates, and throughput impact
- Violation alerts trigger when policies block invalid data, indicating potential producer issues
- Compliance dashboards visualize policy coverage across topics and consumer groups
- Audit trails provide forensic analysis of who accessed what data and which policies were applied
- Governance platforms like Conduktor provide centralized policy management across Kafka environments, allowing teams to define data quality rules, security policies, and operational controls through unified interfaces that automatically enforce them across the streaming infrastructure. These platforms combine policy definition, deployment, testing, and monitoring in a single workflow, ensuring consistency and simplifying auditing for regulatory requirements. Integration with data governance frameworks ensures alignment with organizational policies and responsibilities.
- Compliance reporting generates documentation showing policy enforcement status. Automated reports demonstrate that data handling meets regulatory requirements like GDPR (General Data Protection Regulation), HIPAA (Health Insurance Portability and Accountability Act), or SOX (Sarbanes-Oxley). Violation tracking identifies patterns requiring attention.
Conduktor Traffic Control Policies
Modern streaming platforms require policy enforcement mechanisms that operate at scale without requiring changes to applications. Conduktor Traffic Control Policies provide a centralized framework for enforcing rate limits (producer/consumer throughput, connection limits), configuration policies (replication factors, retention periods, schema requirements), and access control policies (read-only access, client ID requirements) through automated rules that intercept traffic at the gateway layer.
The key advantage is centralized enforcement without application modification, policies apply across all producers and consumers automatically. Configuration policies shift enforcement from documentation to automated validation, eliminating configuration drift. Traffic Control Policies integrate with policy-as-code workflows through version-controlled configuration deployed via CI/CD. For implementation guidance, see Traffic Control Policies.
Balancing Enforcement and Performance
Policy enforcement introduces processing overhead. Each validation, transformation, or check consumes CPU cycles and adds latency. Effective policy implementation balances governance needs against performance requirements.
- Selective enforcement applies expensive policies only where necessary. Critical financial data might undergo extensive validation while operational metrics receive lighter checks. High-volume topics might use simpler policies than low-volume sensitive topics.
- Async validation separates policy enforcement from the critical path. Events flow through quickly, while a parallel stream processing application validates compliance and raises alerts for violations. This trades immediate enforcement for throughput, appropriate when detecting violations quickly matters more than preventing them entirely.
- Policy optimization ensures rules execute efficiently. Compiled policies run faster than interpreted ones. Early exit strategies skip remaining checks once a violation is detected. Caching reduces redundant lookups or computations.
Conclusion
Policy enforcement transforms streaming platforms from simple message buses into governed data infrastructures. Automated policies ensure data quality, enforce security requirements, and maintain operational health — all in real-time, without manual intervention.
Effective policy enforcement combines technical implementation with organizational process. Policies must be designed thoughtfully, balancing governance needs against system performance. They should be expressed declaratively, versioned like code, and deployed through automated pipelines. Enforcement should happen at appropriate points in the architecture: broker-side for universal rules, producer-side for early validation, consumer-side for specific needs.
As streaming systems grow in scale and importance, robust policy enforcement becomes essential. It is the foundation for trustworthy real-time data, enabling organizations to move fast while maintaining control, democratize data access while protecting privacy, and meet compliance obligations without sacrificing agility.
Related Concepts
- Data Governance Framework: Roles and Responsibilities - Organizational structure for policy management
- Audit Logging for Streaming Platforms - Recording policy enforcement decisions
- Data Quality Dimensions: Accuracy, Completeness, and Consistency - Quality policies for streaming data
Sources and References
- Apache Kafka Documentation - Security. Apache Software Foundation. https://kafka.apache.org/documentation/#security - Official documentation covering authentication, authorization, encryption, and security policies in Kafka.
- Confluent Schema Registry Documentation. Confluent, Inc. https://docs.confluent.io/platform/current/schema-registry/index.html - Comprehensive guide to schema governance, compatibility policies, and validation in streaming systems.
- Open Policy Agent (OPA) Documentation. Cloud Native Computing Foundation. https://www.openpolicyagent.org/docs/latest/ - Framework for policy-as-code implementation applicable to streaming data governance.
- Stopford, Ben. "Designing Event-Driven Systems." O'Reilly Media, 2018. Chapters on data governance, schema evolution, and policy enforcement patterns in event streaming architectures.
- Kafka Governance Best Practices. Various platform documentation covering centralized policy management, data quality enforcement, and compliance automation for Kafka environments.