Data Quality Incidents: Detection, Response, and Prevention
What is a Data Quality Incident?
A data quality incident occurs when data flowing through streaming systems fails to meet established quality standards, resulting in impact to downstream consumers, analytics, or business operations. Unlike normal statistical variance or expected fluctuations in data patterns, incidents represent significant deviations that require human intervention and remediation.
In streaming architectures, data quality incidents are particularly critical because they propagate in real-time to multiple downstream systems. A schema violation in a Kafka topic might cascade to break consumers, corrupt data lakes, and trigger false alerts across monitoring systems. The velocity and volume of streaming data mean that incidents can affect millions of records within minutes if not detected and contained quickly.
The key distinction between an incident and normal variance lies in impact and deviation from acceptable bounds. A 5% increase in null values might be within normal operating parameters, while a sudden 50% spike in nulls represents an incident requiring immediate attention. Organizations define these thresholds through Service Level Objectives (SLOs), measurable targets for system reliability and data quality, and data quality contracts that specify acceptable ranges for metrics like completeness, accuracy, and timeliness.
For detailed coverage of these quality dimensions, see Data Quality Dimensions. 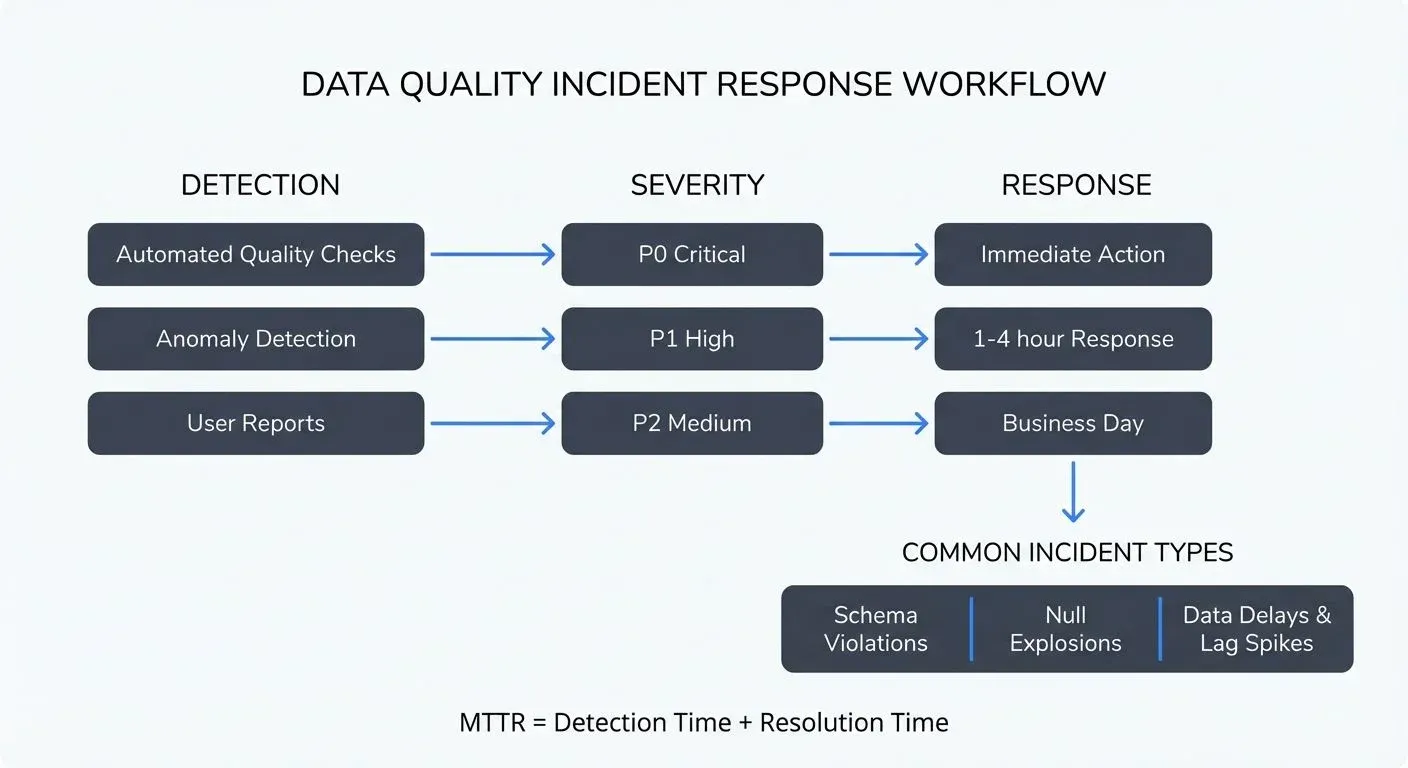
Types of Data Quality Incidents
Schema Violations and Format Errors
Schema violations occur when incoming data doesn't match the expected structure. In streaming systems using Apache Kafka with Schema Registry, this might manifest as:
- Producers sending data with missing required fields
- Type mismatches (sending strings where integers are expected)
- Addition of unexpected fields that break strict schema enforcement
- Incompatible schema evolution (non-backward compatible changes)
Modern Schema Registry (2025) offers advanced compatibility modes like FULL_TRANSITIVE that check compatibility across all schema versions, preventing incidents from incompatible evolution. These incidents often cause immediate consumer failures, as applications cannot deserialize or process malformed records.
For comprehensive schema management practices, see Schema Registry and Schema Management and Schema Evolution Best Practices.
Null Explosions and Missing Data
A null explosion happens when a normally populated field suddenly contains null or missing values at abnormally high rates. Common causes include:
- Upstream service failures that result in partial data
- Configuration errors in data producers
- Database replication lag causing incomplete record retrieval
- API timeouts leading to default null values
Missing critical business data (customer IDs, timestamps, transaction amounts) can invalidate entire analytical pipelines and business reports.
Duplicate Records
Duplicates in streaming systems arise from:
- Producer retries due to transient network failures
- At-least-once delivery semantics without proper deduplication
- Replay scenarios where data is reprocessed
- Multiple producers writing the same logical events
While some duplication is acceptable in idempotent systems, excessive duplicates skew aggregations, inflate metrics, and waste processing resources.
Data Delays and Lag Spikes
Timeliness incidents occur when:
- Event-time timestamps show growing lag from processing-time
- Producer throughput drops below expected rates
- Network partitions delay message delivery
- Consumer lag grows beyond acceptable thresholds (e.g., > 1 hour for near-real-time systems)
Delays can render time-sensitive applications ineffective, such as fraud detection or real-time recommendations.
Modern monitoring (2025): Tools like Kafka Lag Exporter provide Prometheus metrics for consumer lag with configurable alerting thresholds. Kafka 4.0's KRaft mode eliminates ZooKeeper-related latency issues, reducing incident surface area. For detailed consumer lag strategies, see Consumer Lag Monitoring.
Detection Methods
Automated Quality Checks and Validation Rules
Proactive monitoring involves continuous validation of streaming data against defined rules:
- Completeness checks: Monitor null rates, record counts, and required field presence
- Accuracy checks: Validate data ranges, enum values, and business rule compliance
- Consistency checks: Verify referential integrity and cross-field relationships
- Timeliness checks: Measure event-time vs. processing-time lag
- Example validation with Soda Core (2025):
# checks.yml
checks for orders_stream:
- missing_count(order_id) = 0
- invalid_percent(status) < 1%:
valid values: ['pending', 'completed', 'cancelled']
- freshness(event_timestamp) < 5m
- duplicate_count(order_id) < 0.1%Governance platforms like Conduktor enable policy enforcement at the Kafka protocol level, validating data quality before it enters topics and preventing bad data from polluting streams. Conduktor Gateway, a Kafka proxy, can intercept messages, apply validation rules, and route violations to dead letter queues automatically. For practical implementation, see Enforcing Data Quality with Conduktor and Observing Data Quality.
For comprehensive testing strategies, see Automated Data Quality Testing and Building a Data Quality Framework.
Anomaly Detection and Statistical Monitoring
Beyond rule-based validation, statistical anomaly detection identifies unusual patterns:
- Standard deviation analysis for numeric fields
- Time-series forecasting to detect unexpected volume changes
- Distribution drift detection comparing current data to historical baselines
- Outlier detection for individual record values
2025 ML-based detection: Modern observability platforms integrate machine learning models trained on historical data patterns to automatically flag deviations. OpenTelemetry provides standardized instrumentation for streaming applications, enabling correlation of data quality metrics with infrastructure signals. These systems can detect subtle incidents like gradual data drift that rule-based checks might miss.
For related drift patterns, see Data Drift in Streaming and Model Drift in Streaming.
Preventing Incidents with Data Quality Policies
Conduktor Data Quality Policies provide systematic prevention of data quality incidents by creating Rules that define expected message formats and content. These attach to specific topics, enabling centralized quality enforcement. In observe-only mode, Policies record violations without impacting flow; when integrated with Conduktor Gateway, they validate records before production, blocking non-compliant messages or marking them with violation metadata.
This centralized approach catches schema violations, null explosions, and format errors at the infrastructure level rather than requiring each producer to implement validation independently, ensuring consistent quality standards. For implementation guidance, see Data Quality Policies.
User Reports and Feedback Loops
Despite automated monitoring, downstream consumers often detect quality issues first:
- Dashboard users noticing missing or incorrect data
- Business stakeholders questioning unexpected metric changes
- Consumers reporting processing errors or unexpected behavior
Establishing clear channels for users to report suspected data quality issues creates a critical feedback loop for incident detection.
Severity Classification and Incident Response
Severity Levels
Organizations typically classify incidents across four severity levels:
- Critical (P0): Complete data loss, major schema breaks, or incidents affecting critical business operations. Requires immediate response and escalation.
- High (P1): Significant data quality degradation affecting multiple systems or important analytical workloads. Response within 1-4 hours.
- Medium (P2): Moderate quality issues with workarounds available or limited impact. Response within business day.
- Low (P3): Minor issues with minimal impact. Tracked for resolution in normal workflow.
Incident Response Process
A structured response process ensures consistent handling:
- 1. Detect: Automated monitoring or user report identifies potential incident
- 2. Assess: On-call engineer evaluates severity, scope, and impact
- 3. Contain: Implement immediate mitigation to prevent further damage (pause producers, reroute consumers to dead letter queues, isolate affected data)
- 4. Resolve: Identify root cause and implement fix (repair data, deploy corrected code, adjust configurations)
- 5. Review: Conduct post-mortem to prevent recurrence
For error isolation strategies, see Dead Letter Queues for Error Handling.
Root Cause Analysis for Streaming Incidents
Effective RCA in streaming systems requires examining multiple layers:
- Producer layer: Code changes, configuration updates, dependency failures
- Infrastructure layer: Network issues, broker failures, resource exhaustion
- Schema layer: Evolution mistakes, registry failures
- Data source layer: Upstream system changes, database issues
Modern tooling (2025): OpenTelemetry distributed tracing connects data quality incidents across the entire pipeline, from producer instrumentation through Kafka brokers to consumer processing. Audit logging platforms capture all configuration changes and schema modifications with timestamps, enabling precise correlation with incident onset. Kafka 4.0's improved observability APIs provide richer metadata for incident investigation.
For implementation guidance, see Distributed Tracing for Kafka Applications and Audit Logging for Streaming Platforms.
Communication and Post-Mortems
Stakeholder Notification Strategies
Timely communication prevents confusion and enables affected teams to take protective action:
- Immediate notification: Alert directly impacted consumers and data owners
- Status page updates: Provide public incident status for broader organization
- Regular updates: Share progress every 30-60 minutes during active incidents
- Resolution notification: Confirm when normal operations resume and any required actions
Use targeted communication channels (Slack, PagerDuty, email) based on severity and audience.
Blameless Post-Mortem Practices
Post-incident reviews focus on system improvement rather than individual blame:
- Document timeline: Reconstruct event sequence with precise timestamps
- Identify root cause: Use "five whys" to uncover underlying systemic issues
- Analyze contributing factors: Environmental, organizational, or technical factors that enabled the incident
- Define action items: Specific, assignable improvements with owners and deadlines
- Share learnings: Distribute post-mortem widely to improve organizational knowledge
Blameless culture encourages transparency and prevents future incidents by addressing systemic weaknesses rather than individual errors.
Prevention and Metrics
Data Contracts and Validation
Data contracts define explicit agreements between producers and consumers about data structure, quality, and SLAs. Contracts specify:
- Required and optional fields
- Data types and formats
- Acceptable value ranges
- Quality thresholds (max null rate, duplicate rate)
- Timeliness guarantees
Modern contract enforcement (2025): Governance platforms like Conduktor enable enforcement of data policies and contracts at the infrastructure level, validating data before it reaches consumers and providing early detection of violations. Conduktor Gateway acts as an intelligent proxy layer, inspecting messages in real-time against contract definitions and preventing violating messages from entering topics.
Schema-based approaches using Protobuf with buf or Avro with Schema Registry provide compile-time and runtime validation, catching contract violations before deployment.
For contract implementation patterns, see Data Contracts for Reliable Pipelines.
Testing Strategies
Preventing incidents requires comprehensive testing:
- Schema compatibility tests: Verify evolution doesn't break consumers
- Data quality unit tests: Validate transformation logic with edge cases using dbt tests or Great Expectations 1.0+
- Integration tests: Test producer-consumer interactions with realistic data
- Chaos engineering: Intentionally inject failures to verify detection and recovery
2025 testing practices: Modern CI/CD pipelines integrate data quality gates that prevent deployment of code or schema changes that violate contracts. Conduktor Gateway enables controlled chaos testing by injecting schema violations, delays, or duplicates in non-production environments to validate incident response procedures.
For testing methodologies, see Testing Strategies for Streaming Applications, Great Expectations Data Testing Framework, and Chaos Engineering for Streaming Systems.
Key Metrics
Three critical metrics measure incident management effectiveness:
- MTTD (Mean Time to Detect): Average time from incident occurrence to detection. Target: < 5 minutes for critical systems.
- MTTR (Mean Time to Resolve): Average time from detection to full resolution. Target varies by severity but < 1 hour for P0 incidents.
- Incident Frequency: Number of quality incidents per week/month, categorized by type and severity. Track trends to measure prevention effectiveness.
Building Incident Response Playbooks
Creating Runbooks for Common Scenarios
Playbooks provide step-by-step procedures for frequent incident types:
Schema violation playbook:
- Identify affected topic and producer
- Check Schema Registry for recent changes
- Pause affected producer
- Validate consumer compatibility
- Roll back schema or update producer code
- Resume processing and verify recovery
Null explosion playbook:
- Query recent data to quantify impact
- Identify affected fields and producers
- Check upstream data sources
- Implement filtering or default values in consumers
- Fix root cause in producer
- Backfill missing data if required
Duplicate detection playbook:
- Measure duplicate rate using unique keys
- Identify duplicate source (replay, retry, multiple producers)
- Implement deduplication in affected consumers
- Correct producer configuration
- Clean duplicate records if necessary
Tools and Automation
Effective incident response (2025) relies on modern tooling:
- Automated alerting: PagerDuty, Opsgenie for on-call escalation with intelligent routing
- Monitoring and observability:
- Grafana, Datadog for real-time visibility into Kafka metrics
- Kafka Lag Exporter for Prometheus-based consumer lag monitoring
- OpenTelemetry for distributed tracing across streaming pipelines
- Data quality platforms:
- Soda Core for declarative data quality checks
- Great Expectations 1.0+ for Python-based validation
- dbt tests for transformation quality validation
- Governance and policy enforcement:
- Conduktor for Kafka cluster management, governance, and monitoring
- Conduktor Gateway for protocol-level policy enforcement and chaos testing
- Runbook automation: Scripts and Kubernetes operators for common mitigation actions
- Collaboration tools: Slack, Microsoft Teams for incident coordination
Kafka 4.0 benefits: KRaft mode simplifies incident response by eliminating ZooKeeper dependencies, reducing operational complexity and failure modes. Improved metrics APIs provide richer incident context.
Automation reduces MTTD and MTTR by enabling instant response to common scenarios. For operational best practices, see Kafka Cluster Monitoring and Metrics and DataOps for Streaming.
Conclusion
Data quality incidents in streaming systems require proactive detection, rapid response, and systematic prevention. Comprehensive monitoring, clear severity classification, structured response processes, and blameless post-mortems all reduce the impact of quality issues.
Automated validation combined with statistical anomaly detection and well-defined playbooks lets teams detect incidents quickly and resolve them efficiently. Measuring MTTD, MTTR, and incident frequency shows where to focus prevention efforts.
Current best practices emphasize prevention through data contracts, governance platforms like Conduktor, and testing with modern frameworks (Soda Core, Great Expectations 1.0+, dbt tests). Kafka 4.0's KRaft mode and improved observability reduce incident complexity, while OpenTelemetry provides end-to-end visibility across distributed streaming architectures.
For understanding the relationship between data quality and observability, see Data Quality vs Data Observability: Key Differences. For incident management patterns, refer to Data Incident Management and Root Cause Analysis.
Related Concepts
- Building a Data Quality Framework - Systematic prevention strategies
- Automated Data Quality Testing - Early detection through testing
- Consumer Lag Monitoring - Detecting freshness-related incidents