Data Classification and Tagging Strategies
In data architectures built on streaming platforms like Apache Kafka, data classification and tagging are core parts of a data governance framework. As organizations process millions of events per second, understanding what data flows through your systems and how sensitive it is matters for compliance, security, and operational efficiency. 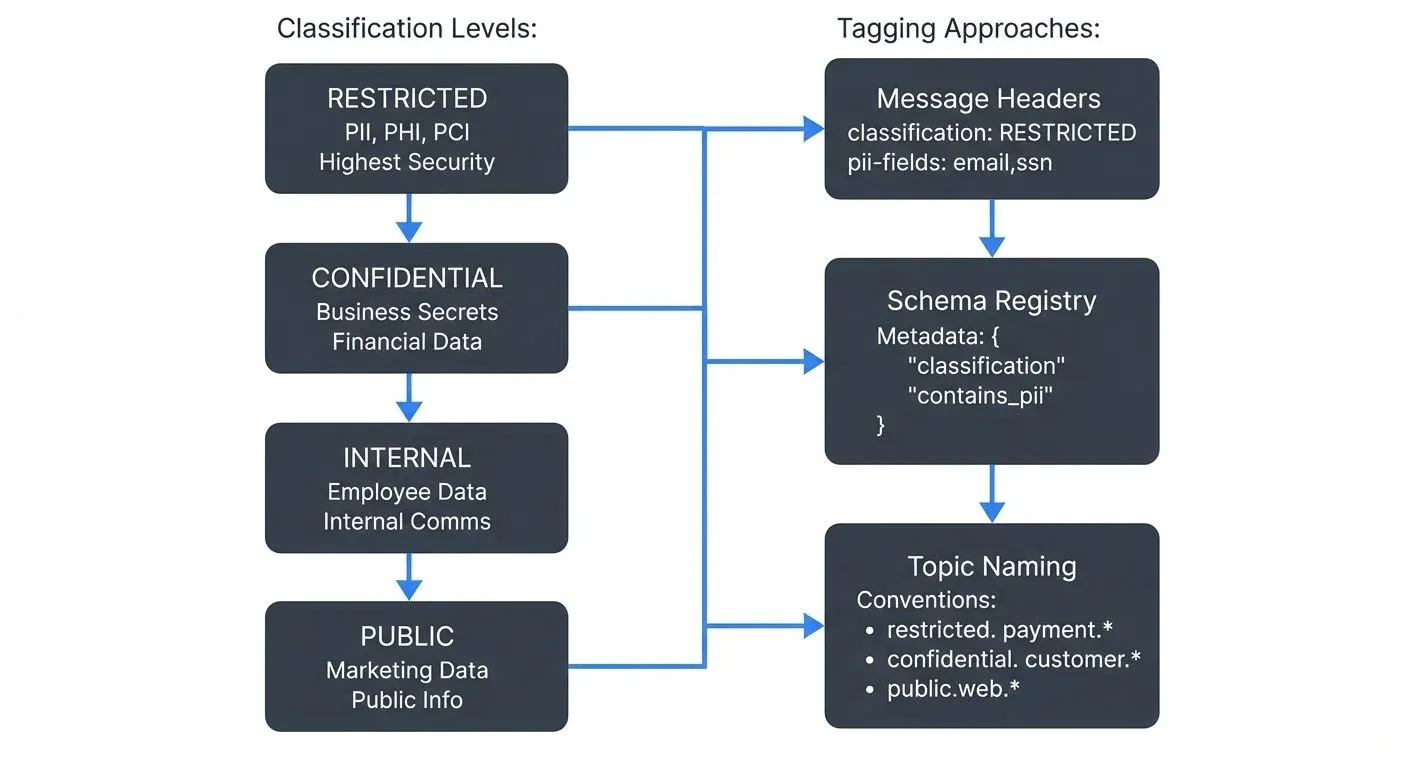
Understanding Data Classification
Data classification is the systematic organization of data into categories based on sensitivity, regulatory requirements, and business criticality. This process enables organizations to apply appropriate security controls, access policies, and retention strategies to different data types.
For Data Governance Officers and Security Engineers, classification serves multiple purposes: it reduces risk exposure, ensures compliance with regulations like GDPR and CCPA (see GDPR Compliance for Data Teams), and optimizes resource allocation by focusing protection efforts where they matter most.
Classification Levels and Frameworks
A well-designed classification framework typically includes four to five levels:
- Public Data: Information that can be freely shared without risk, such as marketing materials or publicly available product information.
- Internal Data: Information meant for internal use only, like employee directories or internal communications, which could cause minor inconvenience if exposed.
- Confidential Data: Sensitive business information such as financial records, strategic plans, or customer data that could cause significant harm if disclosed.
- Restricted Data: Highly sensitive information including personally identifiable information (PII), protected health information (PHI), payment card data, or trade secrets requiring the highest level of protection. For detailed PII handling strategies, see PII Detection and Handling in Event Streams.
Some organizations add a fifth tier for regulated data requiring specific compliance controls under frameworks like HIPAA, PCI-DSS, or SOX.
Tagging Strategies for Streaming Data
In streaming architectures, classification metadata must travel with the data itself. Traditional database-centric approaches don't translate directly to event streams, requiring new strategies.
Message Header Tagging
Apache Kafka supports message headers (introduced in Kafka 0.11+, enhanced in Kafka 4.0 with KRaft mode), making them ideal for carrying classification metadata. For comprehensive Kafka header usage patterns, see Using Kafka Headers Effectively. Each event can include headers like:
classification: CONFIDENTIAL
pii-fields: email,phone,ssn
retention-policy: 90-days
compliance-tags: GDPR,CCPAThis approach keeps classification data separate from business payloads while ensuring it remains available to downstream consumers and governance tools.
Here's a complete example of how to set classification headers when producing messages in Java:
import org.apache.kafka.clients.producer.*;
import org.apache.kafka.common.header.Headers;
import org.apache.kafka.common.header.internals.RecordHeader;
import java.nio.charset.StandardCharsets;
import java.util.Properties;
public class ClassifiedProducer {
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
try (KafkaProducer<String, String> producer = new KafkaProducer<>(props)) {
String topic = "confidential.customer.events";
String key = "customer-123";
String value = "{\"email\":\"user@example.com\",\"phone\":\"+1234567890\"}";
ProducerRecord<String, String> record = new ProducerRecord<>(topic, key, value);
// Add classification headers
Headers headers = record.headers();
headers.add(new RecordHeader("classification",
"CONFIDENTIAL".getBytes(StandardCharsets.UTF_8)));
headers.add(new RecordHeader("pii-fields",
"email,phone".getBytes(StandardCharsets.UTF_8)));
headers.add(new RecordHeader("retention-policy",
"90-days".getBytes(StandardCharsets.UTF_8)));
headers.add(new RecordHeader("compliance-tags",
"GDPR,CCPA".getBytes(StandardCharsets.UTF_8)));
producer.send(record, (metadata, exception) -> {
if (exception != null) {
exception.printStackTrace();
} else {
System.out.printf("Sent classified record to topic %s partition %d offset %d%n",
metadata.topic(), metadata.partition(), metadata.offset());
}
});
}
}
}In Python using the confluent-kafka library:
from confluent_kafka import Producer
def delivery_report(err, msg):
if err is not None:
print(f'Message delivery failed: {err}')
else:
print(f'Message delivered to {msg.topic()} [{msg.partition()}] at offset {msg.offset()}')
conf = {'bootstrap.servers': 'localhost:9092'}
producer = Producer(conf)
topic = 'confidential.customer.events'
key = 'customer-123'
value = '{"email":"user@example.com","phone":"+1234567890"}'
# Add classification headers
headers = [
('classification', b'CONFIDENTIAL'),
('pii-fields', b'email,phone'),
('retention-policy', b'90-days'),
('compliance-tags', b'GDPR,CCPA')
]
producer.produce(
topic=topic,
key=key,
value=value,
headers=headers,
callback=delivery_report
)
producer.flush()Reading and Enforcing Classification Headers
Downstream consumers should read classification headers and enforce appropriate handling policies. Here's how to read classification metadata:
import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.common.header.Header;
import java.nio.charset.StandardCharsets;
import java.time.Duration;
import java.util.Arrays;
import java.util.Properties;
public class ClassificationAwareConsumer {
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "classification-aware-consumer");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
try (KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props)) {
consumer.subscribe(Arrays.asList("confidential.customer.events"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
// Extract classification metadata
String classification = getHeaderValue(record, "classification");
String piiFields = getHeaderValue(record, "pii-fields");
String retentionPolicy = getHeaderValue(record, "retention-policy");
System.out.printf("Processing record with classification: %s%n", classification);
// Apply appropriate handling based on classification
if ("RESTRICTED".equals(classification) || "CONFIDENTIAL".equals(classification)) {
// Enforce encryption for sensitive data
// Log access for audit trail
System.out.println("Applying enhanced security controls for sensitive data");
auditAccess(record.key(), classification, piiFields);
// Mask PII fields if needed
String processedValue = maskPiiFields(record.value(), piiFields);
processMessage(processedValue);
} else {
// Standard processing for non-sensitive data
processMessage(record.value());
}
}
}
}
}
private static String getHeaderValue(ConsumerRecord<String, String> record, String headerKey) {
Header header = record.headers().lastHeader(headerKey);
return header != null ? new String(header.value(), StandardCharsets.UTF_8) : null;
}
private static void auditAccess(String key, String classification, String piiFields) {
// Log to audit system
System.out.printf("AUDIT: Accessed %s data [key=%s, pii-fields=%s]%n",
classification, key, piiFields);
}
private static String maskPiiFields(String value, String piiFields) {
// Implement field masking logic based on pii-fields
return value; // Simplified for example
}
private static void processMessage(String value) {
// Business logic here
}
}In Python:
from confluent_kafka import Consumer, KafkaException
import json
def get_header_value(headers, key):
"""Extract header value by key"""
if headers:
for header_key, header_value in headers:
if header_key == key:
return header_value.decode('utf-8') if header_value else None
return None
def audit_access(key, classification, pii_fields):
"""Log access to sensitive data"""
print(f"AUDIT: Accessed {classification} data [key={key}, pii-fields={pii_fields}]")
def mask_pii_fields(value, pii_fields):
"""Mask PII fields based on classification"""
# Implement masking logic
return value
def process_message(value):
"""Business logic for processing messages"""
pass
conf = {
'bootstrap.servers': 'localhost:9092',
'group.id': 'classification-aware-consumer',
'auto.offset.reset': 'earliest'
}
consumer = Consumer(conf)
consumer.subscribe(['confidential.customer.events'])
try:
while True:
msg = consumer.poll(timeout=1.0)
if msg is None:
continue
if msg.error():
raise KafkaException(msg.error())
# Extract classification metadata from headers
classification = get_header_value(msg.headers(), 'classification')
pii_fields = get_header_value(msg.headers(), 'pii-fields')
retention_policy = get_header_value(msg.headers(), 'retention-policy')
print(f"Processing record with classification: {classification}")
# Apply appropriate handling based on classification
if classification in ['RESTRICTED', 'CONFIDENTIAL']:
# Enforce enhanced security controls
audit_access(msg.key().decode('utf-8') if msg.key() else None,
classification, pii_fields)
# Mask PII if needed
processed_value = mask_pii_fields(msg.value().decode('utf-8'), pii_fields)
process_message(processed_value)
else:
# Standard processing
process_message(msg.value().decode('utf-8'))
except KeyboardInterrupt:
pass
finally:
consumer.close()Schema Registry Integration
Schema Registry is Confluent's centralized service for managing and validating schemas in Kafka environments. By embedding classification metadata directly in schemas, you ensure that every message using that schema inherits the classification automatically, preventing unclassified data from entering your system. For detailed Schema Registry implementation, see Schema Registry and Schema Management and Schema Evolution Best Practices.
Confluent Schema Registry supports custom properties that can include:
{
"name": "CustomerEvent",
"type": "record",
"metadata": {
"classification": "CONFIDENTIAL",
"contains_pii": true,
"pii_fields": ["email", "phone", "address"]
}
}Here's a complete example of registering an Avro schema with classification metadata:
import io.confluent.kafka.schemaregistry.client.CachedSchemaRegistryClient;
import io.confluent.kafka.schemaregistry.client.SchemaRegistryClient;
import org.apache.avro.Schema;
import org.apache.avro.SchemaBuilder;
import java.util.HashMap;
import java.util.Map;
public class SchemaRegistrationExample {
public static void main(String[] args) throws Exception {
String schemaRegistryUrl = "http://localhost:8081";
SchemaRegistryClient schemaRegistry = new CachedSchemaRegistryClient(schemaRegistryUrl, 100);
// Define Avro schema with classification
Schema customerSchema = SchemaBuilder
.record("CustomerEvent").namespace("com.example")
.fields()
.requiredString("customerId")
.requiredString("email")
.requiredString("phone")
.optionalString("address")
.endRecord();
// Add classification metadata as schema properties
Map<String, String> properties = new HashMap<>();
properties.put("classification", "CONFIDENTIAL");
properties.put("contains_pii", "true");
properties.put("pii_fields", "email,phone,address");
properties.put("retention_policy", "90-days");
properties.put("compliance_tags", "GDPR,CCPA");
// Register schema with metadata
String subject = "customer-events-value";
io.confluent.kafka.schemaregistry.avro.AvroSchema avroSchema =
new io.confluent.kafka.schemaregistry.avro.AvroSchema(customerSchema);
int schemaId = schemaRegistry.register(subject, avroSchema);
System.out.println("Registered schema with ID: " + schemaId);
// Optionally, update subject-level metadata
schemaRegistry.updateCompatibility(subject, "BACKWARD");
}
}Using the Schema Registry REST API to register a schema with metadata:
curl -X POST -H "Content-Type: application/vnd.schemaregistry.v1+json" \
--data '{
"schemaType": "AVRO",
"schema": "{\"type\":\"record\",\"name\":\"CustomerEvent\",\"namespace\":\"com.example\",\"fields\":[{\"name\":\"customerId\",\"type\":\"string\"},{\"name\":\"email\",\"type\":\"string\"},{\"name\":\"phone\",\"type\":\"string\"},{\"name\":\"address\",\"type\":[\"null\",\"string\"],\"default\":null}]}",
"metadata": {
"properties": {
"classification": "CONFIDENTIAL",
"contains_pii": "true",
"pii_fields": "email,phone,address",
"retention_policy": "90-days",
"compliance_tags": "GDPR,CCPA"
}
}
}' \
http://localhost:8081/subjects/customer-events-value/versionsTopic-Level Classification
Implementing a topic naming convention that includes classification information provides immediate visibility. For example:
public.web.clickstreamconfidential.customer.profile-updatesrestricted.payment.transactions
This strategy enables quick identification and allows security tools to apply policies based on topic patterns.
Comparison of Classification Approaches
Different classification strategies serve different use cases. Here's when to use each:
| Approach | Best For | Pros | Cons |
|---|---|---|---|
| Message Headers | Dynamic, event-level classification | Flexible, no schema changes needed, per-message granularity | Adds network overhead, requires consumer awareness |
| Schema Registry Metadata | Schema-level enforcement | Centralized governance, prevents unclassified data, integrates with tooling | Less flexible, requires Schema Registry, all messages share classification |
| Topic Naming | High-level organization | Immediate visibility, simple to implement, works with all tools | Coarse-grained, requires topic proliferation, hard to change |
| Combination | Enterprise environments | Comprehensive coverage, defense in depth | More complexity to manage |
Modern Governance Tools and Technologies (2025)
The data governance landscape has evolved significantly, with new tools and platforms specifically designed for streaming data classification and governance.
Conduktor Stream Governance
Conduktor provides comprehensive stream governance features that integrate classification directly into the data streaming workflow:
- Stream Catalog: Browse and manage your data streams with topic-level metadata
- Data Quality Rules: Define and enforce classification-based quality rules
- Business Metadata: Attach business context to technical classifications
# Example: Setting classification using Confluent CLI (Kafka 4.0+)
confluent schema-registry schema create \
--subject customer-events-value \
--schema-file customer.avsc \
--metadata '{"classification":"CONFIDENTIAL","pii_fields":["email","phone"]}'AI-Powered Classification and PII Detection
Machine learning-based tools now automate classification decisions by analyzing data patterns:
Automated PII Detection Tools (2025):
- AWS Macie for Kafka: Integrates with Amazon MSK to automatically detect PII in streaming data
- Azure Purview with Event Hubs: Provides ML-based classification for Azure event streams
- Google Cloud DLP API: Real-time scanning of Kafka messages for sensitive data patterns
- Open-source alternatives: Presidio (Microsoft), Pilar (AWS Labs)
Example using AWS Macie patterns in a Kafka consumer:
import boto3
from confluent_kafka import Consumer
# Initialize AWS Macie client for PII detection
macie_client = boto3.client('macie2', region_name='us-east-1')
def detect_pii_with_ml(message_content):
"""Use ML to detect PII in message content"""
# This is a conceptual example - actual implementation would use
# AWS Macie custom data identifiers or similar ML models
response = macie_client.test_custom_data_identifier(
regex='[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\\.[a-zA-Z]{2,}',
sampleText=message_content
)
return response['matchCount'] > 0
def auto_classify_message(message):
"""Automatically classify message based on content analysis"""
contains_pii = detect_pii_with_ml(message)
if contains_pii:
return {
'classification': 'CONFIDENTIAL',
'auto_detected': 'true',
'pii_detected': 'true',
'detection_method': 'ML'
}
return {'classification': 'INTERNAL'}Data Catalogs and Metadata Management
Modern data catalogs provide centralized classification management across streaming and batch systems:
Open-Source Solutions:
- OpenMetadata (2025): Native Kafka integration, automated lineage tracking, ML-based classification suggestions
- DataHub (LinkedIn): Kafka Connect integration, real-time metadata updates, classification propagation
- Amundsen (Lyft): Search-first catalog with Kafka stream discovery
Commercial Solutions:
- Atlan: Real-time classification sync with Kafka, automated compliance workflows
- Collibra: Enterprise-grade governance with Kafka stream cataloging
- Alation: Active metadata intelligence for streaming platforms
These tools sync classification metadata bidirectionally with Kafka, ensuring consistency between your streaming platform and enterprise governance systems.
Field-Level Encryption for Classified Data
For highly sensitive data, modern Kafka platforms support field-level encryption that integrates with classification tags:
import io.confluent.kafka.schemaregistry.encryption.FieldEncryptionExecutor;
import io.confluent.kafka.serializers.KafkaAvroSerializer;
// Configure field-level encryption based on classification
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("schema.registry.url", "http://localhost:8081");
// Enable field-level encryption for PII fields
props.put("rule.executors", "encrypt");
props.put("rule.executors.encrypt.class",
"io.confluent.kafka.schemaregistry.encryption.FieldEncryptionExecutor");
props.put("rule.executors.encrypt.param.kek.id", "my-kek");
props.put("rule.executors.encrypt.param.kms.type", "aws-kms");
props.put("rule.executors.encrypt.param.kms.key.id", "arn:aws:kms:...");
// Messages with classification=RESTRICTED will automatically encrypt PII fields
KafkaProducer<String, GenericRecord> producer = new KafkaProducer<>(props);This approach ensures that even if data is intercepted or improperly accessed, sensitive fields remain encrypted based on their classification level.
Data Contracts and Classification
Data contracts (an emerging pattern in 2025) formalize the agreement between data producers and consumers, including classification requirements:
# data-contract.yaml for customer-events topic
domain: customer
name: customer-events
version: 2.1.0
classification:
level: CONFIDENTIAL
sensitivity_fields:
- email: PII
- phone: PII
- customer_id: PII
retention: 90_days
compliance: [GDPR, CCPA]
schema:
type: avro
specification: customer-event-v2.avsc
quality:
- field: email
rule: valid_email_format
- field: phone
rule: valid_phone_format
owners:
- team: customer-data-platform
contact: customer-data@company.comTools like Confluent Schema Registry with Data Contracts or Soda Core can validate that producers honor these classification commitments. For detailed contract implementation, see Data Contracts for Reliable Pipelines.
Classification in Stream Processing Pipelines
When data flows through stream processing frameworks like Kafka Streams or Apache Flink, classification tags should propagate automatically. Modern frameworks (2025) support classification-aware processing:
Kafka Streams with Classification Propagation (Kafka 4.0+):
StreamsBuilder builder = new StreamsBuilder();
KStream<String, CustomerEvent> stream = builder.stream("customer-events");
// Classification metadata propagates through transformations
KStream<String, EnrichedCustomerEvent> enriched = stream
.mapValues((key, value) -> {
// Transform data
return enrichEvent(value);
})
// Headers (including classification) automatically propagate
.filter((key, value) -> value.isValid());
// Write to output topic with original classification preserved
enriched.to("enriched-customer-events");Apache Flink with Classification Handling (Flink 1.18+):
DataStream<CustomerEvent> stream = env
.addSource(new FlinkKafkaConsumer<>("customer-events", schema, props));
// Preserve classification metadata through transformations
stream
.map(new ClassificationAwareMapFunction())
.addSink(new FlinkKafkaProducer<>(
"processed-customer-events",
new ClassificationPreservingSerializer(),
props
));For more on stream processing patterns that preserve metadata, see Introduction to Kafka Streams and What is Apache Flink.
Practical Implementation Strategies
Start with Data Discovery
Before classifying data, you need to know what you have. Implement automated scanning tools that inspect message payloads and schemas to identify potential PII, financial data, or other sensitive information. Many organizations discover sensitive data flowing through systems they believed contained only operational metrics. For comprehensive data discovery approaches, see Building a Business Glossary for Data Governance.
Establish Clear Ownership
Every topic and data stream should have a designated data owner responsible for classification decisions. This accountability ensures classifications remain accurate as data evolves and prevents the "classify everything as confidential" problem that reduces the framework's effectiveness.
Automate Classification
Manual classification doesn't scale in streaming environments. Leverage schema validation, producer interceptors, and governance platforms to automatically tag data based on content patterns, source systems, and field names.
Implement Progressive Controls
Apply security controls proportional to classification levels. Public data might require only basic access logging, while restricted data demands encryption at rest and in transit, strict access controls, audit trails, and limited retention periods. For comprehensive security patterns, see Kafka Security Best Practices and Data Masking and Anonymization for Streaming.
Regular Classification Reviews
Data sensitivity changes over time. Customer emails might become public after opt-in to marketing lists. Financial projections become less sensitive after quarterly earnings releases. Schedule regular reviews to ensure classifications remain appropriate.
Integrating with Enterprise Security
Classification and tagging strategies must integrate with broader security infrastructure to provide defense-in-depth. Connect Kafka classification metadata to:
- Identity and Access Management (IAM): Use classification tags to drive Role-Based Access Control (RBAC) policies in Kafka ACLs (Access Control Lists) and authorization systems. For example, only users with "restricted-data-access" role can consume from topics tagged as RESTRICTED. See Data Access Control RBAC and ABAC for implementation patterns.
- Data Loss Prevention (DLP): Feed classification metadata to DLP systems for monitoring egress points and preventing unauthorized data exfiltration. DLP tools can automatically block or quarantine messages with CONFIDENTIAL or RESTRICTED classifications from being sent to unauthorized destinations.
- Security Information and Event Management (SIEM) platforms: Include classification context in security event logs for better threat detection and forensics. When a security incident occurs, knowing the classification level of accessed data helps prioritize response efforts. For audit logging implementation, see Audit Logging for Streaming Platforms.
- Data catalogs: Synchronize classification information with enterprise data catalogs for unified governance across streaming and batch systems. This ensures analysts and data scientists see consistent classification whether accessing Kafka streams or data warehouse tables. See What is a Data Catalog for more details.
- Encryption systems: Automatically apply encryption policies based on classification levels. RESTRICTED data might require field-level encryption, while CONFIDENTIAL data needs encryption in transit. See Encryption at Rest and in Transit for Kafka for comprehensive encryption strategies.
Conclusion
Data classification and tagging are the foundation of governance in streaming architectures. By implementing structured classification frameworks and using Kafka's native capabilities like message headers and Schema Registry, organizations can maintain security and compliance without sacrificing streaming performance.
The key is automation, clear ownership, and integration with existing security infrastructure. Start with critical data flows and expand systematically. With proper classification and tagging, your organization gains visibility, reduces risk, and builds trust in your data platform.
Related Concepts
- Schema Registry and Schema Management - Managing schemas with classification metadata
- Data Governance Framework: Roles and Responsibilities - Organizational structures for classification governance
- Audit Logging for Streaming Platforms - Tracking access to classified data
Sources and References
- Apache Kafka Documentation - Message Headers: Kafka Record Headers - Official documentation on implementing message headers in Apache Kafka for metadata propagation.
- Confluent Schema Registry Documentation: Schema Registry Overview - Comprehensive guide on using Schema Registry for schema management and metadata.
- NIST Special Publication 800-122: Guide to Protecting the Confidentiality of Personally Identifiable Information (PII) - Federal guidelines for PII classification and protection strategies.
- GDPR Article 32 - Security of Processing: EU General Data Protection Regulation - European Union requirements for implementing appropriate technical measures for data classification and security.
- OWASP Data Classification Guide: OWASP Application Security Verification Standard - Industry best practices for data classification in application security contexts.
Written by Stéphane Derosiaux · Last updated April 29, 2026