Data Pipeline Orchestration with Streaming
Modern data platforms increasingly rely on streaming architectures to deliver real-time insights and power event-driven applications. While traditional batch orchestration tools like Apache Airflow have matured over the past decade, streaming introduces fundamentally different orchestration challenges.
Understanding Pipeline Orchestration
Pipeline orchestration refers to the automated management of data workflows, including scheduling tasks, managing dependencies between operations, handling failures, and monitoring execution. In traditional batch processing, orchestration tools coordinate discrete jobs that run on a schedule, hourly ETL jobs, nightly data warehouse loads, or weekly report generation.
These batch orchestrators excel at directed acyclic graphs (DAGs) where task B waits for task A to complete. They provide retry logic, alerting, and visibility into pipeline execution. Tools like Apache Airflow, Prefect, and Dagster have become industry standards for this paradigm.
The Streaming Orchestration Challenge
Streaming data processing fundamentally differs from batch in one critical way: it's continuous rather than scheduled. A Kafka consumer reading from a topic doesn't "finish" in the traditional sense, it runs indefinitely, processing events as they arrive. This creates several orchestration challenges:
- Deployment vs Runtime Management: In batch systems, orchestration means scheduling when jobs run. In streaming, it often means deploying long-running applications and ensuring they stay healthy. A Flink job processing clickstream data might run for months without restarting.
- Stateful Processing: Streaming applications maintain state across millions of events. Orchestrating these systems means managing checkpoints, state backends, and ensuring exactly-once processing semantics survive failures and redeployments. For detailed coverage of state management in Flink, see Flink State Management and Checkpointing. For exactly-once semantics implementation, refer to Exactly-Once Semantics in Kafka.
- Dynamic Scaling: Streaming workloads vary throughout the day. Orchestration must handle scaling consumer groups, rebalancing partitions, and adjusting resources without data loss. To understand how consumer groups coordinate and rebalance, see Kafka Consumer Groups Explained.
Consider an e-commerce fraud detection pipeline: 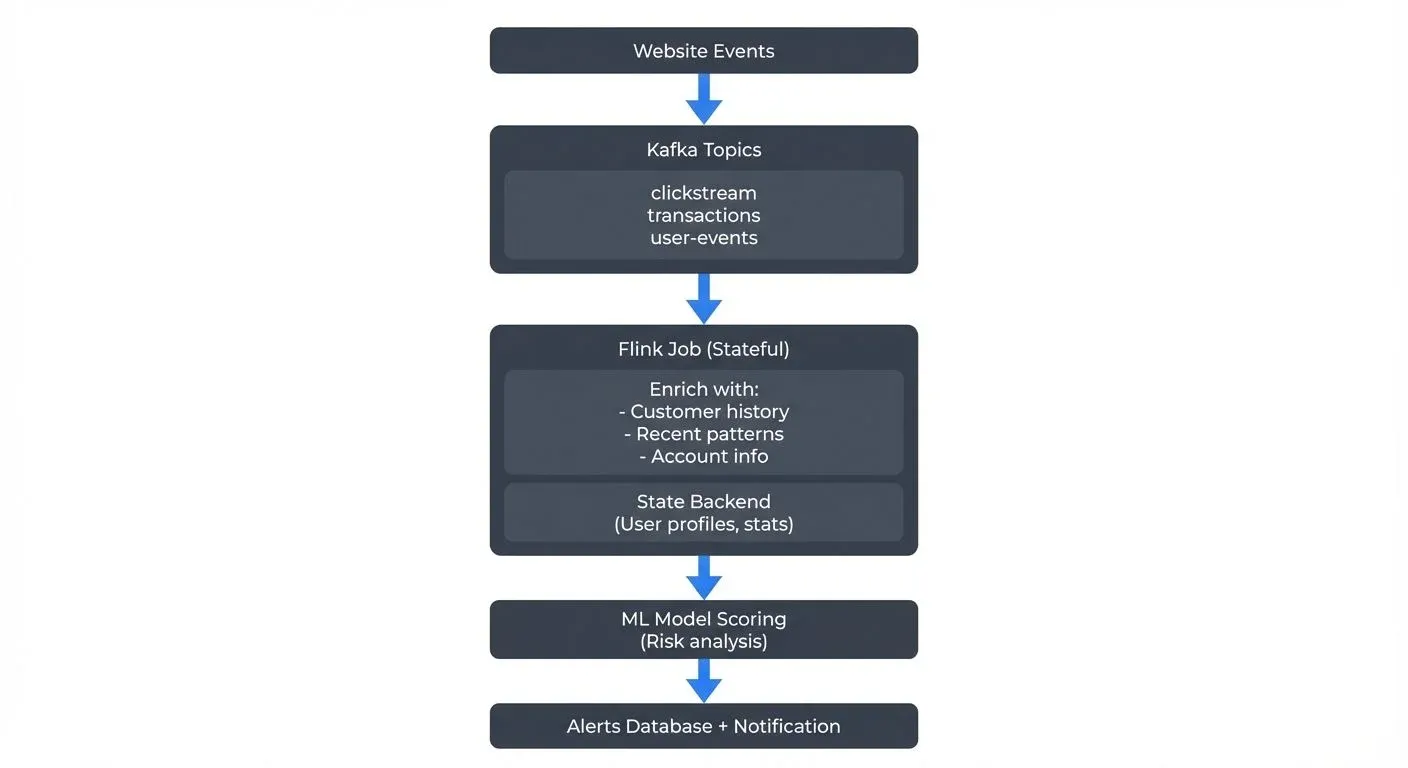
Traditional batch orchestration doesn't fit, this pipeline processes events continuously, scales dynamically based on traffic, and maintains complex state about user behavior patterns.
Orchestration Approaches for Streaming Pipelines
Organizations typically adopt one of three orchestration strategies for streaming systems, often using a combination:
Infrastructure Orchestration
Traditional orchestration tools manage the streaming infrastructure itself rather than the data flow. Airflow can deploy Kafka connectors, manage Flink job submissions, handle schema registry updates, and coordinate infrastructure changes. 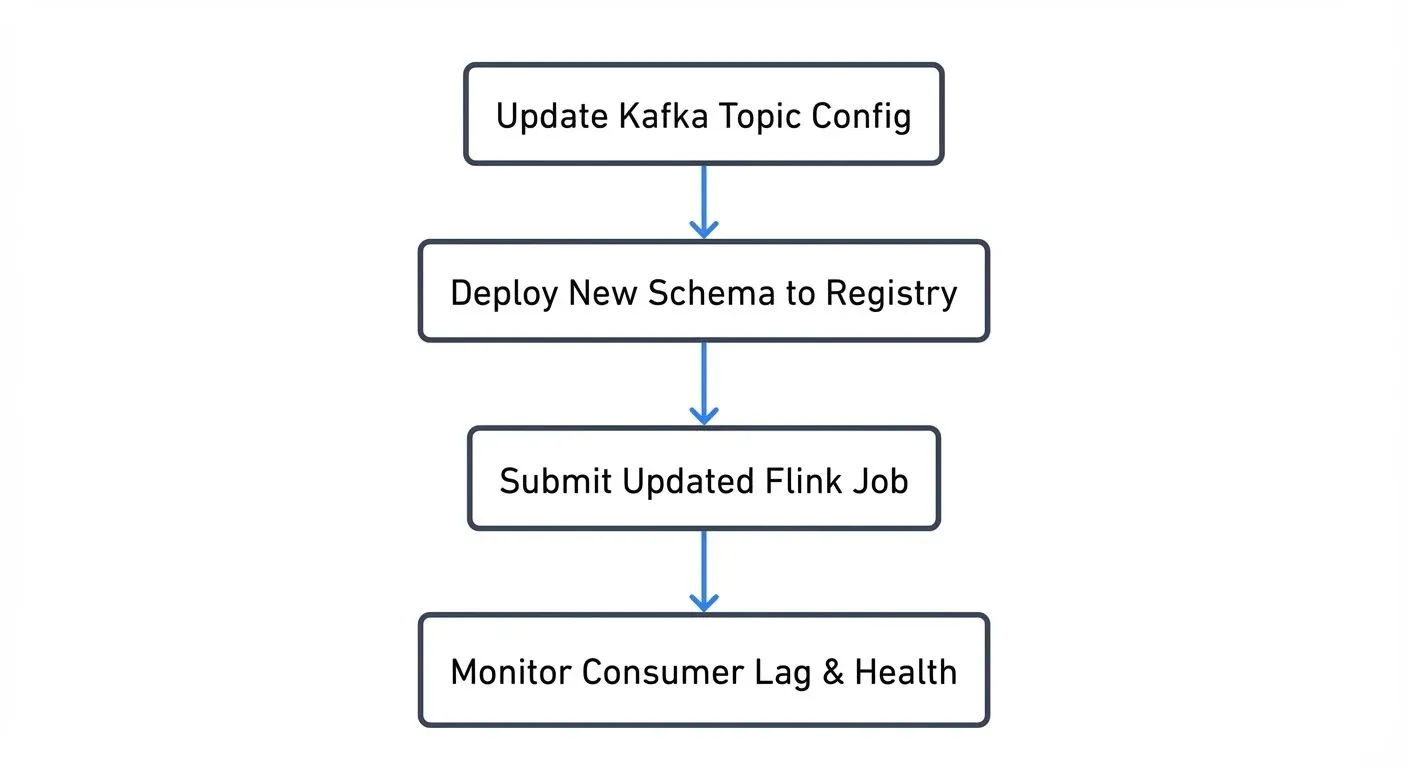
This approach treats streaming components as long-running infrastructure that needs periodic updates rather than repeatedly scheduled tasks.
Stream-Native Orchestration
Stream processing frameworks have built-in orchestration capabilities. Kafka Connect manages connector lifecycle, load balancing, and failure recovery. ksqlDB orchestrates stream processing through SQL statements. Flink's job manager handles checkpointing, savepoints, and recovery.
With Flink 1.18+ and its unified batch-streaming architecture, orchestration becomes more flexible. The same Flink job can process both bounded (batch) and unbounded (streaming) data, allowing orchestration systems to treat backfilling historical data and processing real-time streams as variations of the same pipeline rather than separate workflows.
These tools orchestrate at the stream processing level, managing how data flows through topics, how consumers coordinate, and how processing state is maintained. The "orchestration" is implicit in the streaming platform's design.
Kubernetes-Based Orchestration
Container orchestration platforms like Kubernetes increasingly manage streaming applications. Modern operators like Strimzi 0.40+ manage Kafka 4.0 clusters with KRaft mode (eliminating ZooKeeper dependencies), the Flink Kubernetes Operator 1.7+ handles Flink 1.18+ jobs with improved autoscaling, and standard Kubernetes primitives (deployments, services, config maps) orchestrate the entire streaming infrastructure.
This approach provides consistent orchestration across streaming and non-streaming components, unified monitoring, and declarative infrastructure management. With Kafka 4.0's KRaft mode, orchestration becomes simpler as there's no need to coordinate ZooKeeper clusters alongside Kafka, reducing operational complexity and improving deployment reliability. For detailed guidance on Kubernetes deployments, see Running Kafka on Kubernetes and Infrastructure as Code for Kafka Deployments.
Streaming and Data Pipeline Orchestration in Practice
Apache Kafka ecosystems demonstrate the interplay between different orchestration layers. A complete streaming pipeline involves:
- Topic Management: Creating topics with appropriate partitioning, replication, and retention policies. Changes must be coordinated across environments.
- Schema Evolution: As data structures evolve, schemas in the schema registry must be updated compatibly. Producers and consumers must handle multiple schema versions during transitions. For comprehensive guidance on managing schemas, see Schema Registry and Schema Management and Schema Evolution Best Practices.
- Connector Lifecycle: Kafka Connect source and sink connectors need deployment, configuration updates, and monitoring. A connector failure can create data gaps that require orchestrated recovery procedures. For detailed coverage of building and managing connectors, see Kafka Connect: Building Data Integration Pipelines.
- Consumer Group Coordination: Multiple applications consuming from the same topics need coordination. If a new consumer version deploys, orchestration ensures graceful handoff without duplicate processing or data loss.
- State Management: Applications using Kafka Streams or Flink maintain local state stores. Orchestration must handle state migration during scaling events or version upgrades.
Platforms like Conduktor help orchestrate these aspects by providing centralized management of topics, schemas, and connectors with Kafka Connect, and monitoring the health of consumer groups and connectors in real time.
Best Practices for Streaming Orchestration
Embrace Idempotency and Exactly-Once Semantics
Unlike batch jobs that can simply rerun, streaming pipelines must handle duplicate events and out-of-order processing. Design orchestration around Kafka's transactional producers, Flink's exactly-once processing, and idempotent consumers.
Schema-First Development
Enforce schema validation at ingestion. Use the schema registry as a source of truth. Orchestrate schema changes through a review process that includes compatibility checks and consumer impact analysis. Breaking schema changes can cascade through an entire streaming pipeline.
Monitor Lag, Not Just Errors
Traditional batch orchestration focuses on task success or failure. Streaming orchestration must monitor consumer lag, the gap between produced and consumed messages. Growing lag indicates problems even when no errors appear in logs.
Modern tools like Kafka Lag Exporter (Prometheus-based) provide real-time lag metrics that integrate with orchestration workflows. Platforms like Conduktor offer comprehensive monitoring dashboards that track consumer lag, throughput, and pipeline health across your entire streaming infrastructure. Monitor connector health and status with Kafka Connect Management and validate data quality using built-in monitoring tools. Orchestration systems should trigger alerts when lag exceeds thresholds and potentially scale resources automatically. For comprehensive monitoring strategies, see Kafka Cluster Monitoring and Metrics.
Design for Reprocessing
Build streaming pipelines that can rewind to earlier offsets and reprocess data. This enables fixing bugs in processing logic, recovering from data quality issues, and handling schema evolution problems. Orchestration should include tools for controlled reprocessing.
Dead Letter Queues for Poison Pills
Individual malformed events shouldn't crash entire streaming pipelines. Orchestrate error handling through dead letter topics that capture problematic events for later analysis and reprocessing. For detailed implementation guidance, see Dead Letter Queues for Error Handling.
Testing in Streaming Environments
Traditional orchestration includes testing through integration tests that run complete DAGs. Streaming requires testing continuous processing, state evolution, and failure scenarios. Tools that can replay production-like event streams into test environments help validate orchestration logic.
Chaos engineering for streaming pipelines has become essential in 2025. Conduktor Gateway enables testing failure scenarios by injecting faults, simulating network issues, and validating exactly-once guarantees under adverse conditions. Orchestration systems should include automated testing stages that verify pipeline resilience before production deployment.
Summary
Pipeline orchestration for streaming systems requires rethinking traditional batch patterns. While batch orchestration focuses on scheduling discrete jobs and managing task dependencies, streaming orchestration manages continuously running infrastructure, coordinates state across distributed systems, and ensures data flows reliably through complex topologies.
Successful streaming orchestration combines multiple approaches: traditional tools like Airflow for infrastructure deployment and updates, stream-native capabilities within Kafka and Flink for runtime coordination, and Kubernetes for container orchestration. Streaming pipelines are living systems that require ongoing management, not periodic execution.
Related Concepts
- Streaming Data Pipeline - Understanding the components that orchestration manages
- Streaming ETL vs Traditional ETL - How orchestration differs between batch and streaming
- Data Contracts for Reliable Pipelines - Enforcing contracts in orchestrated streaming pipelines
Sources and References
- Kleppmann, M. (2017). Designing Data-Intensive Applications: The Big Ideas Behind Reliable, Scalable, and Maintainable Systems. O'Reilly Media. Chapter 11: Stream Processing.
- Apache Kafka Documentation. (2025). "Kafka Connect" and "Kafka Streams Architecture." https://kafka.apache.org/documentation/
- Apache Flink Documentation. (2025). "Application Development" and "Operations & Deployment." https://flink.apache.org/
- Narkhede, N., Shapira, G., & Palino, T. (2017). Kafka: The Definitive Guide. O'Reilly Media.
- Conduktor Documentation. (2025). "Kafka Orchestration and Management." https://docs.conduktor.io/
Written by Stéphane Derosiaux · Last updated May 12, 2026