Kafka Exactly-Once: Producers + Transactions
Exactly-once semantics (EOS) in Kafka guarantees that every record is produced and consumed exactly once, even across broker failures and retries. Kafka implements EOS via idempotent producers (sequence-number dedup) and transactions (atomic multi-partition writes). It is the strongest delivery guarantee, at higher latency and coordination cost than at-least-once.
Understanding Delivery Guarantees: At-Most-Once, At-Least-Once, and Exactly-Once
Data processing guarantees define how a system handles records when failures occur. Distributed systems offer three fundamental delivery semantic models, each representing different trade-offs between reliability, performance, and implementation complexity.
At-Most-Once Delivery
The system processes a record at most once. If a failure occurs, the system will not retry, potentially leading to data loss. This occurs when producers don't wait for acknowledgment (acks=0) or consumers commit offsets before processing messages.
Use cases: High-throughput telemetry, metrics collection, or log aggregation where occasional data loss is acceptable and performance is critical. Offers highest throughput and lowest latency because no retry logic or coordination is needed.
At-Least-Once Delivery
The system guarantees a record will be processed, but failure recovery may cause the record to be processed more than once, leading to data duplication. This is the default setting for most message systems and the most common semantic in production.
- Use cases: Most data pipelines where duplicate processing can be handled through idempotent operations or deduplication logic. For example, updating a customer's current address is naturally idempotent — writing the same address twice produces the same result.
- Configuration: Producer with
acks=alland retries enabled; consumer commits offsets only after successful processing.
Exactly-Once Delivery (EOS)
The system ensures that every record is processed exactly one time, avoiding both data loss and data duplication. Messages are processed precisely once even in the presence of producer retries, broker failures, or consumer crashes.
- Use cases: Financial transactions, inventory updates, billing systems, or any operation where duplicates cause incorrect results. Processing a payment twice charges the customer incorrectly; missing a payment fails to record revenue.
- Trade-offs: Slightly higher latency (typically 2-5ms) and lower throughput (10-20% reduction) compared to at-least-once, plus increased configuration and operational complexity.
What is Exactly-Once Semantics?
Exactly-once semantics means that the effect of processing a message happens exactly once, even if the system encounters failures, retries, or network issues. In Kafka, this involves two key guarantees:
- Idempotent production: A producer can safely retry sending messages without creating duplicates
- Transactional processing: Messages are produced, consumed, and processed as atomic operations
Kafka introduced exactly-once semantics in version 0.11.0 and has continued to refine the implementation in subsequent releases. Kafka 2.5 introduced the improved exactly_once_v2 protocol for Kafka Streams, and Kafka 4.0+ brings significant performance improvements to transactional processing in KRaft mode, with faster transaction commits and reduced coordinator overhead.
The Challenge of Exactly-Once: Why It's Considered Hard
Achieving EOS is complex because failures in distributed systems are asynchronous and unpredictable.
Producer Retries and Duplicate Writes
When a producer sends a message to the broker and doesn't receive an acknowledgment due to a network timeout, it faces ambiguity: did the broker receive the message but fail before acknowledging? Or did the message never arrive? Without additional mechanisms, retrying risks writing the same message twice (violating exactly-once); not retrying risks data loss (violating at-least-once).
Consumer Recovery and Duplicate Processing
When a consumer fails after reading a record but before committing its offset, it must restart and will re-read and re-process the last record. The challenge intensifies with stateful operations (aggregations, joins, windows) because the consumer must coordinate reading from source, updating internal state, writing results to sink, and committing source offsets, all atomically.
Coordinating Distributed State
Exactly-once semantics requires atomic operations across multiple components: producers writing to topics, consumers processing messages, stream processors updating state, and external systems persisting results, all as a single logical transaction. This coordination problem compounds when operations span multiple partitions, topics, or separate systems.
How Kafka Achieves Exactly-Once Semantics
Kafka's exactly-once implementation relies on three core mechanisms: idempotent producers, transactions, and transactional consumers. 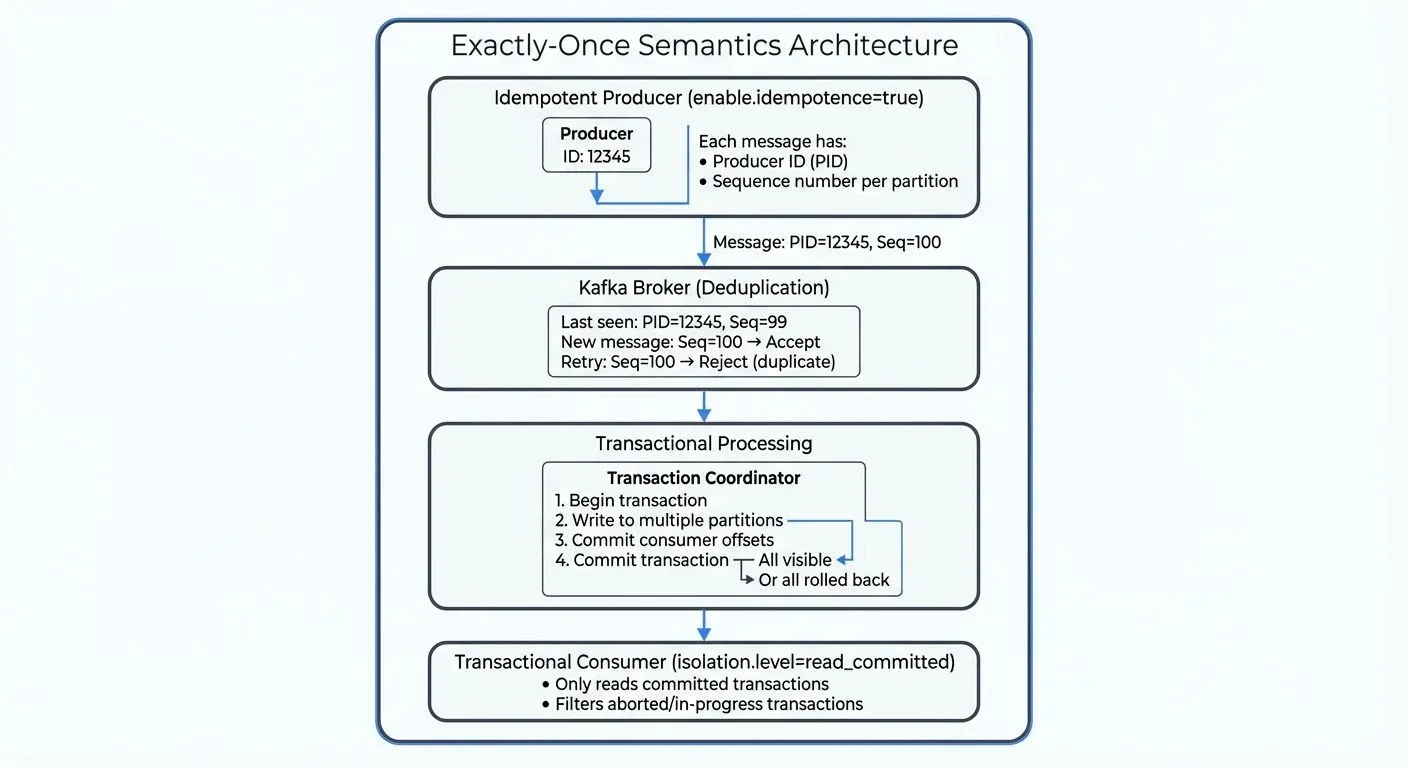
Idempotent Producers: Preventing Duplicate Writes
The idempotent producer guarantees that retrying the same send request will only ever write the record once to the Kafka log. Kafka assigns each producer a unique Producer ID (PID) during initialization and tracks a sequence number for each message sent to each partition. This sequence number increments with each message. When a producer retries, Kafka detects duplicate messages by comparing sequence numbers and simply acknowledges success without writing the message again.
Configuration (Kafka 3.0+ defaults):
enable.idempotence=true # Default in Kafka 3.0+
acks=all
retries=Integer.MAX_VALUE
max.in.flight.requests.per.connection=5Idempotence is enabled by default in Kafka 3.0+, making exactly-once semantics more accessible. Prior versions required explicit configuration. For comprehensive coverage of producer configuration and behavior, see Kafka Producers.
Transactional Producers: Atomic Multi-Partition Writes
Transactional producers extend idempotence to allow atomic writes across multiple partitions and topics. A Transaction Coordinator in the broker manages a two-phase commit process (a distributed algorithm that ensures all participants agree to commit or abort), guaranteeing either all messages in the batch are committed or none are.
To use transactions, assign a transactional.id to your producer. This ID is persistent across producer restarts, allowing Kafka to fence out zombie producers (old instances that haven't fully shut down) and prevent split-brain scenarios.
Configuration:
enable.idempotence=true
transactional.id=unique-transactional-id-per-producer-instanceProducer code pattern:
producer.initTransactions();
try {
producer.beginTransaction();
producer.send(new ProducerRecord<>("output-topic", key, value));
producer.sendOffsetsToTransaction(offsets, consumerGroupId);
producer.commitTransaction();
} catch (Exception e) {
producer.abortTransaction();
}This enables the read-process-write cycle to be atomic: read from input topic, process, write to output topic, and commit input offsets all succeed together or all fail together. For the full mechanics of Kafka's transactional implementation, see Kafka Transactions Deep Dive.
Transactional Consumers: Reading Only Committed Data
Consumers must configure isolation.level=read_committed to participate in exactly-once semantics. With this setting, they only see messages from committed transactions; in-flight and aborted writes are filtered out.
Configuration:
isolation.level=read_committed
enable.auto.commit=falseWhen processing messages transactionally, the consumer reads messages, processes them, produces results to output topics, and commits its offsets within a single transaction. If the transaction fails, none of the effects are visible. For more information on consumer offset management and group coordination, see Kafka Consumer Groups Explained.
Tools like Conduktor provide visual monitoring of transaction markers in Kafka topics through topic management and real-time tracking of transactional producer states, making it easier to debug exactly-once configurations, verify transaction completion, and troubleshoot issues like stalled transactions or coordinator problems.
KRaft and Transaction Performance (Kafka 4.0+)
With Kafka 4.0 (released 2024), KRaft (Kafka Raft) replaced ZooKeeper as the metadata management system and became the default deployment mode. This architectural shift significantly improves exactly-once semantics performance and reliability:
Transaction Coordinator Improvements:
- Faster Failover: Transaction coordinator recovery time reduced from seconds to milliseconds, minimizing transaction timeout risk during broker failures
- Reduced Metadata Overhead: Transaction state replication is more efficient without ZooKeeper coordination, reducing broker CPU and network usage
- Improved Commit Latency: Transaction commits are 5-10% faster thanks to simpler metadata operations through the Raft protocol
Operational Benefits:
- Simplified Architecture: Eliminates ZooKeeper dependencies, reducing operational complexity for exactly-once deployments
- Better Scalability: Supports more concurrent transactions per broker without metadata bottlenecks
- Enhanced Monitoring: Transaction coordinator metrics are now integrated directly into Kafka's native monitoring
KRaft is the default and recommended mode for Kafka 4.0+. ZooKeeper mode is deprecated and will be removed in future versions. For exactly-once workloads, migrating to KRaft provides measurable performance improvements and operational simplification.
Exactly-Once in Stream Processing
Stream processing frameworks like Kafka Streams and Apache Flink build on Kafka's exactly-once semantics to provide end-to-end processing guarantees. While Kafka provides the transactional messaging layer, stream processing engines manage state correctly during failures through checkpointing.
Kafka Streams
Kafka Streams provides exactly-once semantics out of the box when you set processing.guarantee=exactly_once_v2 (introduced in Kafka 2.5 and the recommended setting for Kafka 2.5+). It coordinates consumer offsets, operator state snapshots, and output commits within a single Kafka transaction. When a failure occurs, Kafka Streams rolls back to the last successful transaction and resumes processing without loss or duplication. Kafka 4.0+ further improves Kafka Streams EOS performance with optimized transaction handling in KRaft mode. For a comprehensive introduction to Kafka Streams architecture, see Introduction to Kafka Streams.
Apache Flink
Flink achieves exactly-once semantics through distributed checkpointing coordinated with Kafka transactions using two-phase commit: first, all operators prepare the transaction by persisting state; second, all commit together. Flink periodically snapshots operator state, writes output records to Kafka without committing, then commits all transactions together only after all operators successfully complete their checkpoint. If a failure occurs before a checkpoint, Flink rolls back to the last successful checkpoint and Kafka aborts the incomplete transaction.
Flink 1.19+ Improvements (2024):
- Enhanced Checkpoint Coordinator: Reduces checkpoint completion time by 10-15%, accelerating recovery from failures
- Better Timeout Handling: Improved detection and recovery from checkpoint timeouts during transaction coordination
- Reduced State Overhead: Optimized checkpoint metadata storage reduces the cost of maintaining exactly-once guarantees
These improvements make Flink's exactly-once mode more performant and reliable for production workloads processing millions of events per second. For detailed coverage of Flink's checkpointing and state management, see Flink State Management and Checkpointing. To compare the two approaches, see Kafka Streams vs Apache Flink.
Achieving End-to-End EOS: Source, Processor, and Sink
True end-to-end exactly-once semantics requires coordination across all three pipeline stages.
- Source Requirements: The source must be re-readable, allowing consumers to reset positions and replay data after failures. Kafka's durable log architecture excels here.
- Processor Requirements: The processor must be transactional, coordinating state updates with input consumption and output production. Flink and Kafka Streams provide this via distributed checkpointing and two-phase commits.
- Sink Requirements: The sink must be either idempotent (safely handling duplicate writes like Cassandra or key-value stores) or transactional (participating in two-phase commit like PostgreSQL or MySQL). Non-compliant sinks require application-level deduplication.
Trade-offs and Performance Considerations
Exactly-once semantics comes with measurable costs. The additional coordination and bookkeeping required to guarantee exactly-once delivery impacts throughput and latency.
- Latency: Transactional producers add 2-5 milliseconds due to transaction coordination (waiting for the transaction coordinator to acknowledge commits).
- Throughput: The two-phase commit protocol and additional metadata management reduce maximum throughput by 10-20% compared to at-least-once semantics.
- Broker Load: Transaction coordinators and additional state tracking consume more broker resources. Each transactional producer maintains state, and transaction logs require disk space.
- Operational Complexity: Requires monitoring transaction status and handling zombie transactions.
When Exactly-Once Is Worth It
Choose exactly-once semantics when:
- Duplicates cause incorrect results (financial transactions, inventory updates, billing)
- Applications maintain monetary values or non-idempotent state
- Compliance requires guaranteed processing (audit trails, regulatory reporting)
- The cost of incorrect data exceeds the performance overhead
Consider at-least-once when:
- Downstream operations are naturally idempotent
- Performance requirements are extreme (sub-millisecond latency)
- The application can deduplicate through business logic
Platforms like Conduktor help you understand the performance impact of exactly-once semantics by providing comprehensive visibility into producer and consumer metrics through topic monitoring, transaction success rates, coordinator performance, and end-to-end latency.
Conduktor Console: Inspect stream processing topology and debug stateful operators. Explore Conduktor Console →
Monitoring and Validating Exactly-Once Behavior
Operating exactly-once pipelines requires specific monitoring.
Key Metrics:
- Transaction Coordinator Lag: Indicates broker overload or configuration issues
- Aborted Transactions: Spikes suggest application errors or infrastructure issues
- Producer Transaction Timeouts: Detects slow processing or oversized transactions
- Fence Occurrences: When a new producer instance with the same
transactional.idstarts, Kafka fences out (blocks) the old instance to prevent zombie producers from corrupting data. Frequent fencing suggests transaction timeouts being too short, producers restarting too often, or duplicate transactional IDs. - Zombie Transaction Detection: Transactions remaining open can block downstream consumers
Validation Techniques:
- End-to-end counting with unique identifiers
- Application-level duplicate detection for validation
- Transaction state inspection using Kafka tools
- State consistency checks comparing checkpoint state with topic offsets
For comprehensive approaches to validating exactly-once behavior in production, see Testing Strategies for Streaming Applications.
Governance and Compliance
In enterprise environments, governance is essential to ensure EOS is correctly configured. Platforms like Conduktor provide real-time visibility into transaction status across all Kafka clusters through topic management, enabling operators to identify and abort zombie transactions, enforce policies requiring EOS for sensitive data streams, track which applications have exactly-once enabled, and monitor transaction health metrics in centralized dashboards.
Testing Exactly-Once with Conduktor Gateway:
Validating exactly-once behavior under failure conditions requires chaos testing. Conduktor Gateway acts as a proxy layer between producers/consumers and Kafka brokers, enabling controlled failure injection:
- Transaction Coordinator Failures: Simulate coordinator crashes during transaction commits to verify proper recovery
- Network Partitions: Introduce network delays or disconnections to test timeout handling and retry logic
- Broker Failures: Trigger broker unavailability during two-phase commits to validate transaction rollback
- Consumer Rebalancing: Force consumer group rebalances mid-transaction to test fence handling
This testing validates that applications correctly maintain exactly-once guarantees even when infrastructure fails, providing confidence before production deployment.
Real-World Use Cases
- Financial Services: A payments platform uses exactly-once semantics to ensure that each payment instruction is processed exactly once. When a customer initiates a wire transfer, the system publishes a transaction event to Kafka. Downstream services consume this event to debit the sender's account, credit the receiver's account, and record the transaction for compliance. Without exactly-once guarantees, a retry could cause a double charge or duplicate accounting entry.
- E-commerce Order Processing: An online retailer processes orders through Kafka. When a customer places an order, an order service publishes the event transactionally along with inventory updates. The inventory service consumes these events with exactly-once semantics to ensure that each order decrements inventory counts exactly once. This prevents overselling products due to duplicate inventory decrements or underselling due to lost messages. For more e-commerce streaming patterns, see E-commerce Streaming Architecture Patterns.
Summary
Exactly-once semantics is the highest data integrity guarantee in data streaming, essential for maintaining correct state in financial, billing, inventory, and compliance-driven applications.
- Why it matters: EOS eliminates both data loss and duplication by ensuring every record is processed exactly once. For financial transactions and regulatory compliance, that guarantee prevents incorrect results from duplicate processing or missing data.
- How it works: Kafka achieves EOS through idempotent producers (sequence-number deduplication), transactional producers (atomic multi-partition writes via two-phase commit), and transactional consumers (read_committed isolation). Stream processors like Kafka Streams and Apache Flink build on these primitives via checkpointing.
- What it costs: 2-5ms additional latency, 10-20% throughput reduction. Acceptable for critical workflows; use at-least-once elsewhere.
- Where platforms fit: Governance and observability platforms help manage exactly-once configurations at scale: tracking settings, monitoring transaction states, enforcing policies, and meeting regulatory requirements for data integrity.
Related Concepts
- Kafka Transactions Deep Dive - Full mechanics of Kafka's transactional implementation
- Saga Pattern for Distributed Transactions - Managing distributed transactions with exactly-once guarantees
- Kafka Streams vs Apache Flink - Comparing the two stream processing approaches to exactly-once
- Flink State Management and Checkpointing - How Flink's checkpointing integrates with Kafka transactions
- Testing Strategies for Streaming Applications - Validating exactly-once behavior in production
- Kafka UI: The Complete Guide - Inspect producer/consumer state, decode payloads, and debug transactional workflows from a UI
Sources and References
- Apache Kafka Documentation: Exactly Once Semantics - Official documentation on Kafka's delivery semantics and transactional API
- Confluent Blog: Exactly-Once Semantics Are Possible: Here's How Kafka Does It - In-depth technical explanation of Kafka's exactly-once implementation
- KIP-98: Exactly Once Delivery and Transactional Messaging - Original Kafka Improvement Proposal introducing exactly-once semantics
- Apache Flink Documentation: Fault Tolerance Guarantees of Data Sources and Sinks - How Flink integrates with Kafka for exactly-once processing
- Jay Kreps: Transactions in Apache Kafka - Architectural rationale for Kafka's transactional model
- Apache Kafka: KIP-500: Replace ZooKeeper with a Self-Managed Metadata Quorum - KRaft architecture enabling improved transaction performance