PII Leakage Prevention: Protecting Personal Data in Streaming
The consequences extend beyond technical issues. Unintended PII exposure violates data protection regulations like GDPR, CCPA, and HIPAA, leading to substantial fines, legal liability, and reputational damage. Organizations must implement comprehensive detection and prevention strategies to protect personal data throughout the streaming pipeline.
The Hidden Risk of PII Leakage
Personally Identifiable Information (PII) leakage represents one of the most serious security risks in modern data streaming architectures. Unlike intentional data breaches, PII leakage occurs through unintended exposure, when sensitive personal data appears in logs, error messages, monitoring systems, or misconfigured data streams where it shouldn't exist. In streaming systems that process millions of events per second, a single misconfiguration can expose vast amounts of personal data before anyone notices. 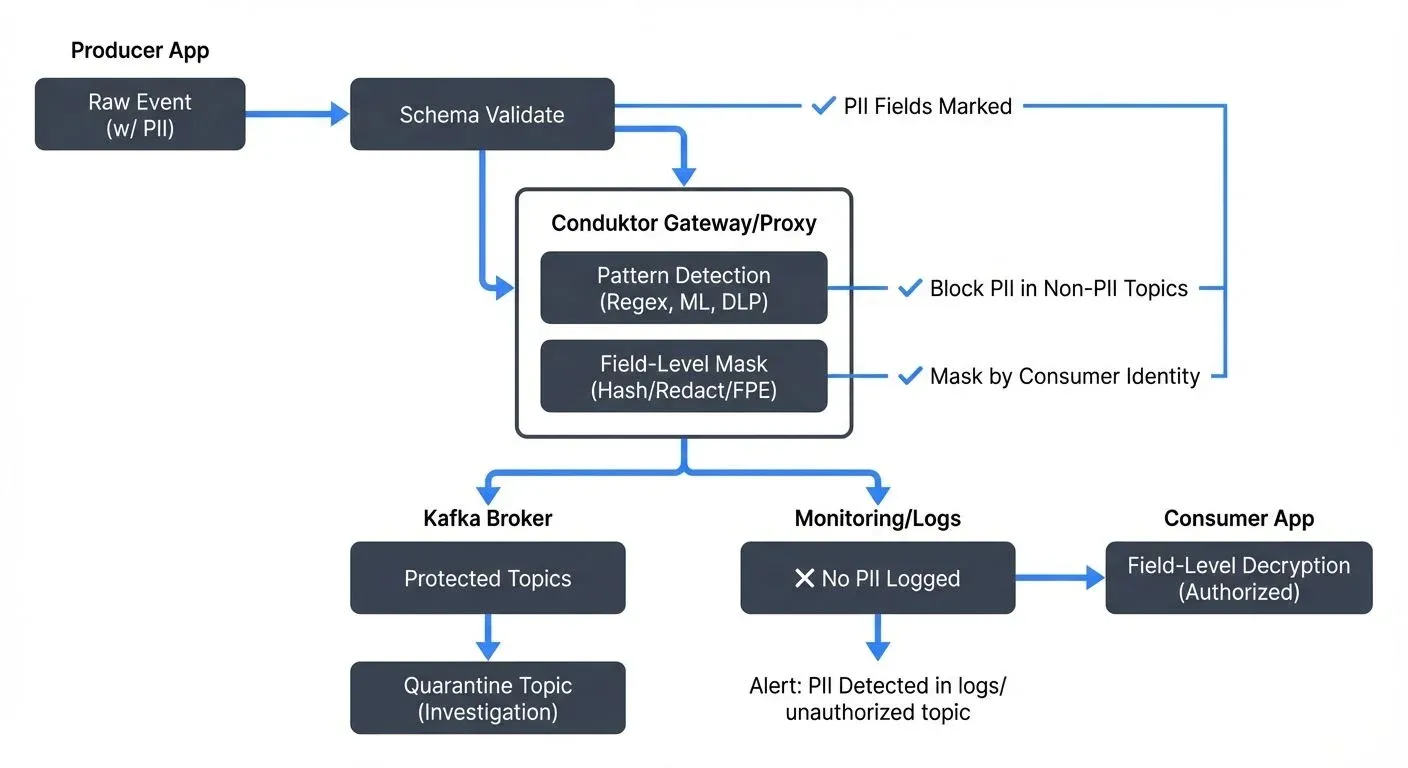
Understanding PII Leakage Vectors in Streaming
PII leakage in streaming systems occurs through multiple vectors, each requiring specific attention:
- Application Logs and Error Messages: Developers often log full event payloads during debugging, inadvertently capturing credit card numbers, email addresses, or social security numbers. Exception stack traces may include sensitive data from failed transactions or validation errors.
- Monitoring and Observability Systems: Metrics collection, distributed tracing, and monitoring dashboards can expose PII when event samples are captured for analysis. A single trace showing a complete message payload might reveal customer information to anyone with dashboard access.
- Misconfigured Topics and Streams: Data may flow to the wrong Kafka topics, event hubs, or S3 buckets due to routing errors, incorrect access controls, or development configurations accidentally deployed to production. Topics intended for internal analytics might receive raw customer data instead of anonymized aggregates.
- Debug Output and Development Tools: Schema registry snapshots, consumer group testing tools, and data quality dashboards often display sample records. Without proper masking, these tools become PII exposure points accessible to broad engineering teams.
- Third-Party Integrations: Data sent to external analytics platforms, monitoring services, or partner systems may contain more PII than necessary for the intended use case. API calls that include full event contexts rather than minimal required fields create unnecessary exposure.
Detection Approaches and Technologies
Effective PII detection requires multiple complementary approaches:
Pattern Matching and Regular Expressions: The foundational detection method uses regex patterns to identify common PII formats, credit card numbers following Luhn validation (a checksum algorithm that validates card number authenticity), email addresses matching RFC specifications, phone numbers in various international formats, and social security numbers with characteristic digit patterns. While fast and deterministic, pattern matching produces false positives (matches that aren't actually PII) and misses contextual PII like names or addresses without distinctive formats.
Here's a practical example of pattern-based PII detection in Kafka Streams:
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.kstream.KStream;
import java.util.regex.Pattern;
import java.util.regex.Matcher;
public class PIIDetectionStreams {
// Common PII detection patterns
private static final Pattern EMAIL_PATTERN = Pattern.compile(
"[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\\.[a-zA-Z]{2,}");
private static final Pattern SSN_PATTERN = Pattern.compile(
"\\b\\d{3}-\\d{2}-\\d{4}\\b");
private static final Pattern CREDIT_CARD_PATTERN = Pattern.compile(
"\\b\\d{4}[\\s-]?\\d{4}[\\s-]?\\d{4}[\\s-]?\\d{4}\\b");
public static void buildPipeline(StreamsBuilder builder) {
KStream<String, String> events = builder.stream("raw-events");
// Detect and route messages containing PII
events.filter((key, value) -> containsPII(value))
.to("pii-detected-events");
// Route clean messages to standard processing
events.filterNot((key, value) -> containsPII(value))
.to("clean-events");
}
private static boolean containsPII(String message) {
return EMAIL_PATTERN.matcher(message).find() ||
SSN_PATTERN.matcher(message).find() ||
CREDIT_CARD_PATTERN.matcher(message).find();
}
private static boolean isValidLuhn(String cardNumber) {
// Luhn algorithm implementation for credit card validation
int sum = 0;
boolean alternate = false;
for (int i = cardNumber.length() - 1; i >= 0; i--) {
int n = Integer.parseInt(cardNumber.substring(i, i + 1));
if (alternate) {
n *= 2;
if (n > 9) n -= 9;
}
sum += n;
alternate = !alternate;
}
return (sum % 10 == 0);
}
}- Machine Learning Classification: ML models trained on labeled datasets can identify contextual PII that pattern matching misses. Named entity recognition (NER, Natural Language Processing models that identify and classify named entities like person names, locations, and organizations) models detect person names, locations, and organizations within unstructured text. Classification models learn to identify sensitive fields based on data characteristics, field names, and surrounding context. These approaches reduce false positives but require training data and model maintenance.
- Modern AI-Powered PII Detection (2025): Cloud providers and open-source projects now offer sophisticated ML-based PII detection that integrates directly with streaming platforms:
- AWS Macie for Kafka: Integrates with Amazon MSK to automatically detect PII in streaming data using machine learning models trained on vast datasets of sensitive information patterns
- Google Cloud DLP API: Provides real-time PII scanning with 150+ built-in detectors for global PII types, callable from stream processors
- Azure Purview with Event Hubs: Offers ML-based classification for Azure event streams with automatic sensitivity labeling
- Microsoft Presidio: Open-source PII detection and anonymization framework supporting 20+ languages, deployable as a sidecar service
- AWS Pilar (Pilar Labs): Open-source privacy-preserving analytics framework with built-in PII detection
Here's an example integrating Google Cloud DLP API with Flink for real-time PII detection:
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.datastream.functions import MapFunction
from google.cloud import dlp_v2
import json
class DLPPIIDetector(MapFunction):
def __init__(self, project_id):
self.project_id = project_id
self.dlp_client = None
def open(self, runtime_context):
# Initialize DLP client once per task
self.dlp_client = dlp_v2.DlpServiceClient()
self.parent = f"projects/{self.project_id}"
def map(self, event_json):
event = json.loads(event_json)
# Inspect content for PII
item = {"value": str(event)}
response = self.dlp_client.inspect_content(
request={
"parent": self.parent,
"inspect_config": {
"info_types": [
{"name": "EMAIL_ADDRESS"},
{"name": "PHONE_NUMBER"},
{"name": "CREDIT_CARD_NUMBER"},
{"name": "US_SOCIAL_SECURITY_NUMBER"}
],
"min_likelihood": dlp_v2.Likelihood.POSSIBLE
},
"item": item
}
)
# Tag event with detected PII types
if response.result.findings:
pii_types = [f.info_type.name for f in response.result.findings]
event['_pii_detected'] = True
event['_pii_types'] = pii_types
event['_classification'] = 'CONFIDENTIAL'
else:
event['_pii_detected'] = False
event['_classification'] = 'INTERNAL'
return json.dumps(event)
# Usage in Flink pipeline
env = StreamExecutionEnvironment.get_execution_environment()
stream = env.from_source(kafka_source, watermark_strategy, "raw-events")
classified_stream = stream.map(DLPPIIDetector(project_id="my-project"))
classified_stream.sink_to(kafka_sink)- Data Scanning and Profiling: Systematic scanning analyzes data distribution, uniqueness, and statistical properties to flag potentially sensitive fields. High-cardinality string fields with person-name-like characteristics, fields containing consistent geographic patterns, or columns showing birthdate distributions warrant investigation. Profiling complements pattern matching by identifying sensitive data not matching known formats.
- Schema-Level Metadata: The most reliable detection approach marks sensitive fields directly in schemas. Avro, Protobuf, and JSON schemas can include annotations or tags identifying fields containing PII. This metadata-driven approach enables consistent handling across the pipeline without per-message inspection overhead. For comprehensive schema management patterns, see Schema Registry and Schema Management.
Comparing Detection Approaches
| Approach | Speed | Accuracy | Maintenance | Best For |
|---|---|---|---|---|
| Pattern Matching | Very Fast | Medium (false positives) | Low | Structured PII (SSN, credit cards, emails) |
| ML Classification | Medium | High | High (model training) | Contextual PII (names, addresses) |
| Cloud AI Services | Medium | Very High | Low (managed service) | Enterprise deployments, multi-language PII |
| Schema Metadata | Very Fast | Perfect (if accurate) | Medium (schema governance) | Structured streaming with schema registry |
| Data Profiling | Slow | Medium | Medium | Data discovery, unknown PII identification |
Prevention Strategies and Best Practices
Prevention strategies operate at multiple levels:
Data Masking and Tokenization: Replace PII with masked values or tokens before data enters logs, metrics, or lower-security environments. Format-preserving encryption (FPE) maintains data characteristics for testing while protecting actual values, for example, encrypting a 16-digit credit card number into another valid-looking 16-digit number that preserves the format but protects the actual value. Tokenization replaces sensitive fields with random identifiers, storing the mapping in a secure token vault accessible only to authorized systems. For comprehensive masking techniques and implementation patterns, see Data Masking and Anonymization for Streaming.
Here's a practical tokenization example using Kafka Streams with a token vault:
import org.apache.kafka.streams.kstream.KStream;
import org.apache.kafka.streams.kstream.ValueMapper;
import java.util.Map;
import java.util.UUID;
import java.util.concurrent.ConcurrentHashMap;
public class TokenizationProcessor {
// Token vault (in production, use Redis or a dedicated token service)
private static final Map<String, String> tokenVault = new ConcurrentHashMap<>();
private static final Map<String, String> reverseVault = new ConcurrentHashMap<>();
public static void buildTokenizationPipeline(StreamsBuilder builder) {
KStream<String, CustomerEvent> events = builder.stream("raw-customer-events");
// Tokenize PII fields
KStream<String, CustomerEvent> tokenized = events.mapValues(event -> {
CustomerEvent tokenizedEvent = event.copy();
// Tokenize email
if (event.email != null) {
tokenizedEvent.email = tokenize(event.email, "email");
}
// Tokenize SSN
if (event.ssn != null) {
tokenizedEvent.ssn = tokenize(event.ssn, "ssn");
}
return tokenizedEvent;
});
tokenized.to("tokenized-customer-events");
}
private static String tokenize(String value, String fieldType) {
// Check if we've already tokenized this value
if (reverseVault.containsKey(value)) {
return reverseVault.get(value);
}
// Generate new token
String token = fieldType + "_" + UUID.randomUUID().toString().replace("-", "");
// Store in vaults
tokenVault.put(token, value);
reverseVault.put(value, token);
return token;
}
// Detokenization for authorized services
public static String detokenize(String token) {
return tokenVault.get(token);
}
}Field-Level Encryption for Highly Sensitive Data: For data classified as highly sensitive, implement field-level encryption that encrypts specific fields while leaving others in plaintext. This allows analytics on non-sensitive fields while protecting PII:
from cryptography.fernet import Fernet
from confluent_kafka import Producer
import json
class FieldLevelEncryptionProducer:
def __init__(self, bootstrap_servers, encryption_key):
self.producer = Producer({'bootstrap.servers': bootstrap_servers})
self.cipher = Fernet(encryption_key)
def encrypt_field(self, value):
"""Encrypt a single field value"""
return self.cipher.encrypt(value.encode()).decode()
def send_customer_event(self, customer_data):
"""Send customer event with PII fields encrypted"""
# Encrypt PII fields
encrypted_event = {
'customer_id': customer_data['customer_id'], # Not encrypted
'email': self.encrypt_field(customer_data['email']), # Encrypted
'ssn': self.encrypt_field(customer_data['ssn']), # Encrypted
'purchase_amount': customer_data['purchase_amount'], # Not encrypted
'timestamp': customer_data['timestamp'] # Not encrypted
}
self.producer.produce(
'customer-events',
key=customer_data['customer_id'],
value=json.dumps(encrypted_event)
)
self.producer.flush()
# Usage
key = Fernet.generate_key() # In production, use KMS (AWS KMS, Azure Key Vault, etc.)
producer = FieldLevelEncryptionProducer('localhost:9092', key)
customer = {
'customer_id': 'CUST12345',
'email': 'john.doe@example.com',
'ssn': '123-45-6789',
'purchase_amount': 299.99,
'timestamp': '2025-03-15T10:30:00Z'
}
producer.send_customer_event(customer)- Schema Enforcement and Validation: Use schema registries to define and enforce which fields contain PII. Reject messages that include sensitive fields in contexts where they shouldn't appear. Implement schema evolution policies that require approval and documentation when adding PII fields to existing schemas. For comprehensive schema management patterns, see Schema Registry and Schema Management.
- Access Control and Topic Segregation: Implement fine-grained ACLs ensuring only authorized applications and users can access topics containing PII. Separate sensitive and non-sensitive data into different topics with distinct security policies. Use encryption at rest and in transit for all streams carrying personal data. For detailed access control implementation, see Access Control for Streaming.
- Data Classification and Tagging: Systematically classify data by sensitivity level and use Kafka headers or schema metadata to tag messages with classification information. This enables automated policy enforcement based on data sensitivity. For comprehensive classification strategies, see Data Classification and Tagging Strategies.
- Data Minimization: Design applications to avoid collecting, processing, or transmitting PII unless absolutely necessary. Aggregate data early in the pipeline, removing individual identifiers before downstream processing. Question whether each PII field truly needs to flow through the entire system or could be stripped at ingestion.
- Secure Logging Practices: Configure logging frameworks to automatically redact known PII patterns. Implement structured logging with explicit field-level control over what gets logged. Never log complete event payloads in production environments, log only specific fields required for debugging.
Real-Time Detection in Stream Processing
Stream processing applications must detect PII in real-time as data flows through the pipeline:
- Inline Scanning: Deploy scanning logic within stream processors using Kafka Streams, Flink, or Spark Streaming. Each message passes through PII detection functions that apply pattern matching and ML classification. Detected PII triggers immediate actions, masking, routing to quarantine topics (secure holding topics for investigation), or alerting security teams.
- Sidecar Processors: Run dedicated PII scanning applications that consume from all topics, continuously monitoring for leakage. A sidecar processor is a separate application that runs alongside your main stream processing pipeline, providing cross-cutting concerns like security scanning without modifying business logic. This approach separates security logic from business logic and allows centralized policy management. However, it doubles message processing and introduces detection latency.
- Schema Registry Integration: Validate messages against schemas annotated with PII metadata. Reject or quarantine messages that contain PII fields when connecting to topics or endpoints that shouldn't receive sensitive data.
- Modern Governance Platforms (2025): Advanced data governance platforms now provide comprehensive PII leakage prevention capabilities:
- Conduktor Gateway and Platform: Conduktor provides multiple layers of PII protection:
- Conduktor Gateway: Acts as a proxy between applications and Kafka brokers, enforcing PII masking policies in real-time without modifying application code. Gateway can apply different masking rules based on consumer identity, enabling a single topic to serve multiple teams with different data access levels.
- Real-time Data Masking: Define masking policies centrally that automatically apply to data streams:
# Conduktor Gateway PII masking configuration
interceptors:
- type: safeguard
config:
rules:
- name: mask-customer-pii
action: MASK
condition: topic == 'customer-events'
fields:
- path: $.email
algorithm: SHA256 # Hash emails
- path: $.ssn
algorithm: REDACT # Completely redact SSNs
- path: $.creditCard
algorithm: MASK_KEEP_LAST_4 # Keep last 4 digits
appliesTo:
- consumerGroup: analytics-team
- consumerGroup: ml-training
- name: detect-accidental-pii
action: BLOCK
condition: topic != 'customer-events' && message.contains('ssn')
alert: true- Audit Logs and PII Tracking: Conduktor Gateway's audit logs capture all producer/consumer connections, providing visibility into which applications interact with which topics and helping identify potential PII exposure points.
- Data Quality Rules: Define and enforce rules that detect unexpected PII in topics that shouldn't contain it:
# Data quality rule in Conduktor
quality_rules:
- name: no-pii-in-analytics
topic: analytics-events
severity: CRITICAL
condition: |
message.doesNotMatch('\\b\\d{3}-\\d{2}-\\d{4}\\b') && // No SSNs
message.doesNotMatch('[a-z0-9._%+-]+@[a-z0-9.-]+\\.[a-z]{2,}') // No emails
action: QUARANTINE
alert:
channels: [slack, pagerduty]Kafka 4.0+ with KRaft Mode: The removal of ZooKeeper in Kafka 4.0 brings improved audit capabilities that enhance PII leakage prevention:
- Enhanced Audit Logging: KRaft's metadata management provides more detailed audit trails, tracking who accessed PII-containing topics and when
- Faster ACL Enforcement: Improved authorization performance enables more granular, field-level access controls
- Centralized Metadata: Simplified architecture makes it easier to implement consistent PII protection policies across the entire cluster
For comprehensive policy enforcement patterns, see Policy Enforcement in Streaming.
Handling Detected PII: When PII is detected where it shouldn't exist:
- Quarantine: Route messages to secure holding topics for investigation
- Alert: Notify security teams immediately with details about the leakage vector
- Redact: Automatically mask detected PII before allowing further processing
- Audit: Log all detections for compliance reporting and trend analysis
Compliance and Regulatory Context
PII protection directly supports regulatory compliance:
- GDPR (General Data Protection Regulation): Requires organizations to implement appropriate technical measures to protect personal data. PII leakage prevention demonstrates "privacy by design" principles mandated by Article 25. Data breach notification requirements (Article 33) apply to unintended exposure, making detection speed critical, breaches must be reported within 72 hours of discovery.
- CCPA and CPRA (California Consumer Privacy Act, enhanced by California Privacy Rights Act of 2023): Mandates reasonable security procedures to protect personal information. The 2023 CPRA amendments strengthened enforcement, introducing the California Privacy Protection Agency with expanded audit powers. PII leakage into logs or third-party systems may violate consumer privacy rights, particularly the right to know what personal information is collected and shared. Organizations must implement risk assessments and automated decision-making safeguards.
- HIPAA (Health Insurance Portability and Accountability Act): Requires safeguards to protect Protected Health Information (PHI). Unintended exposure of PHI through logs, monitoring systems, or misconfigured streams constitutes a breach requiring notification and potential penalties. The 2025 updates to the HIPAA Security Rule emphasize real-time monitoring and automated controls for PHI in streaming systems.
- Documentation and Evidence: Compliance audits require demonstrating PII protection measures. Maintain documentation of detection mechanisms, prevention policies, scanning results, and incident responses. Regular reporting shows ongoing commitment to data protection.
Building a Comprehensive PII Protection Program
Effective PII protection requires organizational commitment:
- Establish PII Inventory and Classification: Document what PII exists in your systems, where it flows, and its sensitivity level. Create classification tiers (e.g., high-sensitivity for SSNs and credit cards, medium for names and emails) that determine protection requirements.
- Define Policies and Standards: Create clear policies specifying where PII can exist, how it must be protected, and who can access it. Standardize masking formats, encryption requirements, and access control patterns. Document exceptions and their approval processes.
- Implement Technical Controls: Deploy the detection and prevention technologies appropriate for your architecture. Start with pattern matching for high-risk PII like credit card numbers, expand to ML-based detection for contextual PII, and ultimately implement schema-driven protection for comprehensive coverage.
- Monitor and Alert: Create dashboards showing PII detection metrics, where leakage occurs, which applications are involved, and trending patterns. Set up alerts for unusual PII exposure volumes or new leakage vectors. Review alerts regularly and investigate all incidents.
- Training and Awareness: Educate developers about PII risks in streaming systems. Provide secure coding guidelines, logging best practices, and testing procedures. Make PII protection part of code review checklists and architecture review processes.
- Testing and Validation: Regularly test PII protection measures using synthetic data that mimics real PII. Attempt to deliberately leak test PII through various vectors to verify detection systems work correctly. Include PII protection testing in CI/CD pipelines.
- Incident Response: Prepare documented procedures for handling detected PII leakage, how to assess scope, who to notify, how to remediate, and what to document. Practice incident response through tabletop exercises.
Tools and Platforms for PII Detection
Modern streaming platforms provide PII protection capabilities across multiple categories:
Data Governance and Cataloging Platforms:
- Conduktor Platform: Comprehensive stream governance with PII detection, data quality rules, and real-time masking via Conduktor Gateway. Provides unified visibility across Kafka environments through audit logs and policy enforcement.
- OpenMetadata: Open-source data catalog with native Kafka integration, automated lineage tracking, and ML-based classification suggestions for identifying PII fields.
- DataHub (LinkedIn): Real-time metadata management with Kafka Connect integration, enabling classification propagation across streaming and batch systems.
Data Loss Prevention (DLP) Solutions:
- Enterprise DLP Platforms: Solutions like Symantec DLP, Forcepoint, and McAfee Total Protection can monitor streaming systems, applying pattern matching and ML detection to identify PII exposure in real-time. These integrate with SIEM platforms for comprehensive security monitoring.
- Cloud-Native DLP: AWS Macie (with MSK integration), Google Cloud DLP API, and Azure Purview provide managed PII detection that integrates directly with cloud streaming services.
Schema Registries and Management:
- Open-Source Schema Registries: Apache Schema Registry, AWS Glue Schema Registry, and Apicurio Registry support schema-level metadata for marking sensitive fields, enabling policy enforcement based on schema annotations.
- Schema Governance: Tools integrate with CI/CD pipelines to validate that schema changes don't accidentally introduce PII into topics that shouldn't contain it.
Stream Processing Frameworks:
- Apache Kafka Streams: Lightweight library for building inline PII detection and masking, running within application JVMs with minimal operational overhead.
- Apache Flink: Powerful stateful stream processing with advanced PII detection capabilities, including windowed aggregation for differential privacy and k-anonymity.
- Spark Streaming: Batch-oriented stream processing suitable for higher-latency PII scanning and profiling workloads.
AI-Powered Detection Services (2025):
- AWS Macie for Kafka: ML-powered PII detection integrated with Amazon MSK, supporting 150+ PII types across multiple languages and regions.
- Google Cloud DLP API: Real-time scanning API with customizable detection rules, callable from any stream processor with sub-100ms latency.
- Azure Purview with Event Hubs: Microsoft's data governance platform with automated PII classification for Azure streaming services.
- Microsoft Presidio (Open Source): Privacy-preserving PII detection and anonymization framework supporting 20+ languages, deployable as a microservice or library.
- AWS Pilar (Open Source): Privacy-preserving analytics framework with built-in PII detection, designed for streaming data analysis.
Monitoring and Observability:
- Data Quality Platforms: Tools like Great Expectations, Soda Core, and Monte Carlo can monitor for unexpected PII patterns in streams, alerting when sensitive data appears where it shouldn't. For detailed data quality implementation, see Building a Data Quality Framework.
- Audit Logging Systems: Comprehensive audit trails showing who accessed PII data, when, and what operations were performed. See Audit Logging for Streaming Platforms for implementation patterns.
Conclusion
PII leakage prevention requires vigilance, technical controls, and organizational commitment. By understanding leakage vectors, implementing detection approaches, and enforcing prevention policies, organizations protect personal data while maintaining compliance with data protection regulations. The investment in PII protection reduces breach risk, supports regulatory compliance, and builds customer trust.
Modern tools in 2025 — from AI-powered detection services to governance platforms like Conduktor — make PII protection more accessible and effective. Kafka 4.0+ with KRaft mode provides improved audit capabilities, while cloud AI services offer ML-based detection with minimal operational overhead.
Getting Started Checklist:
- Inventory PII: Identify what PII exists in your streaming systems and where it flows
- Start with high-risk data: Implement pattern matching for credit cards, SSNs, and other structured PII
- Add schema-level controls: Use schema registry to mark sensitive fields and enforce policies
- Deploy detection: Choose between inline scanning (Kafka Streams/Flink) or centralized scanning (Conduktor Gateway, sidecar processors)
- Implement masking: Add tokenization or encryption for sensitive fields before data reaches lower-security environments
- Monitor and alert: Set up dashboards and alerts for PII detection events
- Test regularly: Use synthetic PII to validate detection and prevention mechanisms
- Expand coverage: Gradually add ML-based detection for contextual PII and advanced anonymization techniques
Related Concepts
- PII Detection and Handling in Event Streams - Core techniques for detecting PII using pattern matching, ML classification, and schema-based approaches.
- Data Masking and Anonymization for Streaming - Implementation patterns for masking, tokenization, and anonymization to prevent PII leakage.
- Policy Enforcement in Streaming - Automated policy enforcement to detect and block PII leakage at zone boundaries.
Sources and References
- GDPR Official Text - Complete text of the General Data Protection Regulation including technical and organizational measures for data protection. https://gdpr-info.eu/
- NIST Privacy Framework - Comprehensive framework for managing privacy risks including PII identification and protection strategies. https://www.nist.gov/privacy-framework
- AWS Macie Documentation - Guide to automated PII discovery and classification in data streams and storage using machine learning. https://aws.amazon.com/macie/
- Google Cloud DLP API - Documentation on detecting and protecting sensitive data including PII using pattern matching and ML classification. https://cloud.google.com/dlp
- OWASP Top 10 Privacy Risks - Industry-standard reference for understanding and mitigating privacy risks in software applications. https://owasp.org/www-project-top-10-privacy-risks/