Time Travel with Apache Iceberg
Apache Iceberg's time travel feature lets you query your data as it appeared at any point in the past. This changes how data teams approach debugging, auditing, and compliance by providing a complete historical view of table evolution without maintaining separate backup copies. For a comprehensive overview of Iceberg's architecture and capabilities, see Apache Iceberg. 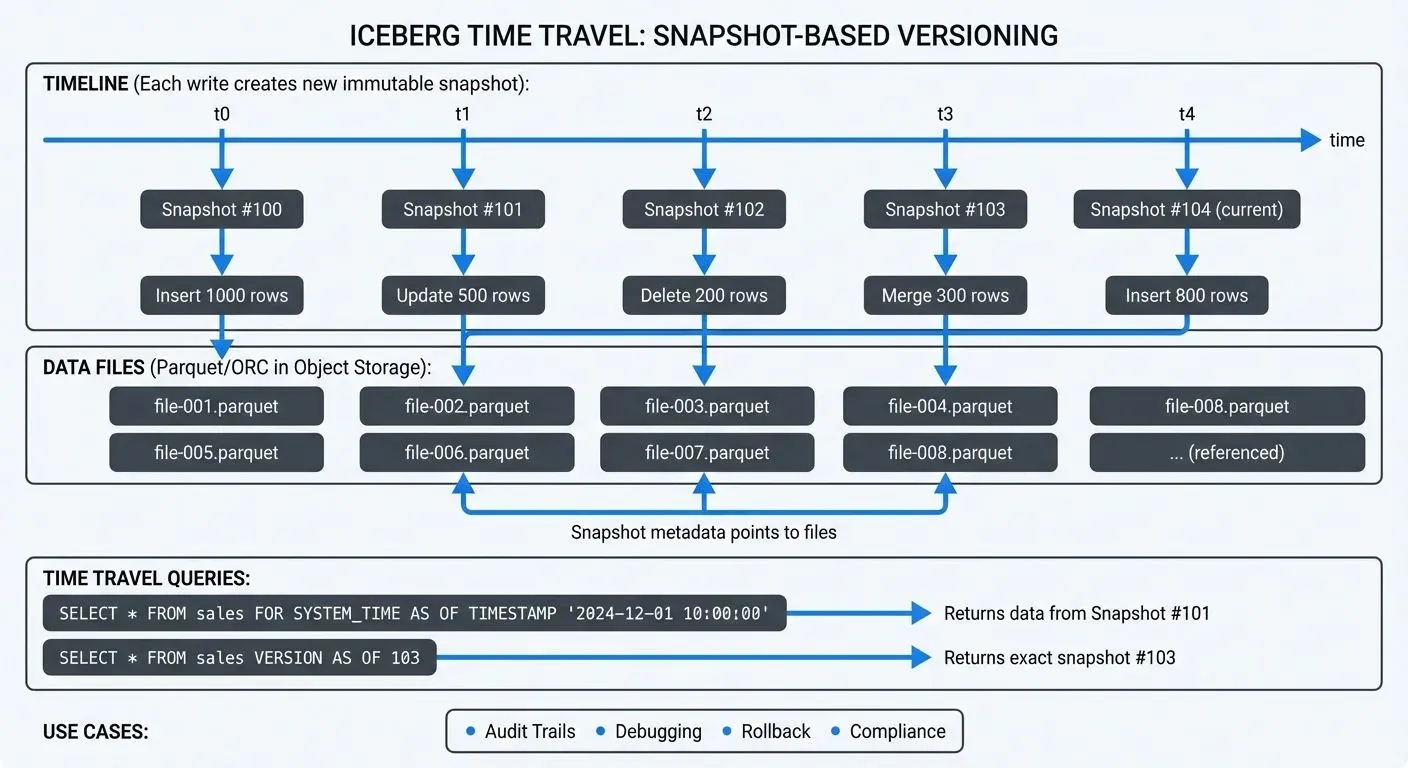
Understanding Iceberg Snapshots
At the core of Iceberg's time travel functionality is its snapshot-based architecture. Every write operation, whether insert, update, delete, or merge, creates a new immutable snapshot of the table. Each snapshot represents a complete, consistent view of the table at that moment in time. This is conceptually similar to version control systems like Git, where each commit creates an immutable reference to the repository state.
Unlike traditional data lakes where historical data requires manual versioning or external backup systems, Iceberg maintains this history automatically through its metadata layer. Each snapshot contains:
- A unique snapshot ID
- Timestamp of creation
- Schema at that point in time
- Complete list of data files
- Summary statistics and metadata
This metadata-driven approach means time travel queries don't duplicate data files. Instead, they reference the same underlying Parquet or ORC files that were valid at the queried point in time, making historical queries storage-efficient.
Time Travel Query Syntax
Iceberg supports time travel through multiple query patterns, giving you flexibility in how you specify which historical version to access.
Query by Timestamp
The most intuitive approach is querying data as it existed at a specific timestamp:
-- View data as of a specific date and time
SELECT * FROM sales_data
FOR SYSTEM_TIME AS OF TIMESTAMP '2024-12-01 10:30:00';
-- Alternative syntax (engine-specific, check documentation)
SELECT * FROM sales_data
TIMESTAMP AS OF '2024-12-01 10:30:00';Both syntaxes are functionally equivalent when supported. The FOR SYSTEM_TIME AS OF syntax follows the SQL standard and has broader engine support, while some engines like Spark also support the shorter TIMESTAMP AS OF variant for convenience.
This syntax works across multiple query engines including Apache Spark 3.5+, Trino 440+, and Dremio 24+. The query returns results using the snapshot that was current at the specified timestamp. Note that exact syntax support may vary slightly between engines; always consult your query engine's Iceberg documentation for the most current compatibility details.
Query by Snapshot ID
For precise control, you can query a specific snapshot directly:
-- Query using explicit snapshot ID
SELECT * FROM sales_data
FOR SYSTEM_VERSION AS OF 8234567890123456789;
-- Useful for reproducing exact results
SELECT * FROM sales_data
VERSION AS OF 8234567890123456789;This approach is particularly valuable when you need to reproduce exact query results for compliance or debugging, as snapshot IDs never change.
Inspecting Available Snapshots
Before time traveling, you often want to see what snapshots are available:
-- View all snapshots for a table
SELECT * FROM prod_db.sales_data.snapshots
ORDER BY committed_at DESC;
-- See snapshot details including operation type
SELECT
snapshot_id,
committed_at,
operation,
summary
FROM prod_db.sales_data.snapshots;Practical Use Cases for Time Travel
Time travel capabilities unlock several critical data engineering workflows that would otherwise require complex custom solutions.
Audit and Compliance
Financial services and healthcare organizations face strict requirements to explain exactly what data was visible at any point in time. With Iceberg time travel, compliance queries become straightforward. This complements Change Data Capture (CDC) strategies by providing queryable history without maintaining separate audit tables. For CDC implementation patterns, see What is Change Data Capture (CDC) Fundamentals.
-- Reproduce quarterly report exactly as generated
SELECT
region,
SUM(revenue) AS total_revenue
FROM financial_transactions
FOR SYSTEM_TIME AS OF TIMESTAMP '2024-09-30 23:59:59'
GROUP BY region;This eliminates the need to maintain separate archive databases or backup tables, reducing storage costs and operational complexity.
Debugging and Root Cause Analysis
When data quality issues arise, time travel lets you pinpoint exactly when incorrect data entered the system. This complements modern data quality frameworks by providing historical context for validation failures. For comprehensive testing strategies, see Great Expectations Data Testing Framework.
-- Compare current data with yesterday's snapshot
WITH CURRENT AS (
SELECT customer_id, balance FROM accounts
),
yesterday AS (
SELECT customer_id, balance FROM accounts
FOR SYSTEM_TIME AS OF CURRENT_TIMESTAMP - INTERVAL '1' DAY
)
SELECT
c.customer_id,
c.balance AS current_balance,
y.balance AS yesterday_balance,
c.balance - y.balance AS change
FROM CURRENT c
JOIN yesterday y ON c.customer_id = y.customer_id
WHERE ABS(c.balance - y.balance) > 10000;This query identifies accounts with significant balance changes in the last 24 hours, helping quickly isolate data pipeline issues. For systematic approaches to incident response, see Data Incident Management and Root Cause Analysis.
Data Recovery and Rollback
Accidental deletes or incorrect updates can be recovered without restoring from backups:
-- Restore table to previous snapshot
CALL prod_db.system.rollback_to_snapshot('sales_data', 8234567890123456789);
-- Or restore to a timestamp
CALL prod_db.system.rollback_to_timestamp('sales_data', TIMESTAMP '2024-12-01 10:00:00');This rollback capability provides a safety net for production data pipelines, allowing quick recovery from mistakes.
Streaming Ecosystem Integration
Iceberg's time travel works with streaming platforms, enabling real-time analytics with historical context. For foundational understanding of streaming architectures, see Apache Kafka.
Apache Kafka and Flink Integration
When ingesting data from Kafka into Iceberg tables via Apache Flink (1.18+), each checkpoint or commit interval creates a new snapshot. This allows you to correlate streaming data with specific Kafka offsets and timestamps:
-- Query data as it arrived from Kafka stream
SELECT * FROM events_table
FOR SYSTEM_TIME AS OF TIMESTAMP '2024-12-07 14:30:00'
WHERE event_type = 'purchase';As of 2025, the Flink Iceberg connector supports several advanced features that enhance time travel capabilities:
- Automatic snapshot creation: Configure snapshot commit frequency via
write.target-file-size-bytesandwrite.distribution-modeto balance snapshot granularity with metadata overhead - Kafka offset tracking: The connector stores Kafka offsets and timestamps in Iceberg commit metadata, enabling precise correlation between stream position and table snapshots
- Incremental reads: Use time travel to implement incremental processing patterns, reading only data written since the last checkpoint
For Kafka Connect users, the Iceberg sink connector provides similar snapshot-per-commit behavior, making time travel equally powerful for no-code ingestion pipelines.
This capability is crucial for debugging streaming pipelines, as you can examine exactly what data was written during a specific time window and trace issues back to their source Kafka messages. For detailed implementation guidance, see What is Apache Flink: Stateful Stream Processing.
Streaming Governance Integration
For organizations running complex streaming infrastructures, governance platforms provide visibility into data lineage and schema evolution. When combined with Iceberg's time travel, these tools enable useful operational and compliance capabilities:
- Topic-to-snapshot tracking: Correlate which Kafka topics and offset ranges feed into specific Iceberg snapshots
- Schema evolution monitoring: Track schema changes across snapshots and correlate with streaming pipeline deployments
- Compliance auditing: Record access patterns to historical data for regulatory requirements
- Data freshness visualization: Monitor snapshot creation frequency and identify pipeline delays
Platforms like Conduktor offer comprehensive governance for Kafka ecosystems, including audit logging of all client connections, schema registry management, and access control enforcement. Conduktor Gateway, a Kafka proxy, captures which producers and consumers connect to which topics, providing observability into data flow — though full automated lineage across the pipeline requires dedicated lineage tools. When combined with Iceberg's time travel capabilities, this audit trail helps trace source events through to analytical queries. For audit requirements, see Audit Logging for Streaming Platforms.
Snapshot Retention and Management
While time travel is powerful, unbounded snapshot retention can lead to metadata bloat and storage costs. Iceberg provides configurable retention policies to balance history preservation with resource efficiency.
Configuring Retention
-- Set retention to 7 days of snapshot history
ALTER TABLE sales_data SET TBLPROPERTIES (
'history.expire.max-snapshot-age-ms' = '604800000'
);
-- Manually expire old snapshots
CALL prod_db.system.expire_snapshots(
TABLE => 'sales_data',
older_than => TIMESTAMP '2024-11-01 00:00:00',
retain_last => 100
);The retain_last parameter ensures you always keep a minimum number of recent snapshots, even if they fall outside the time window.
Best Practices
- Development tables: Short retention (1-3 days) to minimize metadata overhead
- Production analytics: Medium retention (30-90 days) for debugging and auditing
- Compliance-critical tables: Extended retention (1+ years) or permanent archival of specific snapshots
- High-frequency updates: Consider longer intervals between snapshots to reduce metadata volume
Advanced Time Travel Features in 2025
Recent Iceberg releases (1.5+) have introduced several enhancements that make time travel more efficient and powerful:
Deletion Vectors for Faster Historical Queries
Iceberg 1.5 introduced deletion vectors as an alternative to traditional copy-on-write for delete operations. When querying historical snapshots, the query engine can efficiently skip deleted rows without rewriting entire data files:
-- Configure deletion vectors for faster deletes
ALTER TABLE events_table SET TBLPROPERTIES (
'write.delete.mode' = 'merge-on-read',
'write.update.mode' = 'merge-on-read'
);This significantly improves performance for tables with frequent deletes, as time travel queries can read historical snapshots without processing unnecessary data file copies.
Metadata Column Optimization
Iceberg now exposes metadata columns that make time travel queries more efficient:
-- Find all snapshots that modified specific partitions
SELECT DISTINCT _iceberg_snapshot_id, _iceberg_file_path
FROM events_table
WHERE event_date = '2024-12-01'
AND _iceberg_snapshot_id > 8234567890123456789;These metadata columns (_iceberg_snapshot_id, _iceberg_file_path, _iceberg_committed_at) enable precise snapshot-aware queries without scanning table metadata.
REST Catalog and Multi-Version Access
Modern Iceberg deployments increasingly use REST catalogs (supported by AWS Glue, Tabular, Nessie, and others) which provide enhanced snapshot management capabilities:
- Atomic multi-table time travel: Query consistent snapshots across multiple related tables
- Branching and tagging: Create named references to specific snapshots for reproducible analytics
- Distributed snapshot expiration: Coordinate retention policies across data lake zones
For teams building lakehouse architectures with multiple Iceberg tables, REST catalogs ensure time travel queries maintain referential integrity across table relationships. For broader lakehouse context, see Introduction to Lakehouse Architecture.
Related Concepts
- What is Change Data Capture: CDC Fundamentals
- Data Lineage: Tracking Data from Source to Consumption
- Real-Time Analytics with Streaming Data
Summary
Apache Iceberg's time travel feature provides a solid foundation for querying historical data without the complexity of manual versioning systems. Built on immutable snapshots, Iceberg enables:
- Point-in-time queries for compliance and audit reporting
- Historical data comparison for debugging
- Snapshot rollback for data recovery
- Integration with streaming platforms like Kafka and Flink
- Storage-efficient historical access through metadata-driven architecture
- 2025 features including deletion vectors, metadata column optimization, and REST catalog support
Flexible query syntax (timestamp and snapshot-based), automatic snapshot management, and configurable retention policies make Iceberg's time travel suitable for use cases ranging from development experimentation to regulatory compliance. For related data versioning patterns, see Data Versioning in Streaming.